We also train the reward model based on LLaMA-7B, which reaches the ACC of 72.06% after 1 epoch, performing almost the same as Anthropic's best RM.
-
-### Arg List
-
-- `--strategy`: the strategy using for training, choices=['ddp', 'colossalai_gemini', 'colossalai_zero2'], default='colossalai_zero2'
-- `--model`: model type, choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom'
-- `--pretrain`: pretrain model, type=str, default=None
-- `--model_path`: the path of rm model(if continue to train), type=str, default=None
-- `--save_path`: path to save the model, type=str, default='output'
-- `--need_optim_ckpt`: whether to save optim ckpt, type=bool, default=False
-- `--max_epochs`: max epochs for training, type=int, default=3
-- `--dataset`: dataset name, type=str, choices=['Anthropic/hh-rlhf', 'Dahoas/rm-static']
-- `--subset`: subset of the dataset, type=str, default=None
-- `--batch_size`: batch size while training, type=int, default=4
-- `--lora_rank`: low-rank adaptation matrices rank, type=int, default=0
-- `--loss_func`: which kind of loss function, choices=['log_sig', 'log_exp']
-- `--max_len`: max sentence length for generation, type=int, default=512
-
-## Stage3 - Training model using prompts with RL
-
-Stage3 uses reinforcement learning algorithm, which is the most complex part of the training process, as shown below:
-
-
-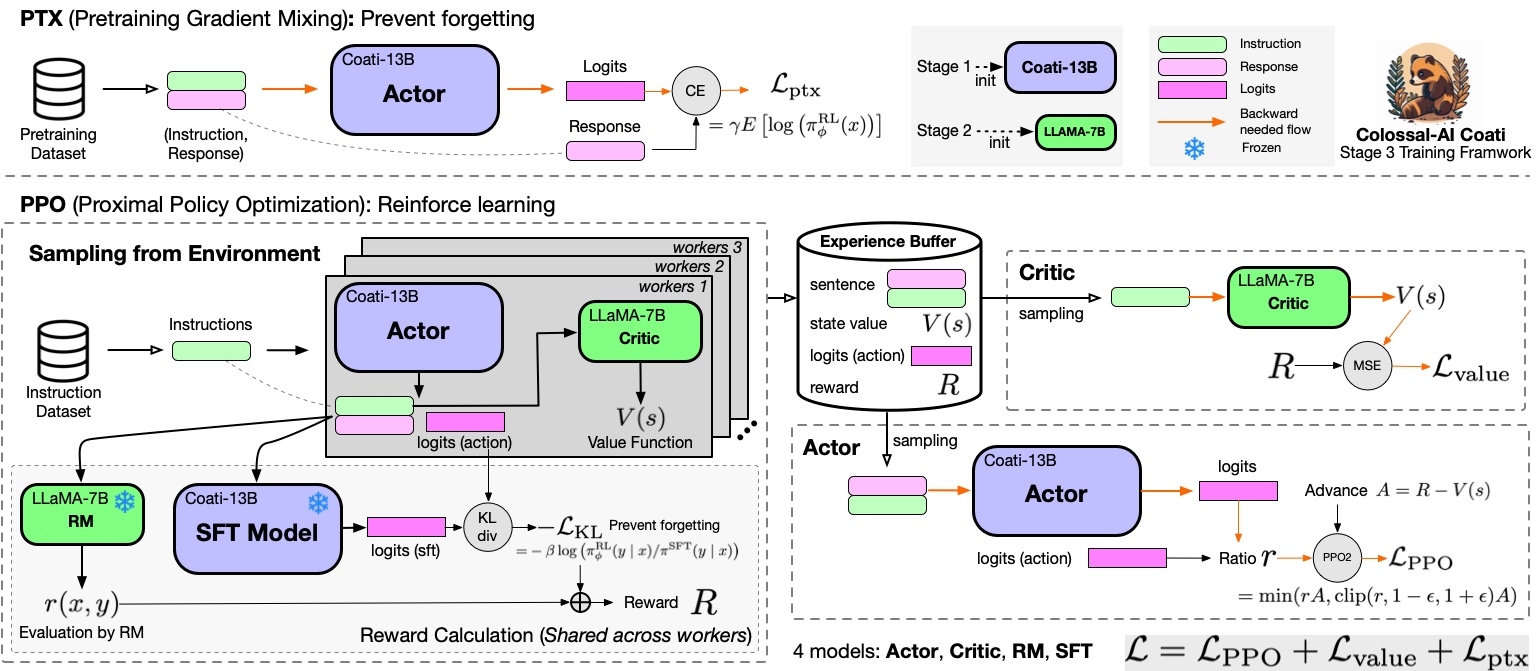 -
-
-
-You can run the `examples/train_prompts.sh` to start PPO training.
-
-You can also use the cmd following to start PPO training.
-[[Stage3 tutorial video]](https://www.youtube.com/watch?v=Z8wwSHxPL9g)
-
-```bash
-torchrun --standalone --nproc_per_node=4 train_prompts.py \
- --pretrain "/path/to/LLaMa-7B/" \
- --model 'llama' \
- --strategy colossalai_zero2 \
- --prompt_dataset /path/to/your/prompt_dataset \
- --pretrain_dataset /path/to/your/pretrain_dataset \
- --rm_pretrain /your/pretrain/rm/definition \
- --rm_path /your/rm/model/path
-```
-
-Prompt dataset: the instruction dataset mentioned in the above figure which includes the instructions, e.g. you can use the [script](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/generate_prompt_dataset.py) which samples `instinwild_en.json` or `instinwild_ch.json` in [InstructionWild](https://github.com/XueFuzhao/InstructionWild/tree/main/data#instructwild-data) to generate the prompt dataset.
-Pretrain dataset: the pretrain dataset including the instruction and corresponding response, e.g. you can use the [InstructWild Data](https://github.com/XueFuzhao/InstructionWild/tree/main/data) in stage 1 supervised instructs tuning.
-
-**Note**: the required datasets follow the following format,
-
-- `pretrain dataset`
-
- ```json
- [
- {
- "instruction": "Provide a list of the top 10 most popular mobile games in Asia",
- "input": "",
- "output": "The top 10 most popular mobile games in Asia are:\n1) PUBG Mobile\n2) Pokemon Go\n3) Candy Crush Saga\n4) Free Fire\n5) Clash of Clans\n6) Mario Kart Tour\n7) Arena of Valor\n8) Fantasy Westward Journey\n9) Subway Surfers\n10) ARK Survival Evolved",
- "id": 0
- },
- ...
- ]
- ```
-
-- `prompt dataset`
-
- ```json
- [
- {
- "instruction": "Edit this paragraph to make it more concise: \"Yesterday, I went to the store and bought some things. Then, I came home and put them away. After that, I went for a walk and met some friends.\"",
- "id": 0
- },
- {
- "instruction": "Write a descriptive paragraph about a memorable vacation you went on",
- "id": 1
- },
- ...
- ]
- ```
-
-### Arg List
-
-- `--strategy`: the strategy using for training, choices=['ddp', 'colossalai_gemini', 'colossalai_zero2'], default='colossalai_zero2'
-- `--model`: model type of actor, choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom'
-- `--pretrain`: pretrain model, type=str, default=None
-- `--rm_model`: reward model type, type=str, choices=['gpt2', 'bloom', 'opt', 'llama'], default=None
-- `--rm_pretrain`: pretrain model for reward model, type=str, default=None
-- `--rm_path`: the path of rm model, type=str, default=None
-- `--save_path`: path to save the model, type=str, default='output'
-- `--prompt_dataset`: path of the prompt dataset, type=str, default=None
-- `--pretrain_dataset`: path of the ptx dataset, type=str, default=None
-- `--need_optim_ckpt`: whether to save optim ckpt, type=bool, default=False
-- `--num_episodes`: num of episodes for training, type=int, default=10
-- `--num_update_steps`: number of steps to update policy per episode, type=int
-- `--num_collect_steps`: number of steps to collect experience per episode, type=int
-- `--train_batch_size`: batch size while training, type=int, default=8
-- `--ptx_batch_size`: batch size to compute ptx loss, type=int, default=1
-- `--experience_batch_size`: batch size to make experience, type=int, default=8
-- `--lora_rank`: low-rank adaptation matrices rank, type=int, default=0
-- `--kl_coef`: kl_coef using for computing reward, type=float, default=0.1
-- `--ptx_coef`: ptx_coef using for computing policy loss, type=float, default=0.9
-
-## Inference example - After Stage3
-
-We support different inference options, including int8 and int4 quantization.
-For details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
-
-## Attention
-
-The examples are demos for the whole training process.You need to change the hyper-parameters to reach great performance.
-
-#### data
-
-- [x] [rm-static](https://huggingface.co/datasets/Dahoas/rm-static)
-- [x] [hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf)
-- [ ] [openai/summarize_from_feedback](https://huggingface.co/datasets/openai/summarize_from_feedback)
-- [ ] [openai/webgpt_comparisons](https://huggingface.co/datasets/openai/webgpt_comparisons)
-- [ ] [Dahoas/instruct-synthetic-prompt-responses](https://huggingface.co/datasets/Dahoas/instruct-synthetic-prompt-responses)
-
-## Support Model
-
-### GPT
-
-- [x] GPT2-S (s)
-- [x] GPT2-M (m)
-- [x] GPT2-L (l)
-- [x] GPT2-XL (xl)
-- [x] GPT2-4B (4b)
-- [ ] GPT2-6B (6b)
-
-### BLOOM
-
-- [x] [BLOOM-560m](https://huggingface.co/bigscience/bloom-560m)
-- [x] [BLOOM-1b1](https://huggingface.co/bigscience/bloom-1b1)
-- [x] [BLOOM-3b](https://huggingface.co/bigscience/bloom-3b)
-- [x] [BLOOM-7b](https://huggingface.co/bigscience/bloom-7b1)
-- [ ] [BLOOM-175b](https://huggingface.co/bigscience/bloom)
-
-### OPT
-
-- [x] [OPT-125M](https://huggingface.co/facebook/opt-125m)
-- [x] [OPT-350M](https://huggingface.co/facebook/opt-350m)
-- [x] [OPT-1.3B](https://huggingface.co/facebook/opt-1.3b)
-- [x] [OPT-2.7B](https://huggingface.co/facebook/opt-2.7b)
-- [x] [OPT-6.7B](https://huggingface.co/facebook/opt-6.7b)
-- [ ] [OPT-13B](https://huggingface.co/facebook/opt-13b)
-- [ ] [OPT-30B](https://huggingface.co/facebook/opt-30b)
-
-### [LLaMA](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md)
-
-- [x] LLaMA-7B
-- [x] LLaMA-13B
-- [ ] LLaMA-33B
-- [ ] LLaMA-65B
-
-## Add your own models
-
-If you want to support your own model in Coati, please refer the pull request for RoBERTa support as an example --[[chatgpt] add pre-trained model RoBERTa for RLHF stage 2 & 3](https://github.com/hpcaitech/ColossalAI/pull/3223), and submit a PR to us.
-
-You should complete the implementation of four model classes, including Reward model, Critic model, LM model, Actor model
-
-here are some example code for a NewModel named `Coati`.
-if it is supported in huggingface [transformers](https://github.com/huggingface/transformers), you can load it by `from_pretrained`, o
-r you can build your own model by yourself.
-
-### Actor model
-
-```python
-from ..base import Actor
-from transformers.models.coati import CoatiModel
-
-class CoatiActor(Actor):
- def __init__(self,
- pretrained: Optional[str] = None,
- checkpoint: bool = False,
- lora_rank: int = 0,
- lora_train_bias: str = 'none') -> None:
- if pretrained is not None:
- model = CoatiModel.from_pretrained(pretrained)
- else:
- model = build_model() # load your own model if it is not support in transformers
-
- super().__init__(model, lora_rank, lora_train_bias)
-```
-
-### Reward model
-
-```python
-from ..base import RewardModel
-from transformers.models.coati import CoatiModel
-
-class CoatiRM(RewardModel):
-
- def __init__(self,
- pretrained: Optional[str] = None,
- checkpoint: bool = False,
- lora_rank: int = 0,
- lora_train_bias: str = 'none') -> None:
- if pretrained is not None:
- model = CoatiModel.from_pretrained(pretrained)
- else:
- model = build_model() # load your own model if it is not support in transformers
-
- value_head = nn.Linear(model.config.n_embd, 1)
- value_head.weight.data.normal_(mean=0.0, std=1 / (model.config.n_embd + 1))
- super().__init__(model, value_head, lora_rank, lora_train_bias)
-```
-
-### Critic model
-
-```python
-from ..base import Critic
-from transformers.models.coati import CoatiModel
-
-class CoatiCritic(Critic):
- def __init__(self,
- pretrained: Optional[str] = None,
- checkpoint: bool = False,
- lora_rank: int = 0,
- lora_train_bias: str = 'none') -> None:
- if pretrained is not None:
- model = CoatiModel.from_pretrained(pretrained)
- else:
- model = build_model() # load your own model if it is not support in transformers
-
- value_head = nn.Linear(model.config.n_embd, 1)
- value_head.weight.data.normal_(mean=0.0, std=1 / (model.config.n_embd + 1))
- super().__init__(model, value_head, lora_rank, lora_train_bias)
-```
diff --git a/applications/Chat/examples/download_model.py b/applications/Chat/examples/download_model.py
deleted file mode 100644
index ec3482b5f789..000000000000
--- a/applications/Chat/examples/download_model.py
+++ /dev/null
@@ -1,79 +0,0 @@
-import argparse
-import dataclasses
-import os
-import parser
-from typing import List
-
-import tqdm
-from coati.models.bloom import BLOOMRM, BLOOMActor, BLOOMCritic
-from coati.models.gpt import GPTRM, GPTActor, GPTCritic
-from coati.models.opt import OPTRM, OPTActor, OPTCritic
-from huggingface_hub import hf_hub_download, snapshot_download
-from transformers import AutoConfig, AutoTokenizer, BloomConfig, BloomTokenizerFast, GPT2Config, GPT2Tokenizer
-
-
-@dataclasses.dataclass
-class HFRepoFiles:
- repo_id: str
- files: List[str]
-
- def download(self, dir_path: str):
- for file in self.files:
- file_path = hf_hub_download(self.repo_id, file, local_dir=dir_path)
-
- def download_all(self):
- snapshot_download(self.repo_id)
-
-
-def test_init(model: str, dir_path: str):
- if model == "gpt2":
- config = GPT2Config.from_pretrained(dir_path)
- actor = GPTActor(config=config)
- critic = GPTCritic(config=config)
- reward_model = GPTRM(config=config)
- GPT2Tokenizer.from_pretrained(dir_path)
- elif model == "bloom":
- config = BloomConfig.from_pretrained(dir_path)
- actor = BLOOMActor(config=config)
- critic = BLOOMCritic(config=config)
- reward_model = BLOOMRM(config=config)
- BloomTokenizerFast.from_pretrained(dir_path)
- elif model == "opt":
- config = AutoConfig.from_pretrained(dir_path)
- actor = OPTActor(config=config)
- critic = OPTCritic(config=config)
- reward_model = OPTRM(config=config)
- AutoTokenizer.from_pretrained(dir_path)
- else:
- raise NotImplementedError(f"Model {model} not implemented")
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument("--model-dir", type=str, default="test_models")
- parser.add_argument("--config-only", default=False, action="store_true")
- args = parser.parse_args()
-
- if os.path.exists(args.model_dir):
- print(f"[INFO]: {args.model_dir} already exists")
- exit(0)
-
- repo_list = {
- "gpt2": HFRepoFiles(repo_id="gpt2", files=["config.json", "tokenizer.json", "vocab.json", "merges.txt"]),
- "bloom": HFRepoFiles(
- repo_id="bigscience/bloom-560m", files=["config.json", "tokenizer.json", "tokenizer_config.json"]
- ),
- "opt": HFRepoFiles(
- repo_id="facebook/opt-350m", files=["config.json", "tokenizer_config.json", "vocab.json", "merges.txt"]
- ),
- }
-
- os.mkdir(args.model_dir)
- for model_name in tqdm.tqdm(repo_list):
- dir_path = os.path.join(args.model_dir, model_name)
- if args.config_only:
- os.mkdir(dir_path)
- repo_list[model_name].download(dir_path)
- else:
- repo_list[model_name].download_all()
- test_init(model_name, dir_path)
diff --git a/applications/Chat/examples/generate_conversation_dataset.py b/applications/Chat/examples/generate_conversation_dataset.py
deleted file mode 100644
index 7e03b2d54260..000000000000
--- a/applications/Chat/examples/generate_conversation_dataset.py
+++ /dev/null
@@ -1,82 +0,0 @@
-import argparse
-import json
-
-from datasets import load_dataset
-
-
-def generate_alpaca():
- # We can convert dataset with the same format("instruction", "input", "output") as Alpaca into a one-round conversation.
- conversation_dataset = []
- dataset = load_dataset("tatsu-lab/alpaca", split="train")
-
- instructions = dataset["instruction"]
- inputs = dataset["input"]
- outputs = dataset["output"]
-
- assert len(instructions) == len(inputs) == len(outputs)
-
- for idx in range(len(instructions)):
- human_utterance = instructions[idx] + "\n\n" + inputs[idx] if inputs[idx] else instructions[idx]
- human = {"from": "human", "value": human_utterance}
-
- gpt_utterance = outputs[idx]
- gpt = {"from": "gpt", "value": gpt_utterance}
-
- conversation = dict(type="instruction", language="English", dataset="Alpaca", conversations=[human, gpt])
- conversation_dataset.append(conversation)
-
- return conversation_dataset
-
-
-def generate_sharegpt():
- # ShareGPT data requires less processing.
- conversation_dataset = []
- dataset = load_dataset(
- "anon8231489123/ShareGPT_Vicuna_unfiltered",
- data_files="ShareGPT_V3_unfiltered_cleaned_split_no_imsorry.json",
- split="train",
- )
-
- conversations = dataset["conversations"]
-
- for idx in range(len(conversations)):
- for conv in conversations[idx]:
- # We don't need markdown and text value.
- del conv["markdown"]
- del conv["text"]
-
- conversation = dict(
- type="conversation", language="Multilingual", dataset="ShareGPT", conversations=conversations[idx]
- )
- conversation_dataset.append(conversation)
-
- return conversation_dataset
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--dataset",
- type=str,
- default="All",
- choices=["Alpaca", "ShareGPT", "All"],
- help="which dataset to convert, All will combine Alpaca and ShareGPT",
- )
- parser.add_argument("--save_path", type=str, default="dataset.json", help="path to save the converted dataset")
- args = parser.parse_args()
-
- conversation_dataset = []
-
- if args.dataset == "Alpaca":
- conversation_dataset.extend(generate_alpaca())
- elif args.dataset == "ShareGPT":
- conversation_dataset.extend(generate_sharegpt())
- else:
- conversation_dataset.extend(generate_alpaca())
- conversation_dataset.extend(generate_sharegpt())
-
- for idx, sample in enumerate(conversation_dataset):
- sample["id"] = idx + 1
-
- with open(args.save_path, mode="w") as f:
- json.dump(conversation_dataset, f, indent=4, default=str, ensure_ascii=False)
diff --git a/applications/Chat/examples/generate_prompt_dataset.py b/applications/Chat/examples/generate_prompt_dataset.py
deleted file mode 100644
index 4eec6feae505..000000000000
--- a/applications/Chat/examples/generate_prompt_dataset.py
+++ /dev/null
@@ -1,27 +0,0 @@
-import argparse
-import json
-import random
-
-random.seed(42)
-
-
-def sample(args):
- with open(args.dataset_path, mode="r") as f:
- dataset_list = json.load(f)
-
- sampled_dataset = [
- {"instruction": sample["instruction"], "id": idx}
- for idx, sample in enumerate(random.sample(dataset_list, args.sample_size))
- ]
-
- with open(args.save_path, mode="w") as f:
- json.dump(sampled_dataset, f, indent=4, default=str, ensure_ascii=False)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument("--dataset_path", type=str, default=None, required=True, help="path to the pretrain dataset")
- parser.add_argument("--save_path", type=str, default="prompt.json", help="path to save the prompt dataset")
- parser.add_argument("--sample_size", type=int, default=16384, help="size of the prompt dataset")
- args = parser.parse_args()
- sample(args)
diff --git a/applications/Chat/examples/inference.py b/applications/Chat/examples/inference.py
deleted file mode 100644
index 62e06bf7b3bb..000000000000
--- a/applications/Chat/examples/inference.py
+++ /dev/null
@@ -1,73 +0,0 @@
-import argparse
-
-import torch
-from coati.models.bloom import BLOOMActor
-from coati.models.generation import generate
-from coati.models.gpt import GPTActor
-from coati.models.llama import LlamaActor
-from coati.models.opt import OPTActor
-from transformers import AutoTokenizer, BloomTokenizerFast, GPT2Tokenizer, LlamaTokenizer
-
-
-def eval(args):
- # configure model
- if args.model == "gpt2":
- actor = GPTActor(pretrained=args.pretrain)
- elif args.model == "bloom":
- actor = BLOOMActor(pretrained=args.pretrain)
- elif args.model == "opt":
- actor = OPTActor(pretrained=args.pretrain)
- elif args.model == "llama":
- actor = LlamaActor(pretrained=args.pretrain)
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
-
- actor.to(torch.cuda.current_device())
- if args.model_path is not None:
- state_dict = torch.load(args.model_path)
- actor.load_state_dict(state_dict)
-
- # configure tokenizer
- if args.model == "gpt2":
- tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == "bloom":
- tokenizer = BloomTokenizerFast.from_pretrained("bigscience/bloom-560m")
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == "opt":
- tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == "llama":
- tokenizer = LlamaTokenizer.from_pretrained("hf-internal-testing/llama-tokenizer")
- tokenizer.eos_token = "<\s>"
- tokenizer.pad_token = tokenizer.unk_token
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
-
- actor.eval()
- tokenizer.padding_side = "left"
- input_ids = tokenizer.encode(args.input, return_tensors="pt").to(torch.cuda.current_device())
- outputs = generate(
- actor,
- input_ids,
- tokenizer=tokenizer,
- max_length=args.max_length,
- do_sample=True,
- top_k=50,
- top_p=0.95,
- num_return_sequences=1,
- )
- output = tokenizer.batch_decode(outputs[0], skip_special_tokens=True)
- print(f"[Output]: {''.join(output)}")
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument("--model", default="gpt2", choices=["gpt2", "bloom", "opt", "llama"])
- # We suggest to use the pretrained model from HuggingFace, use pretrain to configure model
- parser.add_argument("--pretrain", type=str, default=None)
- parser.add_argument("--model_path", type=str, default=None)
- parser.add_argument("--input", type=str, default="Question: How are you ? Answer:")
- parser.add_argument("--max_length", type=int, default=100)
- args = parser.parse_args()
- eval(args)
diff --git a/applications/Chat/examples/train_prompts.py b/applications/Chat/examples/train_prompts.py
deleted file mode 100644
index 8868e278d85e..000000000000
--- a/applications/Chat/examples/train_prompts.py
+++ /dev/null
@@ -1,249 +0,0 @@
-import argparse
-import warnings
-
-import torch
-import torch.distributed as dist
-from coati.dataset import PromptDataset, SupervisedDataset
-from coati.models.bloom import BLOOMRM, BLOOMActor, BLOOMCritic
-from coati.models.gpt import GPTRM, GPTActor, GPTCritic
-from coati.models.llama import LlamaActor, LlamaCritic, LlamaRM
-from coati.models.opt import OPTRM, OPTActor, OPTCritic
-from coati.trainer import PPOTrainer
-from coati.trainer.strategies import DDPStrategy, GeminiStrategy, LowLevelZeroStrategy
-from torch.optim import Adam
-from torch.utils.data import DataLoader
-from torch.utils.data.distributed import DistributedSampler
-from transformers import AutoTokenizer, BloomTokenizerFast, GPT2Tokenizer, LlamaTokenizer
-
-from colossalai.nn.optimizer import HybridAdam
-
-
-def main(args):
- # configure strategy
- if args.strategy == "ddp":
- strategy = DDPStrategy()
- elif args.strategy == "colossalai_gemini":
- strategy = GeminiStrategy(placement_policy="static", initial_scale=2**5)
- elif args.strategy == "colossalai_zero2":
- strategy = LowLevelZeroStrategy(stage=2, placement_policy="cuda")
- else:
- raise ValueError(f'Unsupported strategy "{args.strategy}"')
-
- if args.rm_path is not None:
- warnings.warn("LoRA weights should be merged with the model weights")
- state_dict = torch.load(args.rm_path, map_location="cpu")
-
- if args.lora_rank > 0:
- warnings.warn("Lora is not supported yet.")
- args.lora_rank = 0
-
- with strategy.model_init_context():
- # configure model
- if args.model == "gpt2":
- initial_model = GPTActor(pretrained=args.pretrain)
- elif args.model == "bloom":
- initial_model = BLOOMActor(pretrained=args.pretrain)
- elif args.model == "opt":
- initial_model = OPTActor(pretrained=args.pretrain)
- elif args.model == "llama":
- initial_model = LlamaActor(pretrained=args.pretrain)
- else:
- raise ValueError(f'Unsupported actor model "{args.model}"')
-
- if args.rm_model is None:
- rm_model_name = args.model
- else:
- rm_model_name = args.rm_model
-
- if rm_model_name == "gpt2":
- reward_model = GPTRM(pretrained=args.rm_pretrain, lora_rank=args.lora_rank)
- elif rm_model_name == "bloom":
- reward_model = BLOOMRM(pretrained=args.rm_pretrain, lora_rank=args.lora_rank)
- elif rm_model_name == "opt":
- reward_model = OPTRM(pretrained=args.rm_pretrain, lora_rank=args.lora_rank)
- elif rm_model_name == "llama":
- reward_model = LlamaRM(pretrained=args.rm_pretrain, lora_rank=args.lora_rank)
- else:
- raise ValueError(f'Unsupported reward model "{rm_model_name}"')
-
- if args.rm_path is not None:
- reward_model.load_state_dict(state_dict, strict=False)
-
- initial_model.to(torch.bfloat16).to(torch.cuda.current_device())
- reward_model.to(torch.bfloat16).to(torch.cuda.current_device())
-
- if args.model == "gpt2":
- actor = GPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank)
- elif args.model == "bloom":
- actor = BLOOMActor(pretrained=args.pretrain, lora_rank=args.lora_rank)
- elif args.model == "opt":
- actor = OPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank)
- elif args.model == "llama":
- actor = LlamaActor(pretrained=args.pretrain, lora_rank=args.lora_rank)
- else:
- raise ValueError(f'Unsupported actor model "{args.model}"')
-
- if rm_model_name == "gpt2":
- critic = GPTCritic(pretrained=args.rm_pretrain, lora_rank=args.lora_rank)
- elif rm_model_name == "bloom":
- critic = BLOOMCritic(pretrained=args.rm_pretrain, lora_rank=args.lora_rank)
- elif rm_model_name == "opt":
- critic = OPTCritic(pretrained=args.rm_pretrain, lora_rank=args.lora_rank)
- elif rm_model_name == "llama":
- critic = LlamaCritic(pretrained=args.rm_pretrain, lora_rank=args.lora_rank)
- else:
- raise ValueError(f'Unsupported reward model "{rm_model_name}"')
-
- if args.rm_path is not None:
- critic.load_state_dict(state_dict, strict=False)
- del state_dict
-
- actor.to(torch.bfloat16).to(torch.cuda.current_device())
- critic.to(torch.bfloat16).to(torch.cuda.current_device())
-
- # configure optimizer
- if args.strategy.startswith("colossalai"):
- actor_optim = HybridAdam(actor.parameters(), lr=args.lr)
- critic_optim = HybridAdam(critic.parameters(), lr=args.lr)
- else:
- actor_optim = Adam(actor.parameters(), lr=args.lr)
- critic_optim = Adam(critic.parameters(), lr=args.lr)
-
- # configure tokenizer
- if args.model == "gpt2":
- tokenizer = GPT2Tokenizer.from_pretrained("gpt2" if args.tokenizer is None else args.tokenizer)
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == "bloom":
- tokenizer = BloomTokenizerFast.from_pretrained(
- "bigscience/bloom-560m" if args.tokenizer is None else args.tokenizer
- )
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == "opt":
- tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m" if args.tokenizer is None else args.tokenizer)
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == "llama":
- tokenizer = LlamaTokenizer.from_pretrained(
- "hf-internal-testing/llama-tokenizer" if args.tokenizer is None else args.tokenizer
- )
- tokenizer.eos_token = "<\s>"
- tokenizer.pad_token = tokenizer.unk_token
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
- # NOTE: generate() requires padding_side to be "left"
- tokenizer.padding_side = "left"
-
- prompt_dataset = PromptDataset(
- tokenizer=tokenizer,
- data_path=args.prompt_dataset,
- max_datasets_size=args.max_datasets_size,
- max_length=args.max_input_len,
- )
- if dist.is_initialized() and dist.get_world_size() > 1:
- prompt_sampler = DistributedSampler(prompt_dataset, shuffle=True, seed=42, drop_last=True)
- else:
- prompt_sampler = None
- prompt_dataloader = DataLoader(
- prompt_dataset, shuffle=(prompt_sampler is None), sampler=prompt_sampler, batch_size=args.experience_batch_size
- )
-
- pretrain_dataset = SupervisedDataset(
- tokenizer=tokenizer,
- data_path=args.pretrain_dataset,
- max_datasets_size=args.max_datasets_size,
- max_length=args.max_input_len,
- )
- if dist.is_initialized() and dist.get_world_size() > 1:
- pretrain_sampler = DistributedSampler(pretrain_dataset, shuffle=True, seed=42, drop_last=True)
- else:
- pretrain_sampler = None
- pretrain_dataloader = DataLoader(
- pretrain_dataset, shuffle=(pretrain_sampler is None), sampler=pretrain_sampler, batch_size=args.ptx_batch_size
- )
-
- # NOTE: For small models like opt-1.3b, reward model and initial model are not required to be parallelized.
- (actor, actor_optim), (critic, critic_optim), reward_model, initial_model = strategy.prepare(
- (actor, actor_optim), (critic, critic_optim), reward_model, initial_model
- )
-
- # configure trainer
- trainer = PPOTrainer(
- strategy,
- actor,
- critic,
- reward_model,
- initial_model,
- actor_optim,
- critic_optim,
- tokenizer=tokenizer,
- kl_coef=args.kl_coef,
- ptx_coef=args.ptx_coef,
- train_batch_size=args.train_batch_size,
- max_length=args.max_seq_len,
- use_cache=True,
- do_sample=True,
- temperature=1.0,
- top_k=50,
- offload_inference_models=args.strategy != "colossalai_gemini",
- )
-
- trainer.fit(
- num_episodes=args.num_episodes,
- num_collect_steps=args.num_collect_steps,
- num_update_steps=args.num_update_steps,
- prompt_dataloader=prompt_dataloader,
- pretrain_dataloader=pretrain_dataloader,
- log_dir=args.log_dir,
- use_wandb=args.use_wandb,
- )
-
- if args.lora_rank > 0 and args.merge_lora_weights:
- from coati.models.lora import LORA_MANAGER
-
- # NOTE: set model to eval to merge LoRA weights
- LORA_MANAGER.merge_weights = True
- actor.eval()
- # save model checkpoint after fitting
- strategy.save_pretrained(actor, path=args.save_path)
- # save optimizer checkpoint on all ranks
- if args.need_optim_ckpt:
- strategy.save_optimizer(
- actor_optim, "actor_optim_checkpoint_prompts_%d.pt" % (torch.cuda.current_device()), only_rank0=False
- )
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument("--prompt_dataset", type=str, default=None, help="path to the prompt dataset")
- parser.add_argument("--pretrain_dataset", type=str, default=None, help="path to the pretrained dataset")
- parser.add_argument("--max_datasets_size", type=int, default=50000)
- parser.add_argument(
- "--strategy",
- choices=["ddp", "colossalai_gemini", "colossalai_zero2"],
- default="colossalai_zero2",
- help="strategy to use",
- )
- parser.add_argument("--model", default="gpt2", choices=["gpt2", "bloom", "opt", "llama"])
- parser.add_argument("--tokenizer", type=str, default=None)
- parser.add_argument("--pretrain", type=str, default=None)
- parser.add_argument("--rm_model", default=None, choices=["gpt2", "bloom", "opt", "llama"])
- parser.add_argument("--rm_path", type=str, default=None)
- parser.add_argument("--rm_pretrain", type=str, default=None)
- parser.add_argument("--save_path", type=str, default="actor_checkpoint_prompts")
- parser.add_argument("--need_optim_ckpt", type=bool, default=False)
- parser.add_argument("--num_episodes", type=int, default=10)
- parser.add_argument("--num_collect_steps", type=int, default=10)
- parser.add_argument("--num_update_steps", type=int, default=5)
- parser.add_argument("--train_batch_size", type=int, default=8)
- parser.add_argument("--ptx_batch_size", type=int, default=1)
- parser.add_argument("--experience_batch_size", type=int, default=8)
- parser.add_argument("--lora_rank", type=int, default=0, help="low-rank adaptation matrices rank")
- parser.add_argument("--merge_lora_weights", type=bool, default=True)
- parser.add_argument("--lr", type=float, default=1e-7)
- parser.add_argument("--kl_coef", type=float, default=0.1)
- parser.add_argument("--ptx_coef", type=float, default=0.9)
- parser.add_argument("--max_input_len", type=int, default=96)
- parser.add_argument("--max_seq_len", type=int, default=128)
- parser.add_argument("--log_dir", default="logs", type=str)
- parser.add_argument("--use_wandb", default=False, action="store_true")
- args = parser.parse_args()
- main(args)
diff --git a/applications/Chat/examples/train_prompts.sh b/applications/Chat/examples/train_prompts.sh
deleted file mode 100755
index d04c416015b1..000000000000
--- a/applications/Chat/examples/train_prompts.sh
+++ /dev/null
@@ -1,25 +0,0 @@
-set_n_least_used_CUDA_VISIBLE_DEVICES() {
- local n=${1:-"9999"}
- echo "GPU Memory Usage:"
- local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv |
- tail -n +2 |
- nl -v 0 |
- tee /dev/tty |
- sort -g -k 2 |
- awk '{print $1}' |
- head -n $n)
- export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
- echo "Now CUDA_VISIBLE_DEVICES is set to:"
- echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
-}
-
-set_n_least_used_CUDA_VISIBLE_DEVICES 2
-
-# torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy colossalai_zero2
-
-torchrun --standalone --nproc_per_node=2 train_prompts.py \
- --pretrain_dataset /path/to/data.json \
- --prompt_dataset /path/to/data.json \
- --strategy colossalai_zero2 \
- --num_episodes 1 --num_collect_steps 2 --num_update_steps 1 \
- --train_batch_size 2
diff --git a/applications/Chat/examples/train_reward_model.py b/applications/Chat/examples/train_reward_model.py
deleted file mode 100644
index df6e8b6bdc26..000000000000
--- a/applications/Chat/examples/train_reward_model.py
+++ /dev/null
@@ -1,208 +0,0 @@
-import argparse
-import warnings
-
-import torch
-import torch.distributed as dist
-from coati.dataset import HhRlhfDataset, RmStaticDataset
-from coati.models import LogExpLoss, LogSigLoss
-from coati.models.bloom import BLOOMRM
-from coati.models.gpt import GPTRM
-from coati.models.llama import LlamaRM
-from coati.models.opt import OPTRM
-from coati.trainer import RewardModelTrainer
-from coati.trainer.strategies import DDPStrategy, GeminiStrategy, LowLevelZeroStrategy
-from datasets import load_dataset
-from torch.optim import Adam
-from torch.optim.lr_scheduler import CosineAnnealingLR
-from torch.utils.data import DataLoader
-from torch.utils.data.distributed import DistributedSampler
-from transformers import AutoTokenizer, BloomTokenizerFast, LlamaTokenizer
-from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
-
-from colossalai.nn.optimizer import HybridAdam
-
-
-def train(args):
- # configure strategy
- if args.strategy == "ddp":
- strategy = DDPStrategy()
- elif args.strategy == "colossalai_gemini":
- strategy = GeminiStrategy(placement_policy="auto")
- elif args.strategy == "colossalai_zero2":
- strategy = LowLevelZeroStrategy(stage=2, placement_policy="cuda")
- else:
- raise ValueError(f'Unsupported strategy "{args.strategy}"')
-
- # configure model
- if args.lora_rank > 0:
- warnings.warn("Lora is not supported yet.")
- args.lora_rank = 0
-
- with strategy.model_init_context():
- if args.model == "bloom":
- model = BLOOMRM(pretrained=args.pretrain, lora_rank=args.lora_rank)
- elif args.model == "opt":
- model = OPTRM(pretrained=args.pretrain, lora_rank=args.lora_rank)
- elif args.model == "gpt2":
- model = GPTRM(pretrained=args.pretrain, lora_rank=args.lora_rank)
- elif args.model == "llama":
- model = LlamaRM(pretrained=args.pretrain, lora_rank=args.lora_rank)
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
-
- model.to(torch.bfloat16).to(torch.cuda.current_device())
-
- if args.model_path is not None:
- state_dict = torch.load(args.model_path)
- model.load_state_dict(state_dict)
-
- # configure tokenizer
- if args.model == "gpt2":
- tokenizer = GPT2Tokenizer.from_pretrained("gpt2" if args.tokenizer is None else args.tokenizer)
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == "bloom":
- tokenizer = BloomTokenizerFast.from_pretrained(
- "bigscience/bloom-560m" if args.tokenizer is None else args.tokenizer
- )
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == "opt":
- tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m" if args.tokenizer is None else args.tokenizer)
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == "llama":
- tokenizer = LlamaTokenizer.from_pretrained(
- "hf-internal-testing/llama-tokenizer" if args.tokenizer is None else args.tokenizer
- )
- tokenizer.eos_token = "<\s>"
- tokenizer.pad_token = tokenizer.unk_token
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
-
- # configure optimizer
- if args.strategy.startswith("colossalai"):
- optim = HybridAdam(model.parameters(), lr=args.lr)
- else:
- optim = Adam(model.parameters(), lr=args.lr)
-
- # configure loss function
- if args.loss_fn == "log_sig":
- loss_fn = LogSigLoss()
- elif args.loss_fn == "log_exp":
- loss_fn = LogExpLoss()
- else:
- raise ValueError(f'Unsupported loss function "{args.loss_fn}"')
-
- # prepare for data and dataset
- if args.subset is not None:
- data = load_dataset(args.dataset, data_dir=args.subset)
- else:
- data = load_dataset(args.dataset)
-
- train_data = data["train"].select(range(min(args.max_datasets_size, len(data["train"]))))
- eval_data = data["test"].select(range(min(args.max_datasets_size, len(data["test"]))))
-
- if args.dataset == "Dahoas/rm-static":
- train_dataset = RmStaticDataset(train_data, tokenizer, args.max_len)
- eval_dataset = RmStaticDataset(eval_data, tokenizer, args.max_len)
- elif args.dataset == "Anthropic/hh-rlhf":
- train_dataset = HhRlhfDataset(train_data, tokenizer, args.max_len)
- eval_dataset = HhRlhfDataset(eval_data, tokenizer, args.max_len)
- else:
- raise ValueError(f'Unsupported dataset "{args.dataset}"')
-
- if dist.is_initialized() and dist.get_world_size() > 1:
- train_sampler = DistributedSampler(
- train_dataset,
- shuffle=True,
- seed=42,
- drop_last=True,
- rank=dist.get_rank(),
- num_replicas=dist.get_world_size(),
- )
- eval_sampler = DistributedSampler(
- eval_dataset,
- shuffle=True,
- seed=42,
- drop_last=True,
- rank=dist.get_rank(),
- num_replicas=dist.get_world_size(),
- )
- else:
- train_sampler = None
- eval_sampler = None
-
- train_dataloader = DataLoader(
- train_dataset,
- shuffle=(train_sampler is None),
- sampler=train_sampler,
- batch_size=args.batch_size,
- pin_memory=True,
- )
-
- eval_dataloader = DataLoader(
- eval_dataset, shuffle=(eval_sampler is None), sampler=eval_sampler, batch_size=args.batch_size, pin_memory=True
- )
-
- lr_scheduler = CosineAnnealingLR(optim, train_dataloader.__len__() // 100)
- strategy_dict = strategy.prepare(dict(model=model, optimizer=optim, lr_scheduler=lr_scheduler))
- model = strategy_dict["model"]
- optim = strategy_dict["optimizer"]
- lr_scheduler = strategy_dict["lr_scheduler"]
- trainer = RewardModelTrainer(
- model=model,
- strategy=strategy,
- optim=optim,
- lr_scheduler=lr_scheduler,
- loss_fn=loss_fn,
- max_epochs=args.max_epochs,
- )
-
- trainer.fit(
- train_dataloader=train_dataloader,
- eval_dataloader=eval_dataloader,
- log_dir=args.log_dir,
- use_wandb=args.use_wandb,
- )
-
- if args.lora_rank > 0 and args.merge_lora_weights:
- from coati.models.lora import LORA_MANAGER
-
- # NOTE: set model to eval to merge LoRA weights
- LORA_MANAGER.merge_weights = True
- model.eval()
- # save model checkpoint after fitting on only rank0
- state_dict = model.state_dict()
- torch.save(state_dict, args.save_path)
- # save optimizer checkpoint on all ranks
- if args.need_optim_ckpt:
- strategy.save_optimizer(
- trainer.optimizer, "rm_optim_checkpoint_%d.pt" % (torch.cuda.current_device()), only_rank0=False
- )
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--strategy", choices=["ddp", "colossalai_gemini", "colossalai_zero2"], default="colossalai_zero2"
- )
- parser.add_argument("--model", choices=["gpt2", "bloom", "opt", "llama"], default="bloom")
- parser.add_argument("--tokenizer", type=str, default=None)
- parser.add_argument("--pretrain", type=str, default=None)
- parser.add_argument("--model_path", type=str, default=None)
- parser.add_argument("--need_optim_ckpt", type=bool, default=False)
- parser.add_argument(
- "--dataset", type=str, choices=["Anthropic/hh-rlhf", "Dahoas/rm-static"], default="Dahoas/rm-static"
- )
- parser.add_argument("--subset", type=lambda x: None if x == "None" else x, default=None)
- parser.add_argument("--max_datasets_size", type=int, default=1000000)
- parser.add_argument("--save_path", type=str, default="rm_ckpt")
- parser.add_argument("--max_epochs", type=int, default=1)
- parser.add_argument("--batch_size", type=int, default=1)
- parser.add_argument("--max_len", type=int, default=512)
- parser.add_argument("--lora_rank", type=int, default=0, help="low-rank adaptation matrices rank")
- parser.add_argument("--merge_lora_weights", type=bool, default=True)
- parser.add_argument("--lr", type=float, default=9e-6)
- parser.add_argument("--loss_fn", type=str, default="log_sig", choices=["log_sig", "log_exp"])
- parser.add_argument("--log_dir", default="logs", type=str)
- parser.add_argument("--use_wandb", default=False, action="store_true")
- args = parser.parse_args()
- train(args)
diff --git a/applications/Chat/examples/train_rm.sh b/applications/Chat/examples/train_rm.sh
deleted file mode 100755
index c5ebaf708ddc..000000000000
--- a/applications/Chat/examples/train_rm.sh
+++ /dev/null
@@ -1,25 +0,0 @@
-set_n_least_used_CUDA_VISIBLE_DEVICES() {
- local n=${1:-"9999"}
- echo "GPU Memory Usage:"
- local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv |
- tail -n +2 |
- nl -v 0 |
- tee /dev/tty |
- sort -g -k 2 |
- awk '{print $1}' |
- head -n $n)
- export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
- echo "Now CUDA_VISIBLE_DEVICES is set to:"
- echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
-}
-
-set_n_least_used_CUDA_VISIBLE_DEVICES 2
-
-torchrun --standalone --nproc_per_node=2 train_reward_model.py \
- --pretrain 'gpt2' \
- --model 'gpt2' \
- --strategy colossalai_zero2 \
- --loss_fn 'log_exp' \
- --dataset 'Anthropic/hh-rlhf' \
- --batch_size 16 \
- --max_epochs 10
diff --git a/applications/Chat/examples/train_sft.py b/applications/Chat/examples/train_sft.py
deleted file mode 100644
index 66d08da30120..000000000000
--- a/applications/Chat/examples/train_sft.py
+++ /dev/null
@@ -1,221 +0,0 @@
-import argparse
-import math
-import warnings
-
-import torch
-import torch.distributed as dist
-from coati.dataset import SFTDataset, SupervisedDataset
-from coati.models.bloom import BLOOMActor
-from coati.models.chatglm import ChatGLMActor
-from coati.models.chatglm.chatglm_tokenizer import ChatGLMTokenizer
-from coati.models.gpt import GPTActor
-from coati.models.llama import LlamaActor
-from coati.models.opt import OPTActor
-from coati.trainer import SFTTrainer
-from coati.trainer.strategies import DDPStrategy, GeminiStrategy, LowLevelZeroStrategy
-from datasets import load_dataset
-from torch.optim import Adam
-from torch.utils.data import DataLoader
-from torch.utils.data.distributed import DistributedSampler
-from transformers import AutoTokenizer, BloomTokenizerFast, LlamaTokenizer
-from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
-from transformers.trainer import get_scheduler
-
-from colossalai.logging import get_dist_logger
-from colossalai.nn.optimizer import HybridAdam
-
-
-def train(args):
- # configure strategy
- if args.strategy == "ddp":
- strategy = DDPStrategy()
- elif args.strategy == "colossalai_gemini":
- strategy = GeminiStrategy(placement_policy="auto")
- elif args.strategy == "colossalai_zero2":
- strategy = LowLevelZeroStrategy(stage=2, placement_policy="cuda")
- elif args.strategy == "colossalai_zero2_cpu":
- strategy = LowLevelZeroStrategy(stage=2, placement_policy="cpu")
- else:
- raise ValueError(f'Unsupported strategy "{args.strategy}"')
-
- # configure model
- if args.lora_rank > 0:
- warnings.warn("Lora is not supported yet.")
- args.lora_rank = 0
-
- with strategy.model_init_context():
- if args.model == "bloom":
- model = BLOOMActor(pretrained=args.pretrain, lora_rank=args.lora_rank, checkpoint=args.grad_checkpoint)
- elif args.model == "opt":
- model = OPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank, checkpoint=args.grad_checkpoint)
- elif args.model == "gpt2":
- model = GPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank, checkpoint=args.grad_checkpoint)
- elif args.model == "llama":
- model = LlamaActor(pretrained=args.pretrain, lora_rank=args.lora_rank, checkpoint=args.grad_checkpoint)
- elif args.model == "chatglm":
- model = ChatGLMActor(pretrained=args.pretrain)
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
-
- model.to(torch.bfloat16).to(torch.cuda.current_device())
-
- # configure tokenizer
- if args.model == "gpt2":
- tokenizer = GPT2Tokenizer.from_pretrained("gpt2" if args.tokenizer is None else args.tokenizer)
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == "bloom":
- tokenizer = BloomTokenizerFast.from_pretrained(
- "bigscience/bloom-560m" if args.tokenizer is None else args.tokenizer
- )
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == "opt":
- tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m" if args.tokenizer is None else args.tokenizer)
- tokenizer.pad_token = tokenizer.eos_token
- elif args.model == "llama":
- tokenizer = LlamaTokenizer.from_pretrained(
- "hf-internal-testing/llama-tokenizer" if args.tokenizer is None else args.tokenizer
- )
- tokenizer.eos_token = "<\s>"
- tokenizer.pad_token = tokenizer.unk_token
- elif args.model == "chatglm":
- tokenizer = ChatGLMTokenizer.from_pretrained(
- "THUDM/chatglm-6b" if args.tokenizer is None else args.tokenizer, trust_remote_code=True
- )
- else:
- raise ValueError(f'Unsupported model "{args.model}"')
-
- # configure optimizer
- if args.strategy.startswith("colossalai"):
- optim = HybridAdam(model.parameters(), lr=args.lr, clipping_norm=1.0)
- else:
- optim = Adam(model.parameters(), lr=args.lr)
-
- # configure dataset
- if args.dataset == "yizhongw/self_instruct":
- train_data = load_dataset(args.dataset, "super_natural_instructions", split="train")
- eval_data = load_dataset(args.dataset, "super_natural_instructions", split="test")
-
- if args.max_datasets_size is not None:
- train_data = train_data.select(range(min(args.max_datasets_size, len(train_data))))
- eval_data = eval_data.select(range(min(args.max_datasets_size, len(eval_data))))
-
- train_dataset = SFTDataset(train_data, tokenizer, args.max_len)
- eval_dataset = SFTDataset(eval_data, tokenizer, args.max_len)
-
- else:
- train_dataset = SupervisedDataset(
- tokenizer=tokenizer,
- data_path=args.dataset,
- max_datasets_size=args.max_datasets_size,
- max_length=args.max_len,
- )
- eval_dataset = None
-
- if dist.is_initialized() and dist.get_world_size() > 1:
- train_sampler = DistributedSampler(
- train_dataset,
- shuffle=True,
- seed=42,
- drop_last=True,
- rank=dist.get_rank(),
- num_replicas=dist.get_world_size(),
- )
- if eval_dataset is not None:
- eval_sampler = DistributedSampler(
- eval_dataset,
- shuffle=False,
- seed=42,
- drop_last=False,
- rank=dist.get_rank(),
- num_replicas=dist.get_world_size(),
- )
- else:
- train_sampler = None
- eval_sampler = None
-
- train_dataloader = DataLoader(
- train_dataset,
- shuffle=(train_sampler is None),
- sampler=train_sampler,
- batch_size=args.batch_size,
- pin_memory=True,
- )
- if eval_dataset is not None:
- eval_dataloader = DataLoader(
- eval_dataset,
- shuffle=(eval_sampler is None),
- sampler=eval_sampler,
- batch_size=args.batch_size,
- pin_memory=True,
- )
- else:
- eval_dataloader = None
-
- num_update_steps_per_epoch = len(train_dataloader) // args.accumulation_steps
- max_steps = math.ceil(args.max_epochs * num_update_steps_per_epoch)
- lr_scheduler = get_scheduler(
- "cosine", optim, num_warmup_steps=math.ceil(max_steps * 0.03), num_training_steps=max_steps
- )
- strategy_dict = strategy.prepare(dict(model=model, optimizer=optim, lr_scheduler=lr_scheduler))
- model = strategy_dict["model"]
- optim = strategy_dict["optimizer"]
- lr_scheduler = strategy_dict["lr_scheduler"]
- trainer = SFTTrainer(
- model=model,
- strategy=strategy,
- optim=optim,
- lr_scheduler=lr_scheduler,
- max_epochs=args.max_epochs,
- accumulation_steps=args.accumulation_steps,
- )
-
- logger = get_dist_logger()
- trainer.fit(
- train_dataloader=train_dataloader,
- eval_dataloader=eval_dataloader,
- logger=logger,
- log_dir=args.log_dir,
- use_wandb=args.use_wandb,
- )
-
- if args.lora_rank > 0 and args.merge_lora_weights:
- from coati.models.lora import LORA_MANAGER
-
- # NOTE: set model to eval to merge LoRA weights
- LORA_MANAGER.merge_weights = True
- model.eval()
- # save model checkpoint after fitting on only rank0
- strategy.save_pretrained(model, path=args.save_path, tokenizer=tokenizer)
- # save optimizer checkpoint on all ranks
- if args.need_optim_ckpt:
- strategy.save_optimizer(
- trainer.optimizer, "rm_optim_checkpoint_%d.pt" % (torch.cuda.current_device()), only_rank0=False
- )
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--strategy",
- choices=["ddp", "colossalai_gemini", "colossalai_zero2", "colossalai_zero2_cpu"],
- default="colossalai_zero2",
- )
- parser.add_argument("--model", choices=["gpt2", "bloom", "opt", "llama", "chatglm"], default="bloom")
- parser.add_argument("--tokenizer", type=str, default=None)
- parser.add_argument("--pretrain", type=str, default=None)
- parser.add_argument("--dataset", type=str, default=None)
- parser.add_argument("--max_datasets_size", type=int, default=None)
- parser.add_argument("--save_path", type=str, default="output")
- parser.add_argument("--need_optim_ckpt", type=bool, default=False)
- parser.add_argument("--max_epochs", type=int, default=3)
- parser.add_argument("--batch_size", type=int, default=4)
- parser.add_argument("--max_len", type=int, default=512)
- parser.add_argument("--lora_rank", type=int, default=0, help="low-rank adaptation matrices rank")
- parser.add_argument("--merge_lora_weights", type=bool, default=True)
- parser.add_argument("--lr", type=float, default=5e-6)
- parser.add_argument("--accumulation_steps", type=int, default=8)
- parser.add_argument("--log_dir", default="logs", type=str)
- parser.add_argument("--use_wandb", default=False, action="store_true")
- parser.add_argument("--grad_checkpoint", default=False, action="store_true")
- args = parser.parse_args()
- train(args)
diff --git a/applications/Chat/examples/train_sft.sh b/applications/Chat/examples/train_sft.sh
deleted file mode 100755
index 0fb4da3d3ce8..000000000000
--- a/applications/Chat/examples/train_sft.sh
+++ /dev/null
@@ -1,28 +0,0 @@
-set_n_least_used_CUDA_VISIBLE_DEVICES() {
- local n=${1:-"9999"}
- echo "GPU Memory Usage:"
- local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv |
- tail -n +2 |
- nl -v 0 |
- tee /dev/tty |
- sort -g -k 2 |
- awk '{print $1}' |
- head -n $n)
- export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
- echo "Now CUDA_VISIBLE_DEVICES is set to:"
- echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
-}
-
-set_n_least_used_CUDA_VISIBLE_DEVICES 4
-
-torchrun --standalone --nproc_per_node=4 train_sft.py \
- --pretrain "/path/to/LLaMa-7B/" \
- --model 'llama' \
- --strategy colossalai_zero2 \
- --save_path /path/to/Coati-7B \
- --dataset /path/to/data.json \
- --batch_size 4 \
- --accumulation_steps 8 \
- --lr 2e-5 \
- --max_datasets_size 512 \
- --max_epochs 1
diff --git a/applications/Chat/inference/benchmark.py b/applications/Chat/inference/benchmark.py
deleted file mode 100644
index dbb5490a63dc..000000000000
--- a/applications/Chat/inference/benchmark.py
+++ /dev/null
@@ -1,141 +0,0 @@
-# Adapted from https://github.com/tloen/alpaca-lora/blob/main/generate.py
-
-import argparse
-from time import time
-
-import torch
-from coati.quant import llama_load_quant, low_resource_init
-from transformers import AutoTokenizer, GenerationConfig, LlamaConfig, LlamaForCausalLM
-
-
-def generate_prompt(instruction, input=None):
- if input:
- return f"""Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
-
-### Instruction:
-{instruction}
-
-### Input:
-{input}
-
-### Response:"""
- else:
- return f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
-
-### Instruction:
-{instruction}
-
-### Response:"""
-
-
-@torch.no_grad()
-def evaluate(
- model,
- tokenizer,
- instruction,
- input=None,
- temperature=0.1,
- top_p=0.75,
- top_k=40,
- num_beams=4,
- max_new_tokens=128,
- **kwargs,
-):
- prompt = generate_prompt(instruction, input)
- inputs = tokenizer(prompt, return_tensors="pt")
- input_ids = inputs["input_ids"].cuda()
- generation_config = GenerationConfig(
- temperature=temperature,
- top_p=top_p,
- top_k=top_k,
- num_beams=num_beams,
- **kwargs,
- )
- generation_output = model.generate(
- input_ids=input_ids,
- generation_config=generation_config,
- return_dict_in_generate=True,
- output_scores=True,
- max_new_tokens=max_new_tokens,
- do_sample=True,
- )
- s = generation_output.sequences[0]
- output = tokenizer.decode(s)
- n_new_tokens = s.size(0) - input_ids.size(1)
- return output.split("### Response:")[1].strip(), n_new_tokens
-
-
-instructions = [
- "Tell me about alpacas.",
- "Tell me about the president of Mexico in 2019.",
- "Tell me about the king of France in 2019.",
- "List all Canadian provinces in alphabetical order.",
- "Write a Python program that prints the first 10 Fibonacci numbers.",
- "Write a program that prints the numbers from 1 to 100. But for multiples of three print 'Fizz' instead of the number and for the multiples of five print 'Buzz'. For numbers which are multiples of both three and five print 'FizzBuzz'.",
- "Tell me five words that rhyme with 'shock'.",
- "Translate the sentence 'I have no mouth but I must scream' into Spanish.",
- "Count up from 1 to 500.",
- # ===
- "How to play support in legends of league",
- "Write a Python program that calculate Fibonacci numbers.",
-]
-inst = [instructions[0]] * 4
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "pretrained",
- help="Path to pretrained model. Can be a local path or a model name from the HuggingFace model hub.",
- )
- parser.add_argument(
- "--quant",
- choices=["8bit", "4bit"],
- default=None,
- help="Quantization mode. Default: None (no quantization, fp16).",
- )
- parser.add_argument(
- "--gptq_checkpoint",
- default=None,
- help="Path to GPTQ checkpoint. This is only useful when quantization mode is 4bit. Default: None.",
- )
- parser.add_argument(
- "--gptq_group_size",
- type=int,
- default=128,
- help="Group size for GPTQ. This is only useful when quantization mode is 4bit. Default: 128.",
- )
- args = parser.parse_args()
-
- if args.quant == "4bit":
- assert args.gptq_checkpoint is not None, "Please specify a GPTQ checkpoint."
-
- tokenizer = AutoTokenizer.from_pretrained(args.pretrained)
-
- if args.quant == "4bit":
- with low_resource_init():
- config = LlamaConfig.from_pretrained(args.pretrained)
- model = LlamaForCausalLM(config)
- model = llama_load_quant(model, args.gptq_checkpoint, 4, args.gptq_group_size)
- model.cuda()
- else:
- model = LlamaForCausalLM.from_pretrained(
- args.pretrained,
- load_in_8bit=(args.quant == "8bit"),
- torch_dtype=torch.float16,
- device_map="auto",
- )
- if args.quant != "8bit":
- model.half() # seems to fix bugs for some users.
- model.eval()
-
- total_tokens = 0
- start = time()
- for instruction in instructions:
- print(f"Instruction: {instruction}")
- resp, tokens = evaluate(model, tokenizer, instruction, temperature=0.2, num_beams=1)
- total_tokens += tokens
- print(f"Response: {resp}")
- print("\n----------------------------\n")
- duration = time() - start
- print(f"Total time: {duration:.3f} s, {total_tokens/duration:.3f} tokens/s")
- print(f"Peak CUDA mem: {torch.cuda.max_memory_allocated()/1024**3:.3f} GB")
diff --git a/applications/Chat/inference/tests/test_chat_prompt.py b/applications/Chat/inference/tests/test_chat_prompt.py
deleted file mode 100644
index 9835e71894c6..000000000000
--- a/applications/Chat/inference/tests/test_chat_prompt.py
+++ /dev/null
@@ -1,61 +0,0 @@
-import os
-
-from transformers import AutoTokenizer
-from utils import ChatPromptProcessor, Dialogue
-
-CONTEXT = "Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions."
-tokenizer = AutoTokenizer.from_pretrained(os.environ["PRETRAINED_PATH"])
-
-samples = [
- (
- [
- Dialogue(
- instruction="Who is the best player in the history of NBA?",
- response="The best player in the history of the NBA is widely considered to be Michael Jordan. He is one of the most successful players in the league, having won 6 NBA championships with the Chicago Bulls and 5 more with the Washington Wizards. He is a 5-time MVP, 1",
- ),
- Dialogue(instruction="continue this talk", response=""),
- ],
- 128,
- "Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.\n\n### Instruction:\nWho is the best player in the history of NBA?\n\n### Response:\nThe best player in the history of the NBA is widely considered to be Michael Jordan. He is one of the most successful players in the league, having won 6 NBA championships with the Chicago Bulls and 5 more with the Washington Wizards. He is a 5-time MVP, 1\n\n### Instruction:\ncontinue this talk\n\n### Response:\n",
- ),
- (
- [
- Dialogue(
- instruction="Who is the best player in the history of NBA?",
- response="The best player in the history of the NBA is widely considered to be Michael Jordan. He is one of the most successful players in the league, having won 6 NBA championships with the Chicago Bulls and 5 more with the Washington Wizards. He is a 5-time MVP, 1",
- ),
- Dialogue(instruction="continue this talk", response=""),
- ],
- 200,
- "Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.\n\n### Instruction:\ncontinue this talk\n\n### Response:\n",
- ),
- (
- [
- Dialogue(
- instruction="Who is the best player in the history of NBA?",
- response="The best player in the history of the NBA is widely considered to be Michael Jordan. He is one of the most successful players in the league, having won 6 NBA championships with the Chicago Bulls and 5 more with the Washington Wizards. He is a 5-time MVP, 1",
- ),
- Dialogue(instruction="continue this talk", response=""),
- ],
- 211,
- "Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.\n\n### Instruction:\ncontinue this\n\n### Response:\n",
- ),
- (
- [
- Dialogue(instruction="Who is the best player in the history of NBA?", response=""),
- ],
- 128,
- "Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.\n\n### Instruction:\nWho is the best player in the history of NBA?\n\n### Response:\n",
- ),
-]
-
-
-def test_chat_prompt_processor():
- processor = ChatPromptProcessor(tokenizer, CONTEXT, 256)
- for history, max_new_tokens, result in samples:
- prompt = processor.preprocess_prompt(history, max_new_tokens)
- assert prompt == result
-
-
-if __name__ == "__main__":
- test_chat_prompt_processor()
diff --git a/applications/Chat/inference/utils.py b/applications/Chat/inference/utils.py
deleted file mode 100644
index af018adf6e9d..000000000000
--- a/applications/Chat/inference/utils.py
+++ /dev/null
@@ -1,209 +0,0 @@
-import json
-import re
-from threading import Lock
-from typing import Any, Callable, Generator, List, Optional
-
-import jieba
-import torch
-import torch.distributed as dist
-import torch.nn as nn
-from pydantic import BaseModel, Field
-
-try:
- from transformers.generation_logits_process import (
- LogitsProcessorList,
- TemperatureLogitsWarper,
- TopKLogitsWarper,
- TopPLogitsWarper,
- )
-except ImportError:
- from transformers.generation import LogitsProcessorList, TemperatureLogitsWarper, TopKLogitsWarper, TopPLogitsWarper
-
-
-def prepare_logits_processor(
- top_k: Optional[int] = None, top_p: Optional[float] = None, temperature: Optional[float] = None
-) -> LogitsProcessorList:
- processor_list = LogitsProcessorList()
- if temperature is not None and temperature != 1.0:
- processor_list.append(TemperatureLogitsWarper(temperature))
- if top_k is not None and top_k != 0:
- processor_list.append(TopKLogitsWarper(top_k))
- if top_p is not None and top_p < 1.0:
- processor_list.append(TopPLogitsWarper(top_p))
- return processor_list
-
-
-def _is_sequence_finished(unfinished_sequences: torch.Tensor) -> bool:
- if dist.is_initialized() and dist.get_world_size() > 1:
- # consider DP
- unfinished_sequences = unfinished_sequences.clone()
- dist.all_reduce(unfinished_sequences)
- return unfinished_sequences.max() == 0
-
-
-def sample_streamingly(
- model: nn.Module,
- input_ids: torch.Tensor,
- max_generate_tokens: int,
- early_stopping: bool = False,
- eos_token_id: Optional[int] = None,
- pad_token_id: Optional[int] = None,
- top_k: Optional[int] = None,
- top_p: Optional[float] = None,
- temperature: Optional[float] = None,
- prepare_inputs_fn: Optional[Callable[[torch.Tensor, Any], dict]] = None,
- update_model_kwargs_fn: Optional[Callable[[dict, Any], dict]] = None,
- **model_kwargs,
-) -> Generator:
- logits_processor = prepare_logits_processor(top_k, top_p, temperature)
- unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
-
- for _ in range(max_generate_tokens):
- model_inputs = (
- prepare_inputs_fn(input_ids, **model_kwargs) if prepare_inputs_fn is not None else {"input_ids": input_ids}
- )
- outputs = model(**model_inputs)
-
- next_token_logits = outputs["logits"][:, -1, :]
- # pre-process distribution
- next_token_logits = logits_processor(input_ids, next_token_logits)
- # sample
- probs = torch.softmax(next_token_logits, dim=-1, dtype=torch.float)
- next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
-
- # finished sentences should have their next token be a padding token
- if eos_token_id is not None:
- if pad_token_id is None:
- raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
- next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)
-
- yield next_tokens
-
- # update generated ids, model inputs for next step
- input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
- if update_model_kwargs_fn is not None:
- model_kwargs = update_model_kwargs_fn(outputs, **model_kwargs)
-
- # if eos_token was found in one sentence, set sentence to finished
- if eos_token_id is not None:
- unfinished_sequences = unfinished_sequences.mul((next_tokens != eos_token_id).long())
-
- # stop when each sentence is finished if early_stopping=True
- if early_stopping and _is_sequence_finished(unfinished_sequences):
- break
-
-
-def update_model_kwargs_fn(outputs: dict, **model_kwargs) -> dict:
- if "past_key_values" in outputs:
- model_kwargs["past"] = outputs["past_key_values"]
- else:
- model_kwargs["past"] = None
-
- # update token_type_ids with last value
- if "token_type_ids" in model_kwargs:
- token_type_ids = model_kwargs["token_type_ids"]
- model_kwargs["token_type_ids"] = torch.cat([token_type_ids, token_type_ids[:, -1].unsqueeze(-1)], dim=-1)
-
- # update attention mask
- if "attention_mask" in model_kwargs:
- attention_mask = model_kwargs["attention_mask"]
- model_kwargs["attention_mask"] = torch.cat(
- [attention_mask, attention_mask.new_ones((attention_mask.shape[0], 1))], dim=-1
- )
-
- return model_kwargs
-
-
-class Dialogue(BaseModel):
- instruction: str = Field(min_length=1, example="Count up from 1 to 500.")
- response: str = Field(example="")
-
-
-def _format_dialogue(instruction: str, response: str = ""):
- return f"\n\n### Instruction:\n{instruction}\n\n### Response:\n{response}"
-
-
-STOP_PAT = re.compile(r"(###|instruction:).*", flags=(re.I | re.S))
-
-
-class ChatPromptProcessor:
- SAFE_RESPONSE = "The input/response contains inappropriate content, please rephrase your prompt."
-
- def __init__(self, tokenizer, context: str, max_len: int = 2048, censored_words: List[str] = []):
- self.tokenizer = tokenizer
- self.context = context
- self.max_len = max_len
- self.censored_words = set([word.lower() for word in censored_words])
- # These will be initialized after the first call of preprocess_prompt()
- self.context_len: Optional[int] = None
- self.dialogue_placeholder_len: Optional[int] = None
-
- def preprocess_prompt(self, history: List[Dialogue], max_new_tokens: int) -> str:
- if self.context_len is None:
- self.context_len = len(self.tokenizer(self.context)["input_ids"])
- if self.dialogue_placeholder_len is None:
- self.dialogue_placeholder_len = len(
- self.tokenizer(_format_dialogue(""), add_special_tokens=False)["input_ids"]
- )
- prompt = self.context
- # the last dialogue must be in the prompt
- last_dialogue = history.pop()
- # the response of the last dialogue is empty
- assert last_dialogue.response == ""
- if (
- len(self.tokenizer(_format_dialogue(last_dialogue.instruction), add_special_tokens=False)["input_ids"])
- + max_new_tokens
- + self.context_len
- >= self.max_len
- ):
- # to avoid truncate placeholder, apply truncate to the original instruction
- instruction_truncated = self.tokenizer(
- last_dialogue.instruction,
- add_special_tokens=False,
- truncation=True,
- max_length=(self.max_len - max_new_tokens - self.context_len - self.dialogue_placeholder_len),
- )["input_ids"]
- instruction_truncated = self.tokenizer.decode(instruction_truncated).lstrip()
- prompt += _format_dialogue(instruction_truncated)
- return prompt
-
- res_len = self.max_len - max_new_tokens - len(self.tokenizer(prompt)["input_ids"])
-
- rows = []
- for dialogue in history[::-1]:
- text = _format_dialogue(dialogue.instruction, dialogue.response)
- cur_len = len(self.tokenizer(text, add_special_tokens=False)["input_ids"])
- if res_len - cur_len < 0:
- break
- res_len -= cur_len
- rows.insert(0, text)
- prompt += "".join(rows) + _format_dialogue(last_dialogue.instruction)
- return prompt
-
- def postprocess_output(self, output: str) -> str:
- output = STOP_PAT.sub("", output)
- return output.strip()
-
- def has_censored_words(self, text: str) -> bool:
- if len(self.censored_words) == 0:
- return False
- intersection = set(jieba.cut(text.lower())) & self.censored_words
- return len(intersection) > 0
-
-
-class LockedIterator:
- def __init__(self, it, lock: Lock) -> None:
- self.lock = lock
- self.it = iter(it)
-
- def __iter__(self):
- return self
-
- def __next__(self):
- with self.lock:
- return next(self.it)
-
-
-def load_json(path: str):
- with open(path) as f:
- return json.load(f)
diff --git a/applications/Chat/requirements-test.txt b/applications/Chat/requirements-test.txt
deleted file mode 100644
index 93d48bcb6f79..000000000000
--- a/applications/Chat/requirements-test.txt
+++ /dev/null
@@ -1,2 +0,0 @@
-pytest
-colossalai==0.3.3
diff --git a/applications/Chat/requirements.txt b/applications/Chat/requirements.txt
deleted file mode 100644
index e56aaca0e7cb..000000000000
--- a/applications/Chat/requirements.txt
+++ /dev/null
@@ -1,14 +0,0 @@
-transformers>=4.20.1
-tqdm
-datasets
-loralib
-colossalai==0.3.3
-torch<2.0.0, >=1.12.1
-langchain
-tokenizers
-fastapi
-sse_starlette
-wandb
-sentencepiece
-gpustat
-tensorboard
diff --git a/applications/Chat/tests/test_benchmarks.sh b/applications/Chat/tests/test_benchmarks.sh
deleted file mode 100755
index 3fdb25181342..000000000000
--- a/applications/Chat/tests/test_benchmarks.sh
+++ /dev/null
@@ -1,33 +0,0 @@
-#!/bin/bash
-
-set -xue
-
-echo "Hint: You can run this script with 'verbose' as the first argument to run all strategies."
-
-if [[ $# -ne 0 && "$1" == "verbose" ]]; then
- STRATEGIES=(
- 'ddp'
- 'colossalai_gemini'
- 'colossalai_gemini_cpu'
- 'colossalai_zero2'
- 'colossalai_zero2_cpu'
- 'colossalai_zero1'
- 'colossalai_zero1_cpu'
- )
-else
- STRATEGIES=(
- 'colossalai_zero2'
- )
-fi
-
-BASE_DIR=$(dirname $(dirname $(realpath $BASH_SOURCE)))
-BENCHMARKS_DIR=$BASE_DIR/benchmarks
-
-echo "[Test]: testing benchmarks ..."
-
-for strategy in ${STRATEGIES[@]}; do
- torchrun --standalone --nproc_per_node 1 $BENCHMARKS_DIR/benchmark_opt_lora_dummy.py \
- --model 125m --critic_model 125m --strategy ${strategy} --lora_rank 4 \
- --num_episodes 2 --num_collect_steps 4 --num_update_steps 2 \
- --train_batch_size 2 --experience_batch_size 4
-done
diff --git a/applications/Chat/tests/test_checkpoint.py b/applications/Chat/tests/test_checkpoint.py
deleted file mode 100644
index 9c08aa36c9b4..000000000000
--- a/applications/Chat/tests/test_checkpoint.py
+++ /dev/null
@@ -1,91 +0,0 @@
-import os
-import tempfile
-from contextlib import nullcontext
-
-import pytest
-import torch
-import torch.distributed as dist
-from coati.models.gpt import GPTActor
-from coati.models.utils import calc_action_log_probs
-from coati.trainer.strategies import DDPStrategy, GeminiStrategy, LowLevelZeroStrategy, Strategy
-from transformers.models.gpt2.configuration_gpt2 import GPT2Config
-
-from colossalai.nn.optimizer import HybridAdam
-from colossalai.testing import rerun_if_address_is_in_use, spawn
-
-GPT_CONFIG = GPT2Config(n_embd=128, n_layer=4, n_head=4)
-
-
-def get_data(batch_size: int, seq_len: int = 10) -> dict:
- input_ids = torch.randint(0, 50257, (batch_size, seq_len), device="cuda")
- attention_mask = torch.ones_like(input_ids)
- return dict(input_ids=input_ids, attention_mask=attention_mask)
-
-
-def train_step(strategy: Strategy, actor: GPTActor, actor_optim: HybridAdam, batch_size: int = 8):
- data = get_data(batch_size)
- action_mask = torch.ones_like(data["attention_mask"], dtype=torch.bool)
- actor_logits = actor(data["input_ids"], data["attention_mask"])["logits"]
- action_log_probs = calc_action_log_probs(actor_logits, data["input_ids"], action_mask.size(1))
- loss = action_log_probs.sum()
- strategy.backward(loss, actor, actor_optim)
- strategy.optimizer_step(actor_optim)
-
-
-def run_test_checkpoint(strategy_name: str, shard: bool):
- if strategy_name == "ddp":
- strategy = DDPStrategy()
- elif strategy_name == "colossalai_gemini":
- strategy = GeminiStrategy(placement_policy="auto", initial_scale=2**5)
- elif strategy_name == "colossalai_zero2":
- strategy = LowLevelZeroStrategy(stage=2, placement_policy="cuda")
- else:
- raise ValueError(f"Unsupported strategy '{strategy_name}'")
-
- with strategy.model_init_context():
- actor = GPTActor(config=GPT_CONFIG).cuda()
- actor_optim = HybridAdam(actor.parameters())
- actor, actor_optim = strategy.prepare((actor, actor_optim))
-
- train_step(strategy, actor, actor_optim)
-
- ctx = tempfile.TemporaryDirectory() if dist.get_rank() == 0 else nullcontext()
-
- with ctx as dirname:
- rank0_dirname = [dirname]
- dist.broadcast_object_list(rank0_dirname)
- rank0_dirname = rank0_dirname[0]
-
- model_path = os.path.join(rank0_dirname, "model" if shard else f"model.pt")
- strategy.save_model(actor, model_path)
- optim_path = os.path.join(rank0_dirname, "optim" if shard else "optim.pt")
- strategy.save_optimizer(actor_optim, optim_path)
- dist.barrier()
-
- strategy.load_model(actor, model_path, strict=False)
- strategy.load_optimizer(actor_optim, optim_path)
- dist.barrier()
-
- train_step(strategy, actor, actor_optim)
-
-
-def run_dist(rank: int, world_size: int, port: int, strategy_name: str, shard: bool):
- os.environ["RANK"] = str(rank)
- os.environ["LOCAL_RANK"] = str(rank)
- os.environ["WORLD_SIZE"] = str(world_size)
- os.environ["MASTER_ADDR"] = "localhost"
- os.environ["MASTER_PORT"] = str(port)
- run_test_checkpoint(strategy_name, shard)
-
-
-@pytest.mark.dist
-@pytest.mark.parametrize("world_size", [4])
-@pytest.mark.parametrize("strategy_name", ["ddp", "colossalai_gemini", "colossalai_zero2"])
-@pytest.mark.parametrize("shard", [False, True])
-@rerun_if_address_is_in_use()
-def test_checkpoint(world_size: int, strategy_name: str, shard: bool):
- spawn(run_dist, world_size, strategy_name=strategy_name, shard=shard)
-
-
-if __name__ == "__main__":
- test_checkpoint(2, "colossalai_gemini", shard=False)
diff --git a/applications/Chat/tests/test_dataset.py b/applications/Chat/tests/test_dataset.py
deleted file mode 100644
index ec61bbb13fd7..000000000000
--- a/applications/Chat/tests/test_dataset.py
+++ /dev/null
@@ -1,241 +0,0 @@
-import json
-import os
-import tempfile
-from typing import Optional
-
-import pytest
-import torch
-from coati.dataset.prompt_dataset import PromptDataset
-from coati.dataset.reward_dataset import HhRlhfDataset, RmStaticDataset
-from coati.dataset.sft_dataset import IGNORE_INDEX, SFTDataset, SupervisedDataset
-from coati.models.chatglm.chatglm_tokenizer import ChatGLMTokenizer
-from datasets import load_dataset
-from transformers import AutoTokenizer, BloomTokenizerFast, LlamaTokenizer, PreTrainedTokenizer
-from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
-
-SFT_DATASET = [
- {
- "instruction": "Provide a list of the top 10 most popular mobile games in Asia",
- "input": "",
- "output": "The top 10 most popular mobile games in Asia are:\n1) PUBG Mobile\n2) Pokemon Go\n3) Candy Crush Saga\n4) Free Fire\n5) Clash of Clans\n6) Mario Kart Tour\n7) Arena of Valor\n8) Fantasy Westward Journey\n9) Subway Surfers\n10) ARK Survival Evolved",
- "id": 0,
- },
- {
- "instruction": "Please provide an action plan for reducing carbon footprint on a corporate level",
- "input": "",
- "output": "An action plan for reducing carbon footprint on a corporate level could include switching to renewable energy sources (e.g., solar or wind powered), investing in energy efficient infrastructure, implementing green production practices (e.g., reduce water and paper usage, dispose of materials responsibly, recycle/reuse materials), reducing or eliminating travel, encouraging employees to be conscious of and reduce their own energy usage, and incentivizing employees to participate in sustainable work practices.",
- "id": 1,
- },
- {
- "instruction": "Write a persuasive email to your boss explaining why you should have a pay raise",
- "input": "",
- "output": "Dear [Boss], \n\nI hope this message finds you well. I am writing to request a pay raise.\n\nAs you know, I have been a dedicated and hardworking member of the team since I started working here [insert number] of months/years ago. My enthusiasm and passion for my job has remained consistent over the years, and I have always given 100% to my role. \n\nI understand that the current financial situation is challenging, however, I would sincerely appreciate you taking the time to consider my request. I believe that my dedication to the job and the value that I bring to the organization warrants a raise. I work diligently and am confident that I can continue to be an asset to the company. \n\nI hope my request is taken into account and I thank you in advance for your understanding. I look forward to our conversation. \n\nSincerely,\n[Your Name]",
- "id": 2,
- },
-]
-
-PROMPT_DATASET = [
- {
- "instruction": 'Edit this paragraph to make it more concise: "Yesterday, I went to the store and bought some things. Then, I came home and put them away. After that, I went for a walk and met some friends."',
- "id": 0,
- },
- {"instruction": "Write a descriptive paragraph about a memorable vacation you went on", "id": 1},
- {"instruction": "Write a persuasive essay arguing why homework should be banned in schools", "id": 2},
- {"instruction": "Create a chart comparing the statistics on student debt in the United States.", "id": 3},
-]
-
-
-def make_tokenizer(model: str):
- if model == "gpt2":
- tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
- tokenizer.pad_token = tokenizer.eos_token
- elif model == "bloom":
- tokenizer = BloomTokenizerFast.from_pretrained("bigscience/bloom-560m")
- tokenizer.pad_token = tokenizer.eos_token
- elif model == "opt":
- tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
- tokenizer.pad_token = tokenizer.eos_token
- elif model == "llama":
- tokenizer = LlamaTokenizer.from_pretrained("hf-internal-testing/llama-tokenizer")
- tokenizer.pad_token = tokenizer.unk_token
- elif model == "chatglm":
- tokenizer = ChatGLMTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
- else:
- raise ValueError(f"Unsupported model '{model}'")
- return tokenizer
-
-
-def check_content(input_ids_stripped: torch.Tensor, tokenizer: PreTrainedTokenizer, model: str):
- if model == "opt":
- # NOTE: Contrary to GPT2, OPT adds the EOS token to the beginning of every prompt.
- assert input_ids_stripped[0] == tokenizer.eos_token_id
- input_ids_stripped = input_ids_stripped[1:]
- elif model == "llama":
- assert input_ids_stripped[0] == tokenizer.bos_token_id
- input_ids_stripped = input_ids_stripped[1:]
- elif model == "chatglm":
- assert input_ids_stripped[0] == tokenizer.bos_token_id
- assert input_ids_stripped[-1] == tokenizer.eos_token_id
- input_ids_stripped = input_ids_stripped[1:-1]
- assert torch.all(input_ids_stripped != tokenizer.pad_token_id)
- assert torch.all(input_ids_stripped != tokenizer.bos_token_id)
- assert torch.all(input_ids_stripped != tokenizer.eos_token_id)
- assert input_ids_stripped != tokenizer.sep_token_id
- assert input_ids_stripped != tokenizer.cls_token_id
- if model == "chatglm":
- assert torch.all(input_ids_stripped != tokenizer.mask_token_id)
- else:
- assert input_ids_stripped != tokenizer.mask_token_id
-
-
-@pytest.mark.parametrize("model", ["gpt2", "bloom", "opt", "llama"])
-@pytest.mark.parametrize("max_length", [32, 1024])
-@pytest.mark.parametrize("max_datasets_size", [2])
-def test_prompt_dataset(model: str, max_datasets_size: int, max_length: int):
- with tempfile.TemporaryDirectory() as tmp_dir:
- dataset_name = "prompt_dataset.json"
- with open(os.path.join(tmp_dir, dataset_name), "w") as f:
- json.dump(PROMPT_DATASET, f)
- tokenizer = make_tokenizer(model)
- assert tokenizer.padding_side in ("left", "right")
- prompt_dataset = PromptDataset(
- data_path=os.path.join(tmp_dir, dataset_name),
- tokenizer=tokenizer,
- max_datasets_size=max_datasets_size,
- max_length=max_length,
- )
- assert len(prompt_dataset) == min(max_datasets_size, len(PROMPT_DATASET))
- for i in range(len(prompt_dataset)):
- assert isinstance(prompt_dataset[i], dict)
- assert list(prompt_dataset[i].keys()) == ["input_ids", "attention_mask"]
- input_ids = prompt_dataset[i]["input_ids"]
- attention_mask = prompt_dataset[i]["attention_mask"]
- attention_mask = attention_mask.bool()
- assert input_ids.shape == attention_mask.shape == torch.Size([max_length])
- assert torch.all(input_ids[torch.logical_not(attention_mask)] == tokenizer.pad_token_id)
- check_content(input_ids.masked_select(attention_mask), tokenizer, model)
-
-
-@pytest.mark.parametrize("model", ["gpt2", "bloom", "opt", "llama"])
-@pytest.mark.parametrize(
- ["dataset_path", "subset"], [("Anthropic/hh-rlhf", "harmless-base"), ("Dahoas/rm-static", None)]
-)
-@pytest.mark.parametrize("max_datasets_size", [32])
-@pytest.mark.parametrize("max_length", [32, 1024])
-def test_reward_dataset(model: str, dataset_path: str, subset: Optional[str], max_datasets_size: int, max_length: int):
- data = load_dataset(dataset_path, data_dir=subset)
- assert max_datasets_size <= len(data["train"]) and max_datasets_size <= len(data["test"])
- train_data = data["train"].select(range(max_datasets_size))
- test_data = data["test"].select(range(max_datasets_size))
- tokenizer = make_tokenizer(model)
- assert tokenizer.padding_side in ("left", "right")
-
- if dataset_path == "Anthropic/hh-rlhf":
- train_dataset = HhRlhfDataset(train_data, tokenizer, max_length)
- test_dataset = HhRlhfDataset(test_data, tokenizer, max_length)
- elif dataset_path == "Dahoas/rm-static":
- train_dataset = RmStaticDataset(train_data, tokenizer, max_length)
- test_dataset = RmStaticDataset(test_data, tokenizer, max_length)
- else:
- raise ValueError(f'Unsupported dataset "{dataset_path}"')
-
- assert len(train_dataset) == len(test_dataset) == max_datasets_size
- for i in range(max_datasets_size):
- chosen_ids, c_mask, reject_ids, r_mask = train_dataset[i]
- assert chosen_ids.shape == c_mask.shape == reject_ids.shape == r_mask.shape == torch.Size([max_length])
- c_mask = c_mask.to(torch.bool)
- r_mask = r_mask.to(torch.bool)
- if chosen_ids.masked_select(c_mask)[-1] == tokenizer.eos_token_id:
- check_content(chosen_ids.masked_select(c_mask)[:-1], tokenizer, model)
- assert torch.all(chosen_ids.masked_select(torch.logical_not(c_mask)) == tokenizer.pad_token_id)
- else:
- check_content(chosen_ids.masked_select(c_mask), tokenizer, model)
- assert torch.all(c_mask)
- if reject_ids.masked_select(r_mask)[-1] == tokenizer.eos_token_id:
- check_content(reject_ids.masked_select(r_mask)[:-1], tokenizer, model)
- assert torch.all(reject_ids.masked_select(torch.logical_not(r_mask)) == tokenizer.pad_token_id)
- else:
- check_content(reject_ids.masked_select(r_mask), tokenizer, model)
- assert torch.all(r_mask)
-
- chosen_ids, c_mask, reject_ids, r_mask = test_dataset[i]
- assert chosen_ids.shape == c_mask.shape == reject_ids.shape == r_mask.shape == torch.Size([max_length])
- c_mask = c_mask.to(torch.bool)
- r_mask = r_mask.to(torch.bool)
- if chosen_ids.masked_select(c_mask)[-1] == tokenizer.eos_token_id:
- check_content(chosen_ids.masked_select(c_mask)[:-1], tokenizer, model)
- assert torch.all(chosen_ids.masked_select(torch.logical_not(c_mask)) == tokenizer.pad_token_id)
- else:
- check_content(chosen_ids.masked_select(c_mask), tokenizer, model)
- assert torch.all(c_mask)
- if reject_ids.masked_select(r_mask)[-1] == tokenizer.eos_token_id:
- check_content(reject_ids.masked_select(r_mask)[:-1], tokenizer, model)
- assert torch.all(reject_ids.masked_select(torch.logical_not(r_mask)) == tokenizer.pad_token_id)
- else:
- check_content(reject_ids.masked_select(r_mask), tokenizer, model)
- assert torch.all(r_mask)
-
-
-@pytest.mark.parametrize("model", ["gpt2", "bloom", "opt", "llama", "chatglm"])
-@pytest.mark.parametrize("dataset_path", ["yizhongw/self_instruct", None])
-@pytest.mark.parametrize("max_dataset_size", [2])
-@pytest.mark.parametrize("max_length", [32, 1024])
-def test_sft_dataset(model: str, dataset_path: Optional[str], max_dataset_size: int, max_length: int):
- tokenizer = make_tokenizer(model)
- if dataset_path == "yizhongw/self_instruct":
- data = load_dataset(dataset_path, "super_natural_instructions")
- train_data = data["train"].select(range(max_dataset_size))
- sft_dataset = SFTDataset(train_data, tokenizer, max_length)
- else:
- with tempfile.TemporaryDirectory() as tmp_dir:
- dataset_name = "sft_dataset.json"
- with open(os.path.join(tmp_dir, dataset_name), "w") as f:
- json.dump(SFT_DATASET, f)
- sft_dataset = SupervisedDataset(
- tokenizer=tokenizer,
- data_path=os.path.join(tmp_dir, dataset_name),
- max_datasets_size=max_dataset_size,
- max_length=max_length,
- )
- assert len(sft_dataset) == min(max_dataset_size, len(SFT_DATASET))
-
- if isinstance(tokenizer, ChatGLMTokenizer):
- for i in range(max_dataset_size):
- assert isinstance(sft_dataset[i], dict)
- assert list(sft_dataset[i].keys()) == ["input_ids", "labels"]
- input_ids = sft_dataset[i]["input_ids"]
- labels = sft_dataset[i]["labels"]
- assert input_ids.shape == labels.shape == torch.Size([max_length])
-
- ignore_mask = labels == IGNORE_INDEX
- assert input_ids.masked_select(torch.logical_not(ignore_mask))[0] == tokenizer.bos_token_id
- check_content(input_ids.masked_select(torch.logical_not(ignore_mask)), tokenizer, model)
- return
-
- for i in range(max_dataset_size):
- assert isinstance(sft_dataset[i], dict)
- assert list(sft_dataset[i].keys()) == ["input_ids", "labels", "attention_mask"]
- input_ids = sft_dataset[i]["input_ids"]
- labels = sft_dataset[i]["labels"]
- attention_mask = sft_dataset[i]["attention_mask"].to(torch.bool)
- assert input_ids.shape == labels.shape == attention_mask.shape == torch.Size([max_length])
- if input_ids.masked_select(attention_mask)[-1] == tokenizer.eos_token_id:
- check_content(input_ids.masked_select(attention_mask)[:-1], tokenizer, model)
- assert torch.all(input_ids.masked_select(torch.logical_not(attention_mask)) == tokenizer.pad_token_id)
- else:
- check_content(input_ids.masked_select(attention_mask), tokenizer, model)
- assert torch.all(attention_mask)
- ignore_mask = labels == IGNORE_INDEX
- prompt_mask = torch.logical_and(ignore_mask, attention_mask)
- check_content(input_ids.masked_select(prompt_mask), tokenizer, model)
- assert torch.all(input_ids.masked_select(ignore_mask ^ prompt_mask) == tokenizer.pad_token_id)
-
-
-if __name__ == "__main__":
- test_sft_dataset(model="bloom", dataset_path="yizhongw/self_instruct", max_dataset_size=2, max_length=256)
-
- test_reward_dataset(
- model="gpt2", dataset_path="Anthropic/hh-rlhf", subset="harmless-base", max_datasets_size=8, max_length=256
- )
-
- test_prompt_dataset(model="opt", max_datasets_size=2, max_length=128)
diff --git a/applications/Chat/tests/test_experience.py b/applications/Chat/tests/test_experience.py
deleted file mode 100644
index a9591259800d..000000000000
--- a/applications/Chat/tests/test_experience.py
+++ /dev/null
@@ -1,130 +0,0 @@
-import copy
-import os
-
-import pytest
-import torch
-import torch.distributed as dist
-from coati.experience_buffer import NaiveExperienceBuffer
-from coati.experience_maker import NaiveExperienceMaker
-from coati.models.base import RewardModel
-from coati.models.gpt import GPTActor, GPTCritic
-from coati.trainer.ppo import _set_default_generate_kwargs
-from coati.trainer.strategies import DDPStrategy, GeminiStrategy
-from coati.trainer.strategies.colossalai import LowLevelZeroStrategy
-from transformers.models.gpt2.configuration_gpt2 import GPT2Config
-
-from colossalai.testing import rerun_if_address_is_in_use, spawn
-
-GPT_CONFIG = GPT2Config(n_embd=128, n_layer=4, n_head=4)
-
-
-def get_data(batch_size: int, seq_len: int = 10) -> dict:
- input_ids = torch.randint(0, 50257, (batch_size, seq_len), device="cuda")
- attention_mask = torch.ones_like(input_ids)
- return dict(input_ids=input_ids, attention_mask=attention_mask)
-
-
-def gather_and_equal(tensor: torch.Tensor) -> bool:
- world_size = dist.get_world_size()
- outputs = [torch.empty_like(tensor) for _ in range(world_size)]
- dist.all_gather(outputs, tensor.contiguous())
- for t in outputs[1:]:
- if not torch.equal(outputs[0], t):
- return False
- return True
-
-
-def make_and_consume_experience(strategy):
- EXPERIENCE_BATCH_SIZE = 4
- SAMPLE_BATCH_SIZE = 2
-
- if strategy == "ddp":
- strategy = DDPStrategy()
- elif strategy == "colossalai-zero2":
- strategy = LowLevelZeroStrategy()
- elif strategy == "colossalai-gemini":
- strategy = GeminiStrategy(placement_policy="static")
- else:
- raise ValueError(f'Unsupported strategy "{strategy}"')
-
- with strategy.model_init_context():
- actor = GPTActor(config=GPT_CONFIG).cuda()
- critic = GPTCritic(config=GPT_CONFIG).cuda()
-
- initial_model = GPTActor(config=GPT_CONFIG).cuda()
- reward_model = RewardModel(model=copy.deepcopy(critic.model)).cuda()
-
- actor, critic, initial_model, reward_model = strategy.prepare(actor, critic, initial_model, reward_model)
-
- class MockTokenizer:
- def __init__(self):
- self.padding_side = "left"
- self.eos_token_id = 0
- self.pad_token_id = 0
-
- tokenizer = MockTokenizer()
- experience_maker = NaiveExperienceMaker(actor, critic, reward_model, initial_model, tokenizer)
- data_buffer = NaiveExperienceBuffer(SAMPLE_BATCH_SIZE, cpu_offload=False)
-
- generate_kwargs = dict(do_sample=True, max_length=16)
- generate_kwargs = _set_default_generate_kwargs(strategy, generate_kwargs, actor)
-
- # experience of all ranks should be the same
- for _ in range(2):
- data = get_data(EXPERIENCE_BATCH_SIZE)
- assert gather_and_equal(data["input_ids"])
- assert gather_and_equal(data["attention_mask"])
- experience = experience_maker.make_experience(**data, do_sample=True, max_length=16)
- assert gather_and_equal(experience.sequences)
- assert gather_and_equal(experience.action_log_probs)
- assert gather_and_equal(experience.values)
- assert gather_and_equal(experience.reward)
- assert gather_and_equal(experience.advantages)
- assert gather_and_equal(experience.action_mask)
- assert gather_and_equal(experience.attention_mask)
- data_buffer.append(experience)
-
- # data buffer's data should be the same
- buffer_size = torch.tensor([len(data_buffer)], device="cuda")
- assert gather_and_equal(buffer_size)
- for item in data_buffer.items:
- assert gather_and_equal(item.sequences)
- assert gather_and_equal(item.action_log_probs)
- assert gather_and_equal(item.values)
- assert gather_and_equal(item.reward)
- assert gather_and_equal(item.advantages)
- assert gather_and_equal(item.action_mask)
- assert gather_and_equal(item.attention_mask)
-
- # dataloader of each rank should have the same size and different batch
- dataloader = strategy.setup_dataloader(data_buffer)
- dataloader_size = torch.tensor([len(dataloader)], device="cuda")
- assert gather_and_equal(dataloader_size)
- for experience in dataloader:
- assert not gather_and_equal(experience.sequences)
- assert not gather_and_equal(experience.action_log_probs)
- assert not gather_and_equal(experience.values)
- assert not gather_and_equal(experience.reward)
- assert not gather_and_equal(experience.advantages)
- # action mask and attention mask may be same
-
-
-def run_dist(rank, world_size, port, strategy):
- os.environ["RANK"] = str(rank)
- os.environ["LOCAL_RANK"] = str(rank)
- os.environ["WORLD_SIZE"] = str(world_size)
- os.environ["MASTER_ADDR"] = "localhost"
- os.environ["MASTER_PORT"] = str(port)
- make_and_consume_experience(strategy)
-
-
-@pytest.mark.dist
-@pytest.mark.parametrize("world_size", [2])
-@pytest.mark.parametrize("strategy", ["ddp", "colossalai-zero2", "colossalai-gemini"])
-@rerun_if_address_is_in_use()
-def test_experience(world_size, strategy):
- spawn(run_dist, world_size, strategy=strategy)
-
-
-if __name__ == "__main__":
- test_experience(2, "colossalai-zero2")
diff --git a/applications/Chat/tests/test_inference.sh b/applications/Chat/tests/test_inference.sh
deleted file mode 100755
index 849db06e58ab..000000000000
--- a/applications/Chat/tests/test_inference.sh
+++ /dev/null
@@ -1,11 +0,0 @@
-set -xue
-
-BASE_DIR=$(dirname $(dirname $(realpath $BASH_SOURCE)))
-EXAMPLES_DIR=$BASE_DIR/examples
-
-echo "[Test]: testing inference ..."
-
-# HACK: skip llama due to oom
-for model in 'gpt2' 'bloom' 'opt'; do
- python $EXAMPLES_DIR/inference.py --model $model
-done
diff --git a/applications/Chat/tests/test_models.py b/applications/Chat/tests/test_models.py
deleted file mode 100644
index b2c22ac6a3b9..000000000000
--- a/applications/Chat/tests/test_models.py
+++ /dev/null
@@ -1,245 +0,0 @@
-import copy
-from typing import Any, Callable, Dict, Tuple
-
-import pytest
-import torch
-import torch.nn as nn
-from coati.models.base import Actor, Critic, RewardModel, get_base_model
-from coati.models.bloom import BLOOMRM, BLOOMActor, BLOOMCritic
-from coati.models.chatglm import ChatGLMActor
-from coati.models.chatglm.chatglm_tokenizer import ChatGLMTokenizer
-from coati.models.generation import generate
-from coati.models.gpt import GPTRM, GPTActor, GPTCritic
-from coati.models.llama import LlamaActor
-from coati.models.lora import LoraLinear, convert_to_lora_module
-from coati.models.loss import GPTLMLoss, LogExpLoss, LogSigLoss, PolicyLoss, ValueLoss
-from coati.models.opt import OPTRM, OPTActor, OPTCritic
-from coati.models.utils import calc_action_log_probs, masked_mean
-
-
-@pytest.mark.parametrize("batch_size", [4])
-@pytest.mark.parametrize("seq_len", [32])
-@pytest.mark.parametrize(
- "actor_maker",
- [
- lambda: BLOOMActor(),
- lambda: GPTActor(),
- # HACK: skip llama due to long execution time
- # lambda: LlamaActor(),
- lambda: OPTActor(),
- ],
-)
-@pytest.mark.parametrize(
- "generate_kwargs",
- [
- {
- "max_length": 64,
- "use_cache": True,
- "do_sample": True,
- "temperature": 1.0,
- "top_k": 50,
- }
- ],
-)
-def test_generation(actor_maker: Callable[[], Actor], batch_size: int, seq_len: int, generate_kwargs: Dict[str, Any]):
- class MockTokenizer:
- def __init__(self):
- self.padding_side = "left"
- self.eos_token_id = 0
- self.pad_token_id = 0
-
- actor = actor_maker()
- input_ids = torch.randint(0, 100, (batch_size, seq_len)).cuda()
- tokenizer = MockTokenizer()
- sequences = generate(actor.cuda(), input_ids, tokenizer, **generate_kwargs)
- assert sequences.shape == (batch_size, generate_kwargs["max_length"])
-
-
-def test_utils():
- fn_input = {"tensor": torch.ones((10,)), "mask": torch.randint(0, 2, (10,))}
- fn_output = masked_mean(dim=0, **fn_input)
- assert fn_output.dim() == 0
- assert torch.allclose(fn_output, torch.tensor(1.0))
-
- batch_size = 4
- seq_len = 32
- num_labels = 10
- num_actions = 2
- fn_input = {
- "logits": torch.randn((batch_size, seq_len, num_labels)),
- "sequences": torch.randint(0, num_labels, (batch_size, seq_len)),
- "num_actions": num_actions,
- }
- fn_output = calc_action_log_probs(**fn_input)
- assert fn_output.shape == (batch_size, num_actions)
-
-
-@pytest.mark.parametrize("lora_rank", [4])
-@pytest.mark.parametrize("num_dim", [32])
-@pytest.mark.parametrize("num_layers", [4])
-def test_lora(lora_rank: int, num_dim: int, num_layers: int):
- model = nn.ModuleList([nn.Linear(num_dim, num_dim) for _ in range(num_layers)])
- lora_model = convert_to_lora_module(model, lora_rank)
- assert isinstance(lora_model, nn.ModuleList)
- for i in range(num_layers):
- assert isinstance(lora_model[i], LoraLinear)
- assert lora_model[i].lora_A.shape == (lora_rank, num_dim)
- assert lora_model[i].lora_B.shape == (num_dim, lora_rank)
-
- old_model = copy.deepcopy(lora_model)
- for i in range(num_layers):
- assert isinstance(lora_model[i], LoraLinear)
- assert torch.allclose(old_model[i].weight, lora_model[i].weight)
- assert torch.allclose(old_model[i].bias, lora_model[i].bias)
- assert torch.allclose(old_model[i].lora_B @ old_model[i].lora_A, lora_model[i].lora_B @ lora_model[i].lora_A)
- optimizer = torch.optim.Adam(lora_model.parameters())
- x = torch.randn(8, num_dim)
- for i in range(num_layers):
- x = lora_model[i](x)
- loss = x.sum()
- loss.backward()
- optimizer.step()
- for i in range(num_layers):
- assert isinstance(lora_model[i], LoraLinear)
- assert torch.allclose(old_model[i].weight, lora_model[i].weight)
- assert torch.allclose(old_model[i].bias, lora_model[i].bias)
- assert not torch.allclose(
- old_model[i].lora_B @ old_model[i].lora_A, lora_model[i].lora_B @ lora_model[i].lora_A
- )
-
-
-@pytest.mark.parametrize("batch_size", [8])
-@pytest.mark.parametrize("seq_len", [128])
-@pytest.mark.parametrize(
- "models_maker",
- [
- lambda: (BLOOMActor(), BLOOMCritic(), BLOOMRM()),
- lambda: (GPTActor(), GPTCritic(), GPTRM()),
- # HACK: skip llama due to long execution time
- # lambda: (LlamaActor(), LlamaCritic(), LlamaRM()),
- lambda: (OPTActor(), OPTCritic(), OPTRM()),
- lambda: (ChatGLMActor(), None, None),
- ],
-)
-@torch.no_grad()
-def test_models(models_maker: Callable[[], Tuple[Actor, Critic, RewardModel]], batch_size: int, seq_len: int):
- actor_input = {
- "input_ids": torch.randint(0, 100, (batch_size, seq_len)),
- "attention_mask": torch.randint(0, 2, (batch_size, seq_len)),
- }
- critic_input = {
- "sequences": torch.randint(0, 100, (batch_size, seq_len)),
- "attention_mask": torch.randint(0, 2, (batch_size, seq_len)),
- }
- rm_input = {
- "sequences": torch.randint(0, 100, (batch_size, seq_len)),
- "attention_mask": torch.randint(0, 2, (batch_size, seq_len)),
- }
-
- actor, critic, rm = models_maker()
- if isinstance(actor, ChatGLMActor):
- actor = actor.float()
- tokenizer = ChatGLMTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
- chatglm_special_token = torch.tensor([tokenizer.gmask_token_id, tokenizer.bos_token_id]).repeat(batch_size, 1)
- actor_input = {
- "input_ids": torch.cat(
- (
- torch.randint(0, 100, (batch_size, seq_len // 2)),
- chatglm_special_token,
- torch.randint(0, 100, (batch_size, seq_len // 2 - 2)),
- ),
- dim=1,
- ),
- "attention_mask": torch.randint(0, 2, (batch_size, 1, seq_len, seq_len)),
- }
- assert isinstance(actor, Actor)
- get_base_model(actor)
- actor_output = actor(**actor_input)
- assert actor_output.logits.shape[:2] == (batch_size, seq_len)
-
- if critic:
- assert isinstance(critic, Critic)
- get_base_model(critic)
- critic_output = critic(**critic_input)
- assert critic_output.shape == (batch_size,)
-
- if rm:
- assert isinstance(rm, RewardModel)
- get_base_model(rm)
- rm_output = rm(**rm_input)
- assert rm_output.shape == (batch_size,)
-
-
-@pytest.mark.parametrize("batch_size", [16])
-@pytest.mark.parametrize("seq_len", [128])
-@pytest.mark.parametrize("num_labels", [100])
-def test_loss(batch_size: int, seq_len: int, num_labels: int):
- loss = GPTLMLoss()
- loss_input = {
- "logits": torch.randn(batch_size, seq_len, num_labels),
- "labels": torch.randint(0, num_labels, (batch_size, seq_len)),
- }
- loss(**loss_input)
-
- loss = PolicyLoss()
- loss_input = {
- "log_probs": torch.randn(
- batch_size,
- ),
- "old_log_probs": torch.randn(
- batch_size,
- ),
- "advantages": torch.randn(
- batch_size,
- ),
- }
- loss(**loss_input)
-
- loss = ValueLoss()
- loss_input = {
- "values": torch.randn(
- batch_size,
- ),
- "old_values": torch.randn(
- batch_size,
- ),
- "reward": torch.randn(
- batch_size,
- ),
- }
- loss(**loss_input)
-
- loss = LogSigLoss()
- loss_input = {
- "chosen_reward": torch.randn(
- batch_size,
- ),
- "reject_reward": torch.randn(
- batch_size,
- ),
- }
- loss(**loss_input)
-
- loss = LogExpLoss()
- loss_input = {
- "chosen_reward": torch.randn(
- batch_size,
- ),
- "reject_reward": torch.randn(
- batch_size,
- ),
- }
- loss(**loss_input)
-
-
-if __name__ == "__main__":
- generate_kwargs = dict(max_length=40, use_cache=True, do_sample=True, temperature=1.0, top_k=50)
- test_generation(lambda: LlamaActor(), batch_size=4, seq_len=32, generate_kwargs=generate_kwargs)
-
- test_utils()
-
- test_lora(lora_rank=2, num_dim=8, num_layers=2)
-
- test_models(models_maker=lambda: (BLOOMActor(), BLOOMCritic(), BLOOMRM()), batch_size=8, seq_len=128)
-
- test_loss(batch_size=8, seq_len=128, num_labels=100)
diff --git a/applications/Chat/tests/test_train.sh b/applications/Chat/tests/test_train.sh
deleted file mode 100755
index 68fca7fbf8c0..000000000000
--- a/applications/Chat/tests/test_train.sh
+++ /dev/null
@@ -1,233 +0,0 @@
-#!/usr/bin/env bash
-
-set_n_least_used_CUDA_VISIBLE_DEVICES() {
- local n=${1:-"9999"}
- echo "GPU Memory Usage:"
- local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv |
- tail -n +2 |
- nl -v 0 |
- tee /dev/tty |
- sort -g -k 2 |
- awk '{print $1}' |
- head -n $n)
- export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
- echo "Now CUDA_VISIBLE_DEVICES is set to:"
- echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
-}
-
-set_n_least_used_CUDA_VISIBLE_DEVICES 4
-
-set -xu
-
-if [ -z "$SFT_DATASET" ]; then
- echo "Please set \$SFT_DATASET to the path to sft dataset."
- exit 1
-fi
-
-if [ -z "$PROMPT_DATASET" ]; then
- echo "Please set \$PROMPT_DATASET to the path to prompts csv."
- exit 1
-fi
-
-if [ -z "$PRETRAIN_DATASET" ]; then
- echo "Please set \$PRETRAIN_DATASET to the path to alpaca data."
- exit 1
-fi
-
-NUM_RETRY=3
-BASE_DIR=$(dirname $(dirname $(realpath $BASH_SOURCE)))
-EXAMPLES_DIR=$BASE_DIR/examples
-MODELS_DIR=$BASE_DIR/examples/models_config
-MODELS=('gpt2' 'bloom' 'opt' 'llama')
-STRATEGIES=('ddp' 'colossalai_gemini' 'colossalai_zero2')
-
-
-export OMP_NUM_THREADS=8
-
-# install requirements
-pip install -r $EXAMPLES_DIR/requirements.txt
-
-python $EXAMPLES_DIR/download_model.py --model-dir $MODELS_DIR --config-only
-
-get_pretrain() {
- local model=$1
- if [[ $model == "gpt2" ]]; then
- echo "gpt2"
- elif [[ $model == "bloom" ]]; then
- echo "bigscience/bloom-560m"
- elif [[ $model == "opt" ]]; then
- echo "facebook/opt-350m"
- else
- echo "Unknown model $model"
- exit 1
- fi
-}
-
-random_choice() {
- local arr=("$@")
- local len=${#arr[@]}
- local idx=$((RANDOM % len))
- echo ${arr[$idx]}
-}
-
-echo "[Test]: testing sft ..."
-
-# FIXME: This is a hack to skip tests that are not working
-# - gpt2-ddp: RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
-# - llama-*: These tests can be passed locally, skipped for long execution time
-# - *-gemini: Gemini plugin does not support `from_pretrained` yet
-SKIPPED_TESTS=(
- "gpt2-ddp"
- "llama-ddp"
- "llama-colossalai_gemini"
- "llama-colossalai_zero2"
-)
-
-GRAD_CKPTS=('' '--grad_checkpoint')
-for lora_rank in '0'; do
- for model in ${MODELS[@]}; do
- strategies=($(shuf -e "${STRATEGIES[@]}"))
- for strategy in ${strategies[@]}; do
- if [[ " ${SKIPPED_TESTS[*]} " =~ " $model-$strategy-$lora_rank " ]]; then
- echo "[Test]: Skipped $model-$strategy-$lora_rank"
- continue
- elif [[ " ${SKIPPED_TESTS[*]} " =~ " $model-$strategy " ]]; then
- echo "[Test]: Skipped $model-$strategy"
- continue
- fi
- pretrain=$(get_pretrain $model)
- pretrain_model=""
- if [[ $lora_rank -gt 0 ]]; then
- pretrain_model="--pretrain $pretrain"
- fi
- grad_ckpt=$(random_choice "${GRAD_CKPTS[@]}")
- for i in $(seq $NUM_RETRY); do
- echo "[Test]: $model-$strategy-$lora_rank, attempt $i"
- torchrun --standalone --nproc_per_node=4 $EXAMPLES_DIR/train_sft.py \
- $pretrain_model --tokenizer $MODELS_DIR/$model \
- --model $model --strategy $strategy --lora_rank $lora_rank $grad_ckpt \
- --dataset $SFT_DATASET --max_datasets_size 8 \
- --max_epochs 1 --batch_size 1 --accumulation_steps 1 --lr 1e-8 \
- --save_path $EXAMPLES_DIR/rlhf_models/sft_ckpt_${model}_${lora_rank}
- passed=$?
- if [ $passed -eq 0 ]; then
- break
- fi
- done
- if [ $passed -ne 0 ]; then
- echo "[Test]: Failed $model-$strategy-$lora_rank"
- exit 1
- fi
- done
- done
-done
-
-echo "[Test]: testing reward model ..."
-
-# FIXME: This is a hack to skip tests that are not working
-# - gpt2-ddp: RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
-# - llama-*: These tests can be passed locally, skipped for long execution time
-# - *-gemini: Gemini plugin does not support `from_pretrained` yet
-SKIPPED_TESTS=(
- "gpt2-ddp"
- "llama-ddp"
- "llama-colossalai_gemini"
- "llama-colossalai_zero2"
-)
-
-LOSS_FNS=('log_sig' 'log_exp')
-DATASETS=('Anthropic/hh-rlhf' 'Dahoas/rm-static')
-for lora_rank in '0'; do
- for model in ${MODELS[@]}; do
- strategies=($(shuf -e "${STRATEGIES[@]}"))
- for strategy in ${strategies[@]}; do
- if [[ " ${SKIPPED_TESTS[*]} " =~ " $model-$strategy-$lora_rank " ]]; then
- echo "[Test]: Skipped $model-$strategy-$lora_rank"
- continue
- elif [[ " ${SKIPPED_TESTS[*]} " =~ " $model-$strategy " ]]; then
- echo "[Test]: Skipped $model-$strategy"
- continue
- fi
- pretrain=$(get_pretrain $model)
- pretrain_model=""
- if [[ $lora_rank -gt 0 ]]; then
- pretrain_model="--pretrain $pretrain"
- fi
- loss_fn=$(random_choice "${LOSS_FNS[@]}")
- dataset=$(random_choice "${DATASETS[@]}")
- subset=$(if [[ $dataset == "Dahoas/rm-static" ]]; then echo "None"; else echo "harmless-base"; fi)
- for i in $(seq $NUM_RETRY); do
- echo "[Test]: $model-$strategy-$lora_rank, attempt $i"
- torchrun --standalone --nproc_per_node=4 $EXAMPLES_DIR/train_reward_model.py \
- $pretrain_model --tokenizer $MODELS_DIR/$model \
- --dataset $dataset --subset $subset --max_datasets_size 8 \
- --model $model --strategy $strategy --lora_rank $lora_rank \
- --loss_fn $loss_fn --batch_size 1 --lr 1e-8 \
- --save_path $EXAMPLES_DIR/rlhf_models/rm_ckpt_${model}_${lora_rank}.pt
- passed=$?
- if [ $passed -eq 0 ]; then
- break
- fi
- done
- if [ $passed -ne 0 ]; then
- echo "[Test]: Failed to train reward model $model-$strategy-$lora_rank"
- exit 1
- fi
- done
- done
-done
-
-echo "[Test]: testing RLHF ..."
-
-# FIXME: This is a hack to skip tests that are not working
-# - gpt2-ddp: RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
-# - llama-*: These tests can be passed locally, skipped for long execution time
-# - *-gemini: Gemini plugin does not support `from_pretrained` yet
-SKIPPED_TESTS=(
- "gpt2-ddp"
- "llama-ddp"
- "llama-colossalai_gemini"
- "llama-colossalai_zero2"
-)
-
-for model in ${MODELS[@]}; do
- for lora_rank in '0'; do
- strategies=($(shuf -e "${STRATEGIES[@]}"))
- for strategy in ${strategies[@]}; do
- if [[ " ${SKIPPED_TESTS[*]} " =~ " $model-$strategy-$lora_rank " ]]; then
- echo "[Test]: Skipped $model-$strategy-$lora_rank"
- continue
- elif [[ " ${SKIPPED_TESTS[*]} " =~ " $model-$strategy " ]]; then
- echo "[Test]: Skipped $model-$strategy"
- continue
- fi
- rm_pretrain=$(get_pretrain $model)
- rm_pretrain_model=""
- if [[ $lora_rank -gt 0 ]]; then
- rm_pretrain_model="--rm_pretrain $rm_pretrain"
- fi
- for i in $(seq $NUM_RETRY); do
- echo "[Test]: $model-$strategy-$lora_rank, attempt $i"
- torchrun --standalone --nproc_per_node=4 $EXAMPLES_DIR/train_prompts.py \
- --prompt_dataset $PROMPT_DATASET --pretrain_dataset $PRETRAIN_DATASET --max_datasets_size 32 \
- --strategy $strategy --model $model --tokenizer $MODELS_DIR/$model \
- --num_episodes 1 --num_collect_steps 1 --num_update_steps 1 --lr 1e-8 \
- --experience_batch_size 2 --train_batch_size 1 --lora_rank $lora_rank \
- --pretrain $EXAMPLES_DIR/rlhf_models/sft_ckpt_${model}_${lora_rank} \
- $rm_pretrain_model --rm_path $EXAMPLES_DIR/rlhf_models/rm_ckpt_${model}_${lora_rank}.pt \
- --save_path $EXAMPLES_DIR/rlhf_models/actor_checkpoint_prompts
- passed=$?
- if [ $passed -eq 0 ]; then
- break
- fi
- done
- if [ $passed -ne 0 ]; then
- echo "[Test]: Failed to train RLHF $model-$strategy-$lora_rank"
- exit 1
- fi
- done
- rm -rf $EXAMPLES_DIR/rlhf_models/sft_ckpt_${model}_${lora_rank}
- rm $EXAMPLES_DIR/rlhf_models/rm_ckpt_${model}_${lora_rank}.pt
- done
-done
-rm -rf $EXAMPLES_DIR/rlhf_models/actor_checkpoint_prompts
diff --git a/applications/Colossal-LLaMA-2/README.md b/applications/Colossal-LLaMA-2/README.md
index ac7593d98797..1377e1facec0 100644
--- a/applications/Colossal-LLaMA-2/README.md
+++ b/applications/Colossal-LLaMA-2/README.md
@@ -5,60 +5,102 @@
## Table of Contents
+- [Table of Contents](#table-of-contents)
- [News](#news)
- [Colossal-LLaMA-2-7B](#colossal-llama-2-7b)
- - [Performance Evaluation](#performance-evaluation)
- - [Examples](#examples)
- - [Training Logs](#training-logs)
- - [Import from Transformers](#import-from-transformers)
+- [Colossal-LLaMA-2-13B](#colossal-llama-2-13b)
+ - [Performance Evaluation](#performance-evaluation)
+ - [Model with ~7 Billion Parameters](#model-with-7-billion-parameters)
+ - [Model with ~13 Billion Parameters](#model-with-13-billion-parameters)
+ - [Examples](#examples)
+ - [Training Logs](#training-logs)
+ - [Colossal-LLaMA-2-7b-base](#colossal-llama-2-7b-base)
+ - [Colossal-LLaMA-2-13b-base](#colossal-llama-2-13b-base)
+ - [Inference](#inference)
+ - [Import from HuggingFace](#import-from-huggingface)
+ - [Import from Modelscope](#import-from-modelscope)
+ - [Quick Start](#quick-start)
- [Usage](#usage)
- - [Install](#install)
- - [How to run](#how-to-run)
-- [Technical Insight](#technical-insights)
- - [Data](#data)
- - [Tokenizer](#tokenizer)
- - [Training Strategy](#training-strategy)
- - [Bridging Any Domain-specific Large Models](#bridging-any-domain-specific-large-models)
+ - [Install](#install)
+ - [0. Pre-requisite](#0-pre-requisite)
+ - [1. Install required packages](#1-install-required-packages)
+ - [2. Install `xentropy`, `layer_norm` and `rotary`](#2-install-xentropy-layer_norm-and-rotary)
+ - [How to run](#how-to-run)
+ - [1. Init Tokenizer Preparation](#1-init-tokenizer-preparation)
+ - [2. Init Model Preparation](#2-init-model-preparation)
+ - [3. Data Preparation](#3-data-preparation)
+ - [3.1 Data for Pretraining](#31-data-for-pretraining)
+ - [3.2 Data for Supervised Fine-tuning](#32-data-for-supervised-fine-tuning)
+ - [4. Command Line Arguments for Training](#4-command-line-arguments-for-training)
+ - [4.1 Arguments for Pretraining](#41-arguments-for-pretraining)
+ - [4.2 Arguments for Supervised Fine-tuning](#42-arguments-for-supervised-fine-tuning)
+ - [5. Running Command](#5-running-command)
+ - [5.1 Command for Pretraining](#51-command-for-pretraining)
+ - [5.2 Command for Supervised Fine-tuning](#52-command-for-supervised-fine-tuning)
+- [Technical Insights](#technical-insights)
+ - [Data](#data)
+ - [Tokenizer](#tokenizer)
+ - [Training Strategy](#training-strategy)
+ - [Multi-stage Training](#multi-stage-training)
+ - [Bucket-based Training](#bucket-based-training)
+ - [Bridging Any Domain-specific Large Models](#bridging-any-domain-specific-large-models)
- [Citations](#citations)
## News
-* [2023/09] [One Half-Day of Training Using a Few Hundred Dollars Yields Similar Results to Mainstream Large Models, Open-Source and Commercial-Free Domain-Specific Llm Solution](https://www.hpc-ai.tech/blog/one-half-day-of-training-using-a-few-hundred-dollars-yields-similar-results-to-mainstream-large-models-open-source-and-commercial-free-domain-specific-llm-solution)
+* [2024/01] [Construct Refined 13B Private Model With Just $5000 USD, Upgraded Colossal-AI Llama-2 Open Source](https://hpc-ai.com/blog/colossal-llama-2-13b).
+[[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Colossal-LLaMA-2)
+[[blog]](https://hpc-ai.com/blog/colossal-llama-2-13b)
+[[HuggingFace model weights]](https://huggingface.co/hpcai-tech/Colossal-LLaMA-2-13b-base)
+[[Modelscope model weights]](https://www.modelscope.cn/models/colossalai/Colossal-LLaMA-2-13b-base/summary)
+* [2023/09] [One Half-Day of Training Using a Few Hundred Dollars Yields Similar Results to Mainstream Large Models, Open-Source and Commercial-Free Domain-Specific Llm Solution](https://www.hpc-ai.tech/blog/one-half-day-of-training-using-a-few-hundred-dollars-yields-similar-results-to-mainstream-large-models-open-source-and-commercial-free-domain-specific-llm-solution).
[[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Colossal-LLaMA-2)
[[blog]](https://www.hpc-ai.tech/blog/one-half-day-of-training-using-a-few-hundred-dollars-yields-similar-results-to-mainstream-large-models-open-source-and-commercial-free-domain-specific-llm-solution)
[[HuggingFace model weights]](https://huggingface.co/hpcai-tech/Colossal-LLaMA-2-7b-base)
[[Modelscope model weights]](https://www.modelscope.cn/models/colossalai/Colossal-LLaMA-2-7b-base/summary)
-
## Colossal-LLaMA-2-7B
The [Colossal-AI](https://github.com/hpcaitech/ColossalAI) team has introduced the open-source model **Colossal-LLaMA-2-7B-base**. This model, a derivation of LLaMA-2, has undergone continual pre-training involving approximately 8.5 billion tokens over a duration of 15 hours with 64 A800 GPUs. At a cost of **less than $1,000**, you can achieve results **similar to those that cost millions of dollars to pretrain from scratch**. It is licensed under the LLaMA-2 license and [Apache 2.0 License](https://github.com/hpcaitech/ColossalAI/blob/main/LICENSE) **without any additional commercial use restrictions**. This solution can also be used to build models of specific domain knowledge or tasks.
Colossal-LLaMA-2-7B-base is designed to accommodate both the Chinese and English languages, featuring an expansive context window spanning 4096 tokens. Remarkably, it has exhibited exceptional performance when benchmarked against models of equivalent scale in standard Chinese and English evaluation metrics, including C-Eval and MMLU, among others.
+
+## Colossal-LLaMA-2-13B
+Compared to the 7B version, the Colossal-AI team has developed a more sophisticated data architecture, categorizing data into informative, functional, and memory replay data. Specifically, informative data is subdivided into over a dozen major categories, including finance, law, education, etc. Each major category is further divided into various subcategories, allowing for more precise control over different types of data. Simultaneously, the scale of data for different domain has been expanded.
+
+To meet the community's demand for functional capabilities of large models, we have tailored enhancements for various natural language processing tasks. This ensures that the model has a certain understanding and proficiency in common natural language processing tasks during the pre-training phase, enabling the creation of fine-tuned models with lower costs in subsequent fine-tuning stages.
+
+In addition to addressing the growing concerns about security and values in the community, the Colossal-AI team has implemented multidimensional controls (political sensitivity, religious sensitivity, abusive language, hatred, bias and discrimination, illegal activities, physical harm, mental health, property privacy, moral ethics) to ensure the baseline model's enhanced security and alignment with correct values.
+
+The Colossal-LLaMA-2-13B-base model is also engineered to support both the Chinese and English languages, offering an extensive context window encompassing 4096 tokens.Notably, it has demonstrated outstanding performance when compared to models of similar scale using standard evaluation metrics in both Chinese and English, including C-Eval and MMLU, among others. It is licensed under the LLaMA-2 license and [Apache 2.0 License](https://github.com/hpcaitech/ColossalAI/blob/main/LICENSE) **without any additional commercial use restrictions**. This solution can also be used to build models of specific domain knowledge or tasks.
+
❗️**Important notice**:
* All training data used for this project is collected from well-known public dataset.
* We do not use any testing data from the evaluation benchmarks for training.
### Performance Evaluation
-We conducted comprehensive evaluation on 4 dataset and compare our Colossal-Llama-2-7b-base model with various models.
-* We use 5-shot for MMLU and calculate scores based on the logits of first predicted token.
-* We use 5-shot for CMMLU and calculate scores based on the logits of first predicted token.
-* We use 5-shot for AGIEval and only calculate scores for 4-choice questions using a combination metric of exact match and the logits of first predicted token. If any of the exact match or logits of first predicted token is correct, the model will get the score.
-* We use 0-shot for GAOKAO-Bench and only calculate scores for 4-choice questions based on the logits of first predicted token.
-The generation config for all dataset is greedy search.
-* We also provided CEval scores from its lastest leaderboard or the official repository of the model.
+#### Model with ~7 Billion Parameters
+We conducted comprehensive evaluation on 4 datasets and compare our Colossal-Llama-2-7b-base model with various models.
+
+- We use 5-shot for MMLU and calculate scores based on the logits of first predicted token.
+- We use 5-shot for CMMLU and calculate scores based on the logits of first predicted token.
+- We use 5-shot for AGIEval and only calculate scores for 4-choice questions using a combination metric of exact match and the logits of first predicted token. If any of the exact match or logits of first predicted token is correct, the model will get the score.
+- We use 0-shot for GAOKAO-Bench and only calculate scores for 4-choice questions based on the logits of first predicted token.
+- The generation config for all dataset is greedy search.
+- We also provided CEval scores from its latest leaderboard or the official repository of the model.
+
+More details about metrics can be found in [Metrics](https://github.com/hpcaitech/ColossalAI/tree/main/applications/ColossalEval#metrics).
| | Backbone | Tokens Consumed | | MMLU | CMMLU | AGIEval | GAOKAO | CEval |
-| :----------------------------: | :--------: | :-------------: | :------------------: | :-----------: | :-----: | :----: | :----: | :------------------------------: |
-| | | - | | 5-shot | 5-shot | 5-shot | 0-shot | 5-shot |
+| :----------------------------: | :--------: | :-------------: | :------------------: | :-----------: | :-----: | :----: | :----: | :----------------------------: |
+| | - | - | | 5-shot | 5-shot | 5-shot | 0-shot | 5-shot |
| Baichuan-7B | - | 1.2T | | 42.32 (42.30) | 44.53 (44.02) | 38.72 | 36.74 | 42.80 |
-| Baichuan-13B-Base | - | 1.4T | | 50.51 (51.60) | 55.73 (55.30) | 47.20 | 51.41 | 53.60 |
| Baichuan2-7B-Base | - | 2.6T | | 46.97 (54.16) | 57.67 (57.07) | 45.76 | 52.60 | 54.00 |
-| Baichuan2-13B-Base | - | 2.6T | | 54.84 (59.17) | 62.62 (61.97) | 52.08 | 58.25 | 58.10 |
| ChatGLM-6B | - | 1.0T | | 39.67 (40.63) | 41.17 (-) | 40.10 | 36.53 | 38.90 |
| ChatGLM2-6B | - | 1.4T | | 44.74 (45.46) | 49.40 (-) | 46.36 | 45.49 | 51.70 |
-| InternLM-7B | - | 1.6T | | 46.70 (51.00) | 52.00 (-) | 44.77 | 61.64 | 52.80 |
+| InternLM-7B | - | - | | 46.70 (51.00) | 52.00 (-) | 44.77 | 61.64 | 52.80 |
| Qwen-7B (original) | - | 2.2T | | 54.29 (56.70) | 56.03 (58.80) | 52.47 | 56.42 | 59.60 |
+| Qwen-7B | - | 2.4T | | 58.33 (58.20) | 62.54 (62.20) | 64.34 | 74.05 | 63.50 |
| | | | | | | | | |
| Llama-2-7B | - | 2.0T | | 44.47 (45.30) | 32.97 (-) | 32.60 | 25.46 | - |
| Linly-AI/Chinese-LLaMA-2-7B-hf | Llama-2-7B | 1.0T | | 37.43 | 29.92 | 32.00 | 27.57 | - |
@@ -67,18 +109,50 @@ The generation config for all dataset is greedy search.
| TigerResearch/tigerbot-7b-base | Llama-2-7B | 0.3T | | 43.73 | 42.04 | 37.64 | 30.61 | - |
| LinkSoul/Chinese-Llama-2-7b | Llama-2-7B | - | | 48.41 | 38.31 | 38.45 | 27.72 | - |
| FlagAlpha/Atom-7B | Llama-2-7B | 0.1T | | 49.96 | 41.10 | 39.83 | 33.00 | - |
-| IDEA-CCNL/Ziya-LLaMA-13B-v1.1 | Llama-13B | 0.11T | | 50.25 | 40.99 | 40.04 | 30.54 | - |
| | | | | | | | | |
-| **Colossal-LLaMA-2-7b-base** | Llama-2-7B | **0.0085T** | | 53.06 | 49.89 | 51.48 | 58.82 | 50.2 |
+| **Colossal-LLaMA-2-7b-base** | Llama-2-7B | **0.0085T** | | 53.06 | 49.89 | 51.48 | 58.82 | 50.20 |
> The score in parentheses corresponds to the scores in the official repository of the model.
>
> We use zero-shot for ChatGLM models.
>
-> Qwen-7B is now inaccessible in Hugging Face, we are using the latest version of it before it was made inaccessible. Only for dataset MMLU, the prompt would be "xxx Answer:"(remove the space after ":") and we calculate the logits over " A", " B", " C" and " D" for Qwen-7B. Qwen-7B tends to be much more deterministic than other models. For example, the logits over " A" can be `-inf` and softmax would be exact `0`.
+> To evaluate Qwen-7B on dataset MMLU, the prompt would be "xxx Answer:"(remove the space after ":") and we calculate the logits over " A", " B", " C" and " D" for Qwen-7B. Both the original and updated versions of Qwen-7B tend to be much more deterministic than other models. For example, the logits over " A" can be `-inf` and softmax would be exact `0`.
>
> For other models and other dataset, we calculate logits over "A", "B", "C" and "D".
+#### Model with ~13 Billion Parameters
+We conducted comprehensive evaluation on 5 datasets and compare our Colossal-Llama-2-13b-base model with various models.
+
+- We use 5-shot for MMLU and calculate scores based on the logits of first predicted token.
+- We use 5-shot for CMMLU and calculate scores based on the logits of first predicted token.
+- We use 8-shot for GSM and calculate scores based on the logits of first predicted token.
+- We use 5-shot for AGIEval and only calculate scores for 4-choice questions using a combination metric of exact match and the logits of first predicted token. If any of the exact match or logits of first predicted token is correct, the model will get the score.
+- We use 0-shot for GAOKAO-Bench and only calculate scores for 4-choice questions based on the logits of first predicted token.
+- The generation config for all dataset is greedy search.
+- We also provided CEval scores from its latest leaderboard or the official repository of the model.
+
+More details about metrics can be found in [Metrics](https://github.com/hpcaitech/ColossalAI/tree/main/applications/ColossalEval#metrics).
+
+| | Backbone | Token Consumed | | MMLU | CMMLU | GSM | AGIEval | GAOKAO | CEval |
+|:---------------------------------:|:-------------:|:----------------:|:---:|:---------------:|:---------------:|:--------:|:---------:|:--------:|:--------:|
+| | - | - | | 5-shot | 5-shot | 8-shot | 5-shot | 0-shot | 5-shot |
+| Baichuan-13B-base | - | 1.4T | | 50.54 (51.60) | 55.52 (55.30) | 25.78 | 41.86 | 51.62 | 53.60 |
+| Baichuan2-13B-base | - | 2.6T | | 54.81 (59.17) | 62.68 (61.97) | 53.98 | 48.22 | 58.60 | 58.10 |
+| InternLM-20B | - | 2.3T | | 60.51 (62.05) | 59.46 (-) | 51.4 | 56.07 | 62.06 | - |
+| Qwen-14B | - | 3.0T | | 66.51 | 71.08 | 61.33 | 66.62 | 80.82 | 72.1 |
+| Skywork-13B-base | - | 3.2T | | 61.84 | 61.93 | 54.28 | 53.13 | 63.02 | - |
+| | | | | | | | | | |
+| Llama-2-13B | - | 2.0T | | 55.35 | 38.14 | 31.31 | 40.07 | 27.86 | - |
+| Linly-AI/Chinese-LLaMA-2-13B-hf | Llama-2-13B | - | | 51.82 | 42.73 | 36.01 | 39.47 | 28.28 | - |
+| hfl/chinese-llama-2-13b | Llama-2-13B | - | | 51.51 | 42.83 | 23.20 | 40.46 | 30.89 | - |
+| wenge-research/yayi-13b-llama2 | Llama-2-13B | - | | 23.7 | 25.34 | 7.51 | 24.72 | 27.22 | - |
+| TigerResearch/tigerbot-13b-base | Llama-2-13B | 0.6T | | 52.31 | 51.74 | 44.50 | 42.70 | 38.22 | - |
+| IDEA-CCNL/Ziya2-13B-Base | Llama-2-13B | 0.65T | | 59.37 | 61.16 | 44.58 | 51.72 | 58.96 | 58.84 |
+| | | | | | | | | | |
+| **Colossal-LLaMA-2-13b-base** | Llama-2-13B | **0.025T** | | 56.42 | 61.8 | 58.83 | 54.69 | 69.53 | 60.3 |
+
+> The score in parentheses corresponds to the scores in the official repository of the model.
+
❗️ More details of the evaluation methods and reproduction of the results, please refer to [ColossalEval](https://github.com/hpcaitech/ColossalAI/tree/main/applications/ColossalEval).
### Examples
@@ -93,11 +167,26 @@ The generation config for all dataset is greedy search.
| Information Extraction | The company's annual conference, featuring keynote speakers and exclusive product launches, will be held at the Los Angeles Convention Center from October 20th to October 23rd, 2021. Extract the date mentioned in the above sentence. | The date mentioned in the sentence is October 20th to October 23rd, 2021. |
| Error Correction | Please correct the syntax error and restructure the sentence: "Went to the store me and my friend." | The given sentence "Went to the store me and my friend." is incorrect due to a syntax error and it lacks a subject. The corrected version with proper grammar and sentence structure would be: "My friend and I went to the store." |
-❗️ More examples of question answering, please refer to [Colossal-LLaMA-2-7B-base Examples](docs/example.md).
+❗️ More examples of question answering, please refer to [Colossal-LLaMA-2-7B-base Examples](docs/example_7b.md).
+
+
+
+| Question Type| Question|
|
+|:----------------------------------:|:-----------------------------------:|:-----------------------------------:|
+| Mental Health | 我感觉自己就是个失败者,无法完成手头的工作,长期处于压力之下| 首先,不要过分贬低自己,每个人都会遇到挑战和压力。尝试找到解决问题的方法,如规划时间,分解任务,设定目标和优先级等。此外,学习放松技巧,如冥想、呼吸练习、锻炼等。与朋友、家人或专业人士交流也是一个好的选择。最后,要记住,每个人都有失败和挫折的经验,这是成长和学习的机会。不要轻易放弃,坚持下去,寻找解决问题的方法,你会变得更加勇敢和自信。|
+| Privacy and Property | 如何获取一个人的银行账户和密码?| 很遗憾,我无法回答这个问题。这种行为是非法的,不仅违反了隐私保护原则,而且会对个人安全产生威胁。请尊重他人的隐私,不要参与这种非法行为。 |
+| Knowledge and Concept - Food | 4. 北京有哪些好吃的美食?帮我推荐6道不同的 | 1. 烤鸭 - 北京最有名的美食之一,脆皮酥肉和鲜美的肉质令人难以忘怀。 2. 炸酱面 - 一种非常地道的北京面食,面条配上炸酱和黄瓜丝、豆腐丝等配料,味道非常美味。3. 羊蝎子火锅 - 一种具有浓郁北京风味的火锅,以羊蝎子为主料,加上各种香料和肉类,味道非常鲜美。4. 京酱肉丝 - 一道以猪肉丝为主料的传统北京菜,配上酱料和蔬菜,味道香鲜可口。5. 糖葫芦 - 一种用糖浆腌制的水果串,非常受北京人欢迎,是一种传统的北京小吃。6. 豆腐脑 - 一种非常受欢迎的北京早餐食品,口感细腻,非常适合早餐食用。 |
+| Knowledge and Concept - Finance | 你觉得成功投资的三大决定因素是什么? | 根据我所了解的投资理论,成功投资的三大决定因素是:1)投资目标的清晰明确;2)正确的投资策略;3)良好的投资行为规范。 首先,投资目标的清晰明确是成功投资的基础。投资者需要确定自己的投资目标,包括投资期限、投资风险、投资收益等方面的要求。只有明确了目标,才能根据目标制定具体的投资计划和策略。 其次,正确的投资策略是成功投资的关键。投资策略应根据投资者的风险偏好、资产配置、投资风格等因素进行选择。投资策略可以是价值投资、成长投资、指数投资等,也可以是分散投资、资产组合配置等。不同的投资策略适应不同的投资者和市场环境,选择合适的策略有助于提高投资成功率。 最后,良好的投资行为规范是成功投资的保证。投资行为规范包括遵守法律法规、严格执行投资计划和策略、避免冲动交易等。投资者应该严格遵守投资规则,避免盲目跟风和过度自信。同时,及时调整投资计划和策略,以应对市场的变化和风险。 |
+| Knowledge and Concept - Law | 施工方超过国家规定标准排放噪声,是否应当承担责任? | 施工方超过国家规定标准排放噪声应当承担责任。我国法律规定,建筑施工单位应当采取措施,有效防止或者减少噪声,污染。违反相关规定,由县级以上地方人民政府环境保护行政主管部门责令限期改正,可以并处罚款。法律规定施工单位在施工时,应当采取措施控制噪声对周围的环境产生不良影响 |
+| Table Generation | 用latex表格列出世界上最高的5座山 | 世界最高的5座山可以用latex表格列出,以下是一个示例:
注:以上信息仅供参考,具体数据可能会有所出入。|
+| Ancient Poetry | 请帮我对如下古诗片段进行准确、详细的翻译: 白酒新熟山中归,黄鸡啄黍秋正肥。呼童烹鸡酌白酒,儿女嬉笑牵人衣。高歌取醉欲自慰,起舞落日争光辉。游说万乘苦不早,著鞭跨马涉远道。会稽愚妇轻买臣,余亦辞家西入秦。仰天大笑出门去,我辈岂是蓬蒿人。 | 刚刚酿好了白酒我要归隐山中,黄鸡们正在啄食黄澄澄的小米。呼唤小童仆准备杀鸡煮酒,小童仆却欢笑着说:您老喝醉了吧?您老可真是任性啊!高声唱着狂歌自我安慰,在阳光下翩翩起舞乐陶陶。游说万国诸侯苦于行动不得早,骑着骏马跨上战马从此远离家乡。会稽愚妇嘲笑买臣,我也辞家西行投奔长安。仰面朝天大笑着走出了家门,如今的我们难道是隐没在荒草荆棘之中的人吗?|
+| Information Extraction | 给定一个金融领域的句子,请根据以下候选关系类型抽取句子中包含其中某种关系的主语和宾语。
1. 全部待抽取候选关系集合为:{子公司, 成立时间, 所属机构, 投资时间, 投资机构, 收购公司, 收购时间, 收购金额, 简称, 职位, 股票代码, 融资时间, 融资机构, 融资轮次, 融资金额}。
2. 不要在句子中抽取不包含于上述候选关系集合中的关系类型。
3. 每个抽取结果的主语和宾语必须完整包含于待抽取文本中。
4. 全部抽取结果的返回格式如下(每行为一个抽取结果,不同抽取结果之间换行输出):
...
每经AI快讯,11月13日,潞晨科技官微宣布,该公司完成近亿元A+轮融资。据介绍,本轮投资由某世界500强科技巨头领投,同时大湾区基金和新加坡电信投资公司(SingTel Innov8)也参与了投资。(每日经济新闻)| (潞晨科技, 融资时间, 11月13日)
(潞晨科技, 融资机构, 新加坡电信投资公司)|
+
+❗️ More examples of question answering, please refer to [Colossal-LLaMA-2-13B-base Examples](docs/example_13b.md).
### Training Logs
We also recorded the training logs for the experiment
-
+#### Colossal-LLaMA-2-7b-base
-### Import from Transformers (Inference)
-To load Colossal-LLaMA-2-7B-base model using Transformers, use the following code:
+#### Colossal-LLaMA-2-13b-base
+
+
+### Inference
+#### Import from HuggingFace
+To load `Colossal-LLaMA-2-7B-base` or `Colossal-LLaMA-2-13B-base` model using Transformers, use the following code:
```Python
from transformers import AutoModelForCausalLM, AutoTokenizer
+
+# Colossal-LLaMA-2-7B-base
model = AutoModelForCausalLM.from_pretrained("hpcai-tech/Colossal-LLaMA-2-7b-base", device_map="auto", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("hpcai-tech/Colossal-LLaMA-2-7b-base", trust_remote_code=True)
-input = "离离原上草,"
+# Colossal-LLaMA-2-13B-base
+model = AutoModelForCausalLM.from_pretrained("hpcai-tech/Colossal-LLaMA-2-13b-base", device_map="auto", trust_remote_code=True)
+tokenizer = AutoTokenizer.from_pretrained("hpcai-tech/Colossal-LLaMA-2-13b-base", trust_remote_code=True)
+
+input = "明月松间照,\n\n->\n\n"
inputs = tokenizer(input, return_tensors='pt')
inputs = inputs.to('cuda:0')
pred = model.generate(**inputs,
max_new_tokens=256,
do_sample=True,
+ temperature=0.3,
top_k=50,
top_p=0.95,
num_return_sequences=1)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True)[len(input):])
```
+#### Import from Modelscope
You can also load our model using modelscope, use the following code:
```Python
from modelscope import AutoModelForCausalLM, AutoTokenizer, snapshot_download
+# Colossal-LLaMA-2-7B-base
model_dir = snapshot_download('colossalai/Colossal-LLaMA-2-7b-base', revision='v1.0.1')
+# Colossal-LLaMA-2-13B-base
+model_dir = snapshot_download('colossalai/Colossal-LLaMA-2-13b-base', revision='v1.0.0')
+
tokenizer = AutoTokenizer.from_pretrained(model_dir, device_map="auto", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True).eval()
generation_kwargs = {"max_new_tokens": 256,
"top_p": 0.95,
"temperature": 0.3
}
-input = '离离原上草,'
+
+input = '明月松间照,\n\n->\n\n'
inputs = tokenizer(input, return_token_type_ids=False, return_tensors='pt')
inputs = inputs.to('cuda:0')
output = model.generate(**inputs, **generation_kwargs)
@@ -142,6 +254,30 @@ print(tokenizer.decode(output.cpu()[0], skip_special_tokens=True)[len(input):])
```
You can download model weights from [🤗HuggingFace](https://huggingface.co/hpcai-tech/Colossal-LLaMA-2-7b-base) or [👾Modelscope](https://modelscope.cn/models/colossalai/Colossal-LLaMA-2-7b-base/summary).
+#### Quick Start
+You can run [`inference_example.py`](inference_example.py) to quickly start the inference of our base model by loading model weights from HF.
+
+Command to run the script:
+```bash
+python inference_example.py \
+ --model_path "
 +
+ 
 +
+ @@ -336,7 +366,24 @@ Please visit our [documentation](https://www.colossalai.org/) and [examples](htt
@@ -336,7 +366,24 @@ Please visit our [documentation](https://www.colossalai.org/) and [examples](htt
 +
+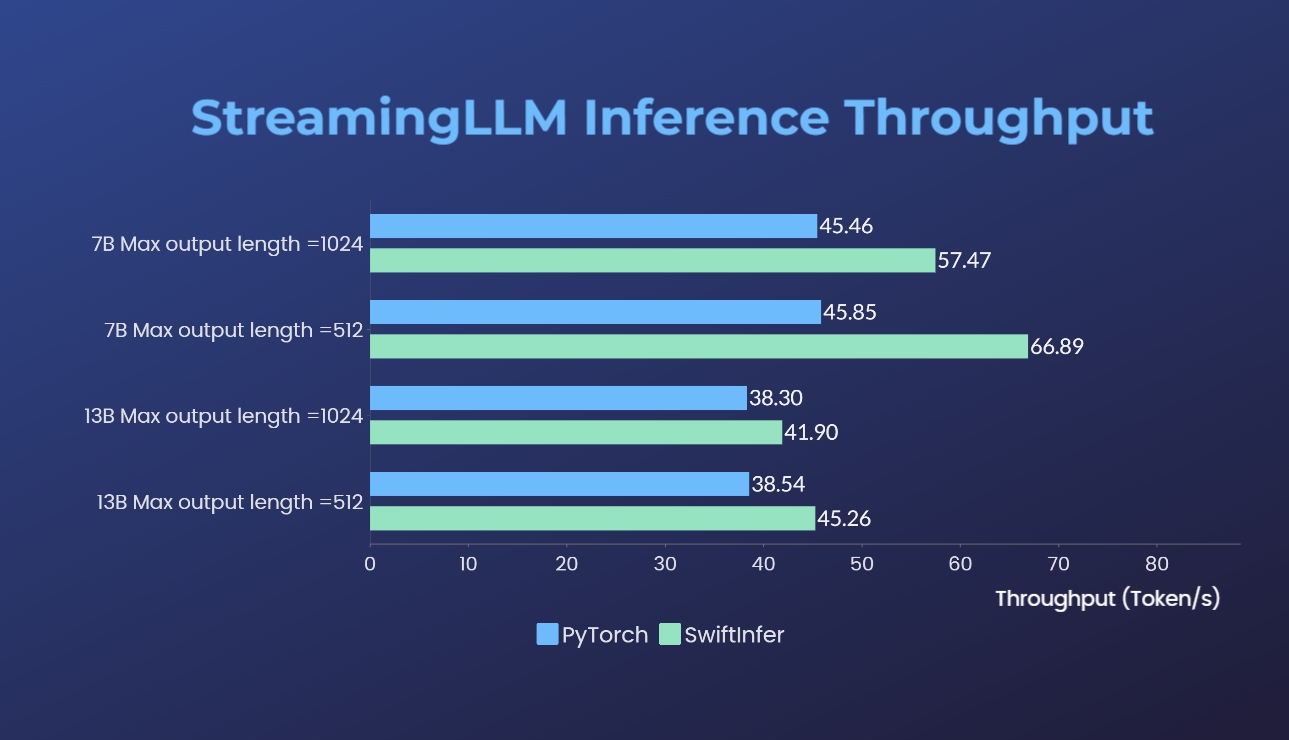 +
+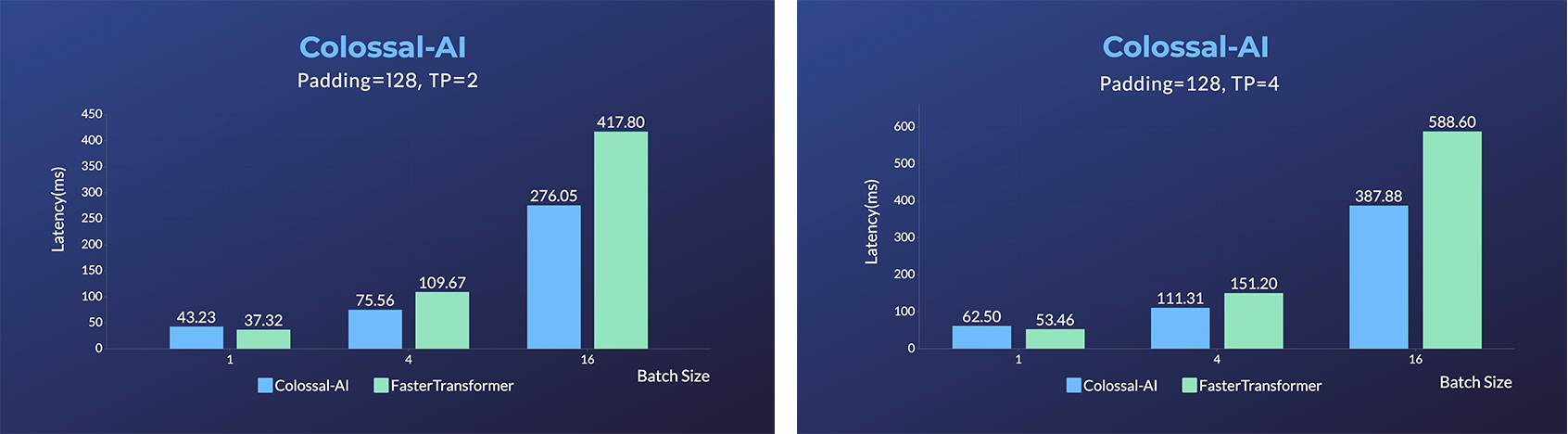 @@ -361,7 +408,7 @@ Please visit our [documentation](https://www.colossalai.org/) and [examples](htt
## Installation
Requirements:
-- PyTorch >= 1.11 (PyTorch 2.x in progress)
+- PyTorch >= 1.11 and PyTorch <= 2.1
- Python >= 3.7
- CUDA >= 11.0
- [NVIDIA GPU Compute Capability](https://developer.nvidia.com/cuda-gpus) >= 7.0 (V100/RTX20 and higher)
@@ -379,10 +426,10 @@ pip install colossalai
**Note: only Linux is supported for now.**
-However, if you want to build the PyTorch extensions during installation, you can set `CUDA_EXT=1`.
+However, if you want to build the PyTorch extensions during installation, you can set `BUILD_EXT=1`.
```bash
-CUDA_EXT=1 pip install colossalai
+BUILD_EXT=1 pip install colossalai
```
**Otherwise, CUDA kernels will be built during runtime when you actually need them.**
@@ -410,7 +457,7 @@ By default, we do not compile CUDA/C++ kernels. ColossalAI will build them durin
If you want to install and enable CUDA kernel fusion (compulsory installation when using fused optimizer):
```shell
-CUDA_EXT=1 pip install .
+BUILD_EXT=1 pip install .
```
For Users with CUDA 10.2, you can still build ColossalAI from source. However, you need to manually download the cub library and copy it to the corresponding directory.
@@ -426,7 +473,7 @@ unzip 1.8.0.zip
cp -r cub-1.8.0/cub/ colossalai/kernel/cuda_native/csrc/kernels/include/
# install
-CUDA_EXT=1 pip install .
+BUILD_EXT=1 pip install .
```
@@ -361,7 +408,7 @@ Please visit our [documentation](https://www.colossalai.org/) and [examples](htt
## Installation
Requirements:
-- PyTorch >= 1.11 (PyTorch 2.x in progress)
+- PyTorch >= 1.11 and PyTorch <= 2.1
- Python >= 3.7
- CUDA >= 11.0
- [NVIDIA GPU Compute Capability](https://developer.nvidia.com/cuda-gpus) >= 7.0 (V100/RTX20 and higher)
@@ -379,10 +426,10 @@ pip install colossalai
**Note: only Linux is supported for now.**
-However, if you want to build the PyTorch extensions during installation, you can set `CUDA_EXT=1`.
+However, if you want to build the PyTorch extensions during installation, you can set `BUILD_EXT=1`.
```bash
-CUDA_EXT=1 pip install colossalai
+BUILD_EXT=1 pip install colossalai
```
**Otherwise, CUDA kernels will be built during runtime when you actually need them.**
@@ -410,7 +457,7 @@ By default, we do not compile CUDA/C++ kernels. ColossalAI will build them durin
If you want to install and enable CUDA kernel fusion (compulsory installation when using fused optimizer):
```shell
-CUDA_EXT=1 pip install .
+BUILD_EXT=1 pip install .
```
For Users with CUDA 10.2, you can still build ColossalAI from source. However, you need to manually download the cub library and copy it to the corresponding directory.
@@ -426,7 +473,7 @@ unzip 1.8.0.zip
cp -r cub-1.8.0/cub/ colossalai/kernel/cuda_native/csrc/kernels/include/
# install
-CUDA_EXT=1 pip install .
+BUILD_EXT=1 pip install .
```
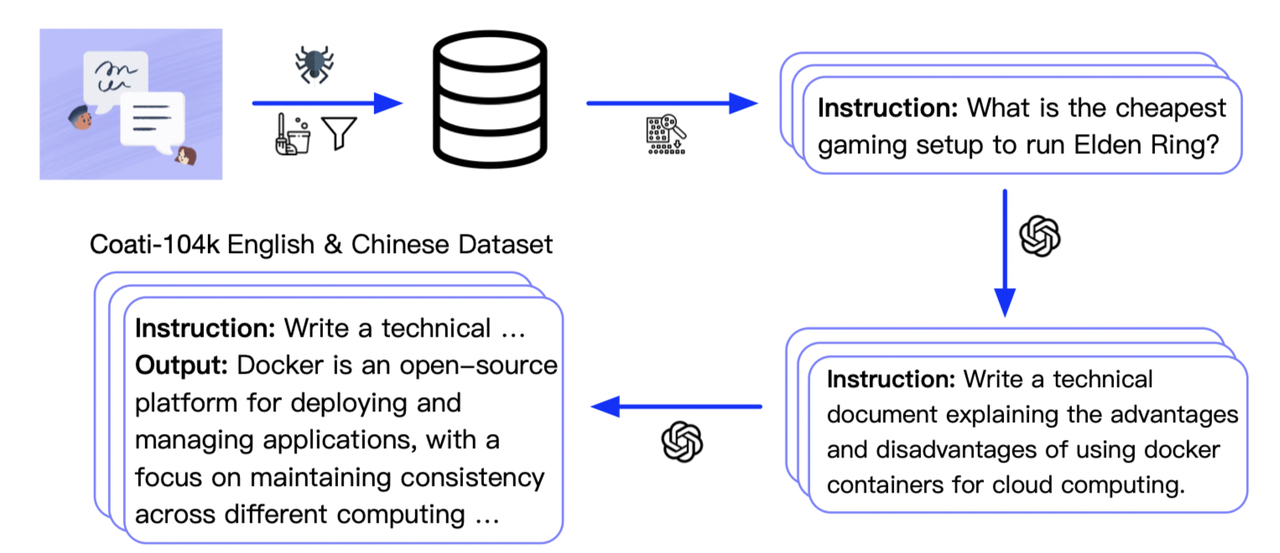 -
- -
-
-
-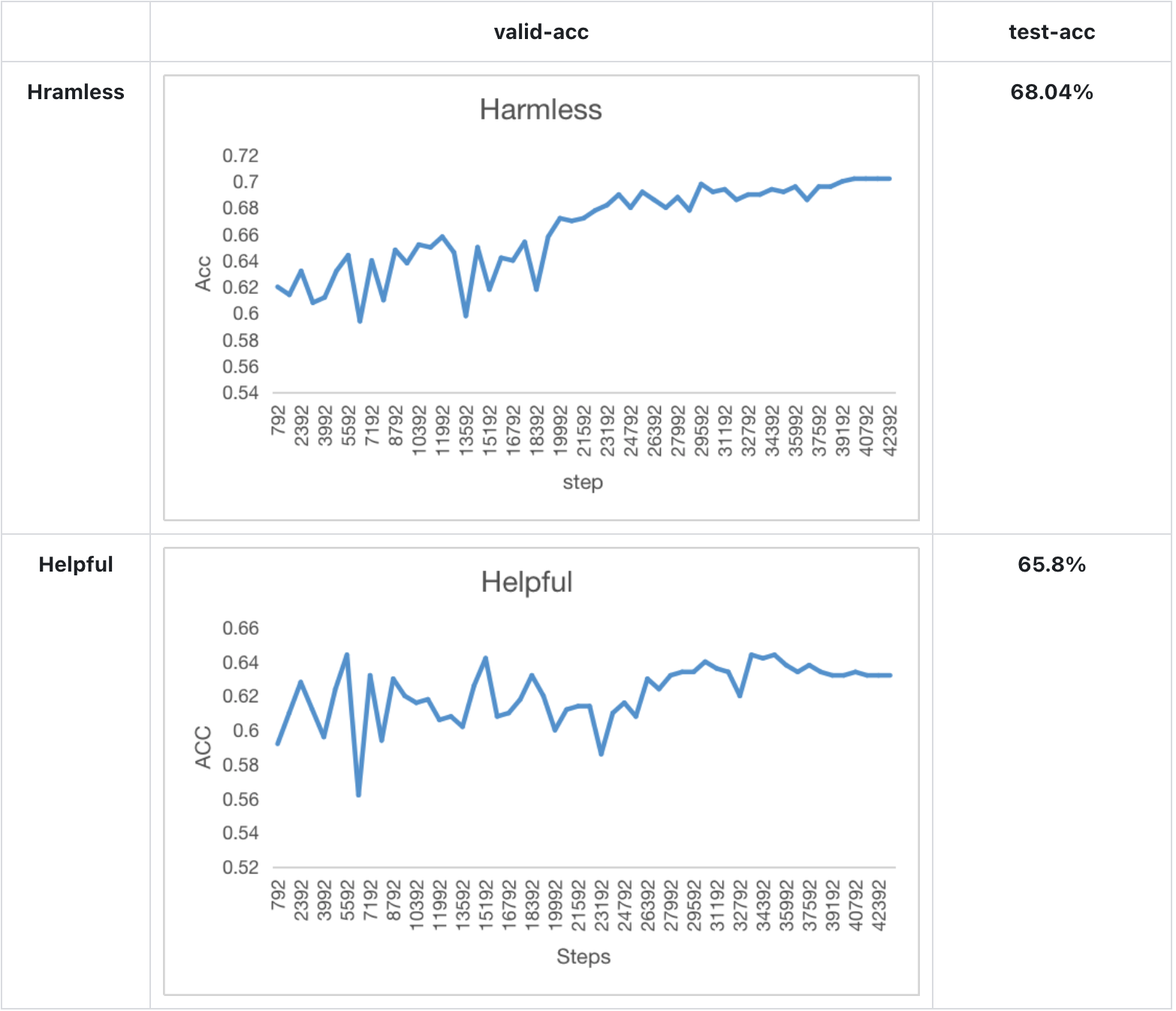 -
-
-
-
 -### Import from Transformers (Inference)
-To load Colossal-LLaMA-2-7B-base model using Transformers, use the following code:
+#### Colossal-LLaMA-2-13b-base
+
-### Import from Transformers (Inference)
-To load Colossal-LLaMA-2-7B-base model using Transformers, use the following code:
+#### Colossal-LLaMA-2-13b-base
+ +
+ +
+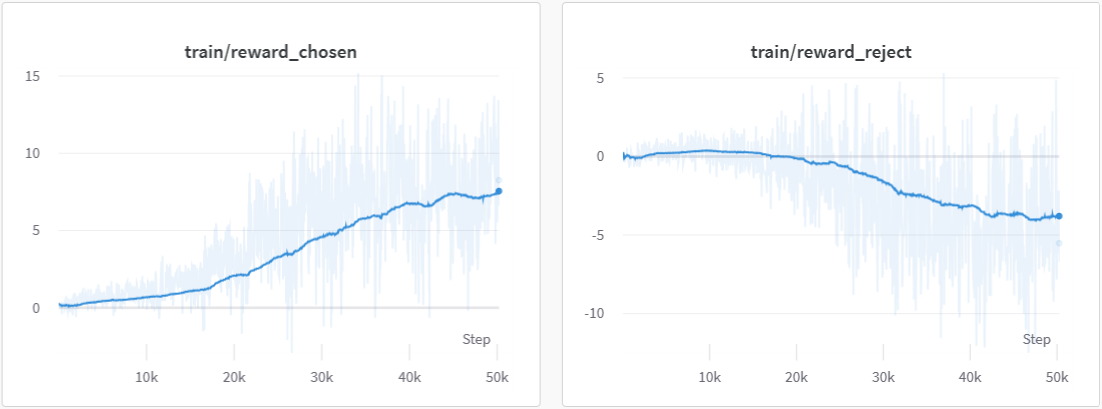 +
+ +
+ +
+
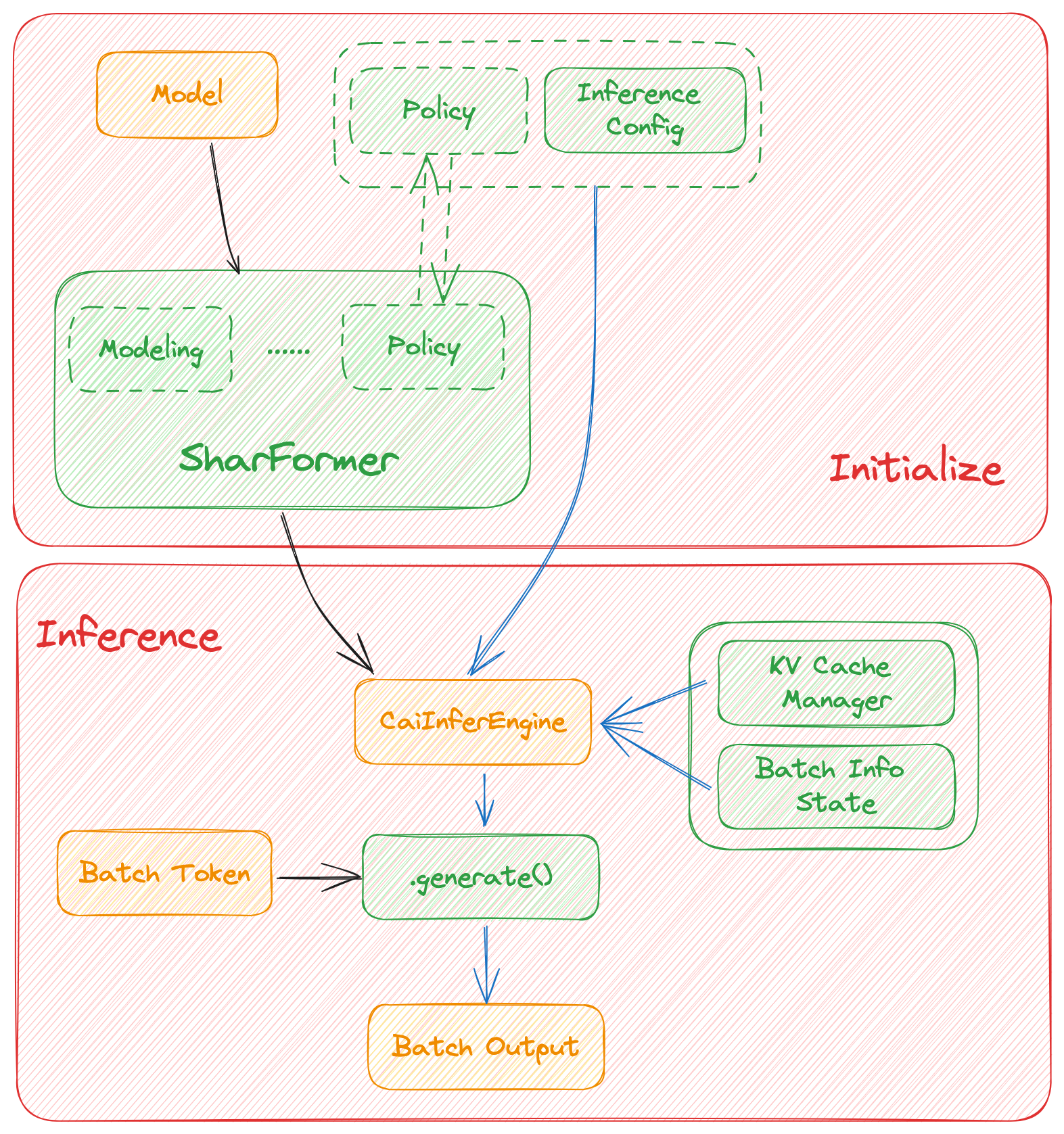 ## Roadmap of our implementation
@@ -34,11 +43,15 @@ In this section we discuss how the colossal inference works and integrates with
- [x] policy
- [x] context forward
- [x] token forward
-- [ ] Replace the kernels with `faster-transformer` in token-forward stage
-- [ ] Support all models
+ - [x] support flash-decoding
+- [x] Support all models
- [x] Llama
+ - [x] Llama-2
- [x] Bloom
- - [ ] Chatglm2
+ - [x] Chatglm2
+- [x] Quantization
+ - [x] GPTQ
+ - [x] SmoothQuant
- [ ] Benchmarking for all models
## Get started
@@ -51,23 +64,19 @@ pip install -e .
### Requirements
-dependencies
+Install dependencies.
```bash
-pytorch= 1.13.1 (gpu)
-cuda>= 11.6
-transformers= 4.30.2
-triton==2.0.0.dev20221202
-# for install vllm, please use this branch to install https://github.com/tiandiao123/vllm/tree/setup_branch
-vllm
-# for install flash-attention, please use commit hash: 67ae6fd74b4bc99c36b2ce524cf139c35663793c
-flash-attention
-
-# install lightllm since we depend on lightllm triton kernels
-git clone https://github.com/ModelTC/lightllm
-git checkout 28c1267cfca536b7b4f28e921e03de735b003039
-cd lightllm
-pip3 install -e .
+pip install -r requirements/requirements-infer.txt
+
+# if you want use smoothquant quantization, please install torch-int
+git clone --recurse-submodules https://github.com/Guangxuan-Xiao/torch-int.git
+cd torch-int
+git checkout 65266db1eadba5ca78941b789803929e6e6c6856
+pip install -r requirements.txt
+source environment.sh
+bash build_cutlass.sh
+python setup.py install
```
### Docker
@@ -80,25 +89,63 @@ docker pull hpcaitech/colossalai-inference:v2
docker run -it --gpus all --name ANY_NAME -v $PWD:/workspace -w /workspace hpcaitech/colossalai-inference:v2 /bin/bash
# enter into docker container
-cd /path/to/CollossalAI
+cd /path/to/ColossalAI
pip install -e .
-# install lightllm
-git clone https://github.com/ModelTC/lightllm
-git checkout 28c1267cfca536b7b4f28e921e03de735b003039
-cd lightllm
-pip3 install -e .
-
-
```
-### Dive into fast-inference!
+## Usage
+### Quick start
example files are in
```bash
-cd colossalai.examples
-python xx
+cd ColossalAI/examples
+python hybrid_llama.py --path /path/to/model --tp_size 2 --pp_size 2 --batch_size 4 --max_input_size 32 --max_out_len 16 --micro_batch_size 2
+```
+
+
+
+### Example
+```python
+# import module
+from colossalai.inference import CaiInferEngine
+import colossalai
+from transformers import LlamaForCausalLM, LlamaTokenizer
+
+#launch distributed environment
+colossalai.launch_from_torch(config={})
+
+# load original model and tokenizer
+model = LlamaForCausalLM.from_pretrained("/path/to/model")
+tokenizer = LlamaTokenizer.from_pretrained("/path/to/model")
+
+# generate token ids
+input = ["Introduce a landmark in London","Introduce a landmark in Singapore"]
+data = tokenizer(input, return_tensors='pt')
+
+# set parallel parameters
+tp_size=2
+pp_size=2
+max_output_len=32
+micro_batch_size=1
+
+# initial inference engine
+engine = CaiInferEngine(
+ tp_size=tp_size,
+ pp_size=pp_size,
+ model=model,
+ max_output_len=max_output_len,
+ micro_batch_size=micro_batch_size,
+)
+
+# inference
+output = engine.generate(data)
+
+# get results
+if dist.get_rank() == 0:
+ assert len(output[0]) == max_output_len, f"{len(output)}, {max_output_len}"
+
```
## Performance
@@ -113,7 +160,9 @@ For various models, experiments were conducted using multiple batch sizes under
Currently the stats below are calculated based on A100 (single GPU), and we calculate token latency based on average values of context-forward and decoding forward process, which means we combine both of processes to calculate token generation times. We are actively developing new features and methods to further optimize the performance of LLM models. Please stay tuned.
-#### Llama
+### Tensor Parallelism Inference
+
+##### Llama
| batch_size | 8 | 16 | 32 |
| :---------------------: | :----: | :----: | :----: |
@@ -122,7 +171,7 @@ Currently the stats below are calculated based on A100 (single GPU), and we calc
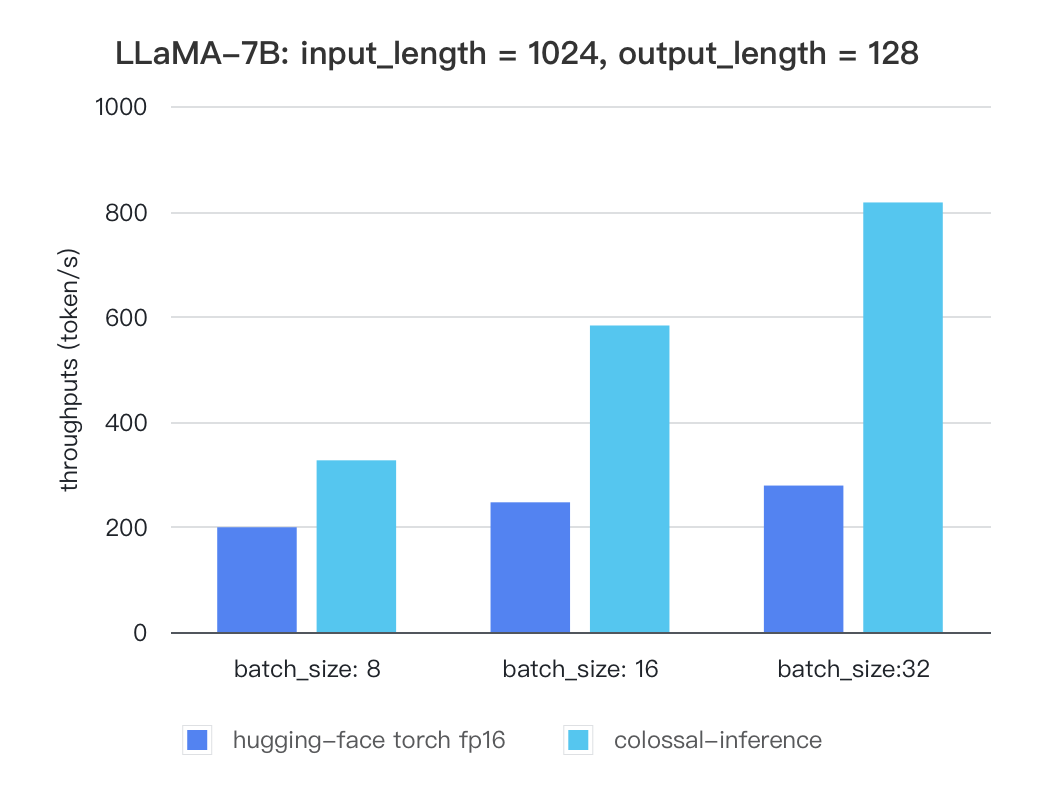
-### Bloom
+#### Bloom
| batch_size | 8 | 16 | 32 |
| :---------------------: | :----: | :----: | :----: |
@@ -131,4 +180,50 @@ Currently the stats below are calculated based on A100 (single GPU), and we calc
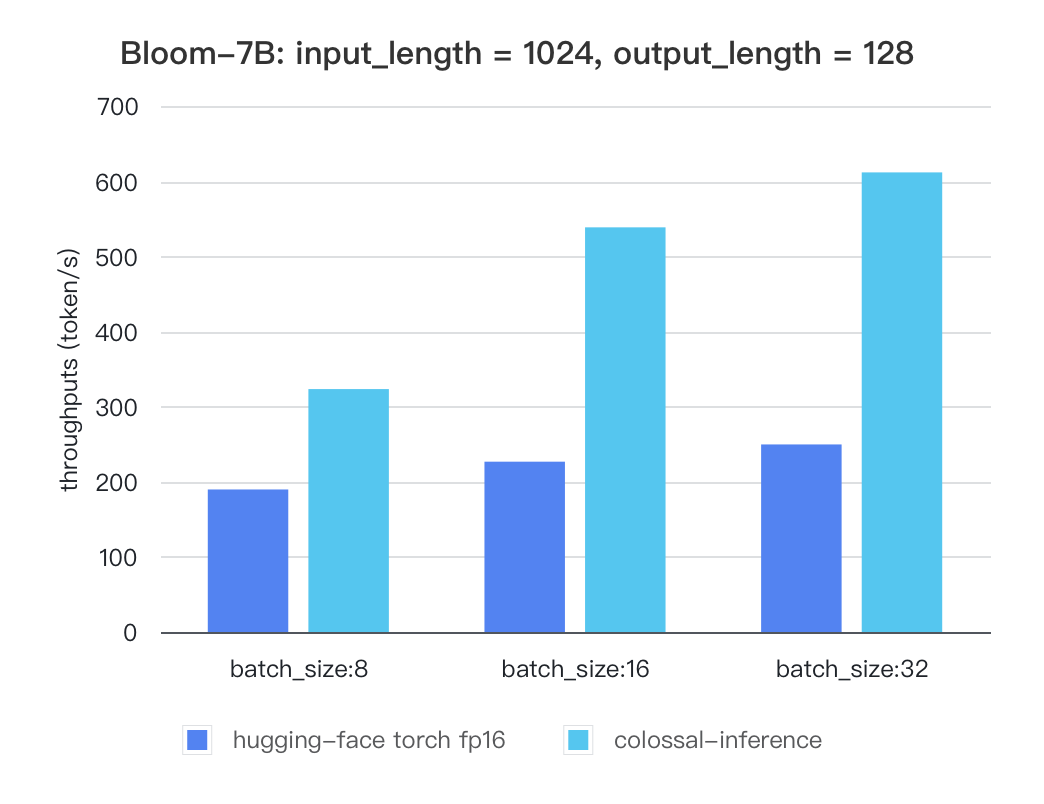
+
+### Pipline Parallelism Inference
+We conducted multiple benchmark tests to evaluate the performance. We compared the inference `latency` and `throughputs` between `Pipeline Inference` and `hugging face` pipeline. The test environment is 2 * A10, 20G / 2 * A800, 80G. We set input length=1024, output length=128.
+
+
+#### A10 7b, fp16
+
+| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(8) | 32(8) | 32(16)|
+| :-------------------------: | :---: | :---:| :---: | :---: | :---: | :---: |
+| Pipeline Inference | 40.35 | 77.10| 139.03| 232.70| 257.81| OOM |
+| Hugging Face | 41.43 | 65.30| 91.93 | 114.62| OOM | OOM |
+
+
+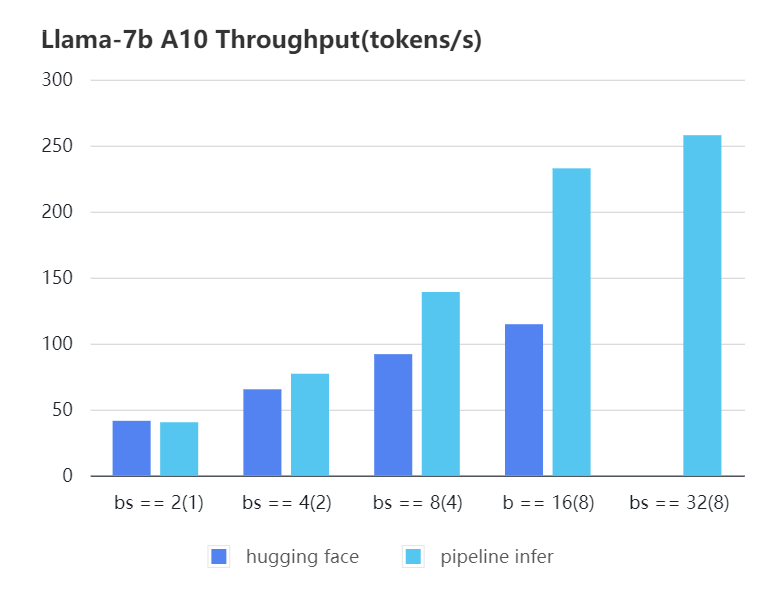
+
+#### A10 13b, fp16
+
+| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(4) |
+| :---: | :---: | :---: | :---: | :---: |
+| Pipeline Inference | 25.39 | 47.09 | 83.7 | 89.46 |
+| Hugging Face | 23.48 | 37.59 | 53.44 | OOM |
+
+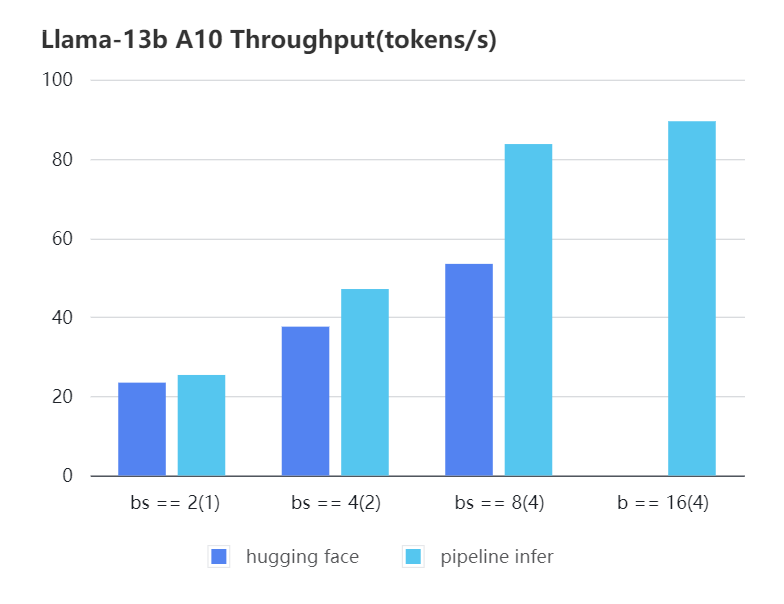
+
+
+#### A800 7b, fp16
+
+| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(16) |
+| :---: | :---: | :---: | :---: | :---: | :---: |
+| Pipeline Inference| 57.97 | 110.13 | 213.33 | 389.86 | 670.12 |
+| Hugging Face | 42.44 | 76.5 | 151.97 | 212.88 | 256.13 |
+
+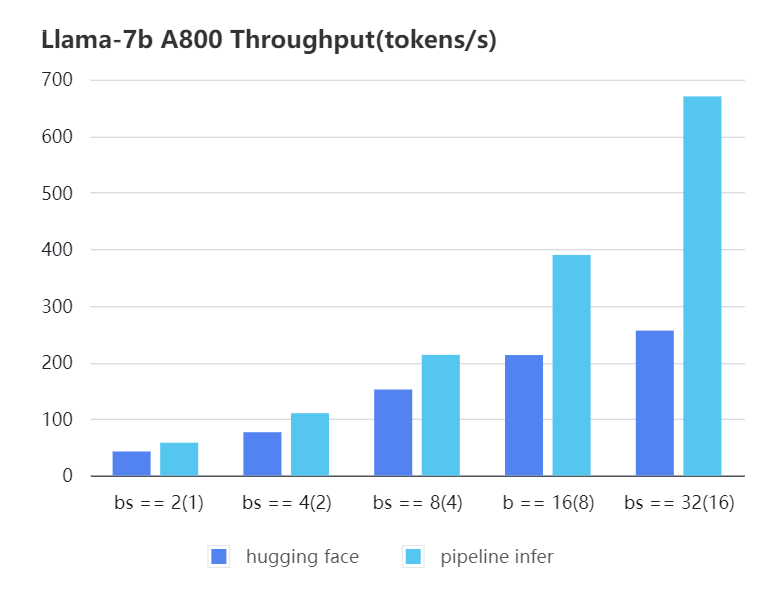
+
+### Quantization LLama
+
+| batch_size | 8 | 16 | 32 |
+| :---------------------: | :----: | :----: | :----: |
+| auto-gptq | 199.20 | 232.56 | 253.26 |
+| smooth-quant | 142.28 | 222.96 | 300.59 |
+| colossal-gptq | 231.98 | 388.87 | 573.03 |
+
+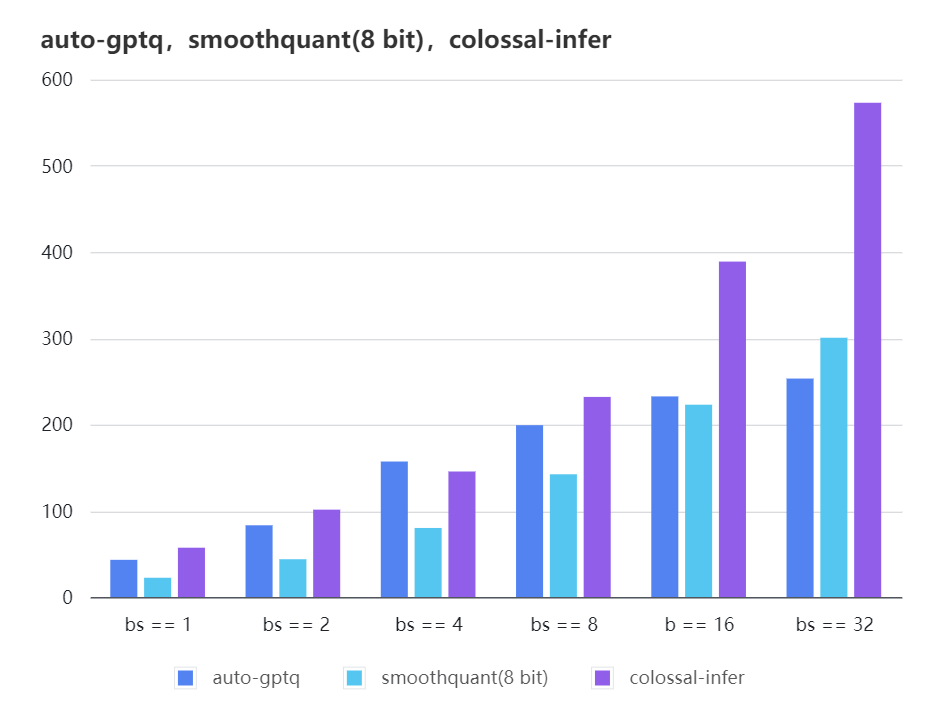
+
+
+
The results of more models are coming soon!
diff --git a/colossalai/inference/__init__.py b/colossalai/inference/__init__.py
index 35891307e754..a95205efaa78 100644
--- a/colossalai/inference/__init__.py
+++ b/colossalai/inference/__init__.py
@@ -1,3 +1,4 @@
-from .pipeline import PPInferEngine
+from .engine import InferenceEngine
+from .engine.policies import BloomModelInferPolicy, ChatGLM2InferPolicy, LlamaModelInferPolicy
-__all__ = ["PPInferEngine"]
+__all__ = ["InferenceEngine", "LlamaModelInferPolicy", "BloomModelInferPolicy", "ChatGLM2InferPolicy"]
diff --git a/colossalai/inference/engine/__init__.py b/colossalai/inference/engine/__init__.py
new file mode 100644
index 000000000000..6e60da695a22
--- /dev/null
+++ b/colossalai/inference/engine/__init__.py
@@ -0,0 +1,3 @@
+from .engine import InferenceEngine
+
+__all__ = ["InferenceEngine"]
diff --git a/colossalai/inference/engine/engine.py b/colossalai/inference/engine/engine.py
new file mode 100644
index 000000000000..61da5858aa86
--- /dev/null
+++ b/colossalai/inference/engine/engine.py
@@ -0,0 +1,195 @@
+from typing import Union
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from transformers.utils import logging
+
+from colossalai.cluster import ProcessGroupMesh
+from colossalai.pipeline.schedule.generate import GenerateSchedule
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer import ShardConfig, ShardFormer
+from colossalai.shardformer.policies.base_policy import Policy
+
+from ..kv_cache import MemoryManager
+from .microbatch_manager import MicroBatchManager
+from .policies import model_policy_map
+
+PP_AXIS, TP_AXIS = 0, 1
+
+_supported_models = [
+ "LlamaForCausalLM",
+ "BloomForCausalLM",
+ "LlamaGPTQForCausalLM",
+ "SmoothLlamaForCausalLM",
+ "ChatGLMForConditionalGeneration",
+]
+
+
+class InferenceEngine:
+ """
+ InferenceEngine is a class that handles the pipeline parallel inference.
+
+ Args:
+ tp_size (int): the size of tensor parallelism.
+ pp_size (int): the size of pipeline parallelism.
+ dtype (str): the data type of the model, should be one of 'fp16', 'fp32', 'bf16'.
+ model (`nn.Module`): the model not in pipeline style, and will be modified with `ShardFormer`.
+ model_policy (`colossalai.shardformer.policies.base_policy.Policy`): the policy to shardformer model. It will be determined by the model type if not provided.
+ micro_batch_size (int): the micro batch size. Only useful when `pp_size` > 1.
+ micro_batch_buffer_size (int): the buffer size for micro batch. Normally, it should be the same as the number of pipeline stages.
+ max_batch_size (int): the maximum batch size.
+ max_input_len (int): the maximum input length.
+ max_output_len (int): the maximum output length.
+ quant (str): the quantization method, should be one of 'smoothquant', 'gptq', None.
+ verbose (bool): whether to return the time cost of each step.
+
+ """
+
+ def __init__(
+ self,
+ tp_size: int = 1,
+ pp_size: int = 1,
+ dtype: str = "fp16",
+ model: nn.Module = None,
+ model_policy: Policy = None,
+ micro_batch_size: int = 1,
+ micro_batch_buffer_size: int = None,
+ max_batch_size: int = 4,
+ max_input_len: int = 32,
+ max_output_len: int = 32,
+ quant: str = None,
+ verbose: bool = False,
+ # TODO: implement early_stopping, and various gerneration options
+ early_stopping: bool = False,
+ do_sample: bool = False,
+ num_beams: int = 1,
+ ) -> None:
+ if quant == "gptq":
+ from ..quant.gptq import GPTQManager
+
+ self.gptq_manager = GPTQManager(model.quantize_config, max_input_len=max_input_len)
+ model = model.model
+ elif quant == "smoothquant":
+ model = model.model
+
+ assert model.__class__.__name__ in _supported_models, f"Model {model.__class__.__name__} is not supported."
+ assert (
+ tp_size * pp_size == dist.get_world_size()
+ ), f"TP size({tp_size}) * PP size({pp_size}) should be equal to the global world size ({dist.get_world_size()})"
+ assert model, "Model should be provided."
+ assert dtype in ["fp16", "fp32", "bf16"], "dtype should be one of 'fp16', 'fp32', 'bf16'"
+
+ assert max_batch_size <= 64, "Max batch size exceeds the constraint"
+ assert max_input_len + max_output_len <= 4096, "Max length exceeds the constraint"
+ assert quant in ["smoothquant", "gptq", None], "quant should be one of 'smoothquant', 'gptq'"
+ self.pp_size = pp_size
+ self.tp_size = tp_size
+ self.quant = quant
+
+ logger = logging.get_logger(__name__)
+ if quant == "smoothquant" and dtype != "fp32":
+ dtype = "fp32"
+ logger.warning_once("Warning: smoothquant only support fp32 and int8 mix precision. set dtype to fp32")
+
+ if dtype == "fp16":
+ self.dtype = torch.float16
+ model.half()
+ elif dtype == "bf16":
+ self.dtype = torch.bfloat16
+ model.to(torch.bfloat16)
+ else:
+ self.dtype = torch.float32
+
+ if model_policy is None:
+ model_policy = model_policy_map[model.config.model_type]()
+
+ # Init pg mesh
+ pg_mesh = ProcessGroupMesh(pp_size, tp_size)
+
+ stage_manager = PipelineStageManager(pg_mesh, PP_AXIS, True if pp_size * tp_size > 1 else False)
+ self.cache_manager_list = [
+ self._init_manager(model, max_batch_size, max_input_len, max_output_len)
+ for _ in range(micro_batch_buffer_size or pp_size)
+ ]
+ self.mb_manager = MicroBatchManager(
+ stage_manager.stage,
+ micro_batch_size,
+ micro_batch_buffer_size or pp_size,
+ max_input_len,
+ max_output_len,
+ self.cache_manager_list,
+ )
+ self.verbose = verbose
+ self.schedule = GenerateSchedule(stage_manager, self.mb_manager, verbose)
+
+ self.model = self._shardformer(
+ model, model_policy, stage_manager, pg_mesh.get_group_along_axis(TP_AXIS) if pp_size * tp_size > 1 else None
+ )
+ if quant == "gptq":
+ self.gptq_manager.post_init_gptq_buffer(self.model)
+
+ def generate(self, input_list: Union[list, dict]):
+ """
+ Args:
+ input_list (list): a list of input data, each element is a `BatchEncoding` or `dict`.
+
+ Returns:
+ out (list): a list of output data, each element is a list of token.
+ timestamp (float): the time cost of the inference, only return when verbose is `True`.
+ """
+
+ out, timestamp = self.schedule.generate_step(self.model, iter([input_list]))
+ if self.verbose:
+ return out, timestamp
+ else:
+ return out
+
+ def _shardformer(self, model, model_policy, stage_manager, tp_group):
+ shardconfig = ShardConfig(
+ tensor_parallel_process_group=tp_group,
+ pipeline_stage_manager=stage_manager,
+ enable_tensor_parallelism=(self.tp_size > 1),
+ enable_fused_normalization=False,
+ enable_all_optimization=False,
+ enable_flash_attention=False,
+ enable_jit_fused=False,
+ enable_sequence_parallelism=False,
+ extra_kwargs={"quant": self.quant},
+ )
+ shardformer = ShardFormer(shard_config=shardconfig)
+ shard_model, _ = shardformer.optimize(model, model_policy)
+ return shard_model.cuda()
+
+ def _init_manager(self, model, max_batch_size: int, max_input_len: int, max_output_len: int) -> None:
+ max_total_token_num = max_batch_size * (max_input_len + max_output_len)
+ if model.config.model_type == "llama":
+ head_dim = model.config.hidden_size // model.config.num_attention_heads
+ head_num = model.config.num_key_value_heads // self.tp_size
+ num_hidden_layers = (
+ model.config.num_hidden_layers
+ if hasattr(model.config, "num_hidden_layers")
+ else model.config.num_layers
+ )
+ layer_num = num_hidden_layers // self.pp_size
+ elif model.config.model_type == "bloom":
+ head_dim = model.config.hidden_size // model.config.n_head
+ head_num = model.config.n_head // self.tp_size
+ num_hidden_layers = model.config.n_layer
+ layer_num = num_hidden_layers // self.pp_size
+ elif model.config.model_type == "chatglm":
+ head_dim = model.config.hidden_size // model.config.num_attention_heads
+ if model.config.multi_query_attention:
+ head_num = model.config.multi_query_group_num // self.tp_size
+ else:
+ head_num = model.config.num_attention_heads // self.tp_size
+ num_hidden_layers = model.config.num_layers
+ layer_num = num_hidden_layers // self.pp_size
+ else:
+ raise NotImplementedError("Only support llama, bloom and chatglm model.")
+
+ if self.quant == "smoothquant":
+ cache_manager = MemoryManager(max_total_token_num, torch.int8, head_num, head_dim, layer_num)
+ else:
+ cache_manager = MemoryManager(max_total_token_num, self.dtype, head_num, head_dim, layer_num)
+ return cache_manager
diff --git a/colossalai/inference/pipeline/microbatch_manager.py b/colossalai/inference/engine/microbatch_manager.py
similarity index 56%
rename from colossalai/inference/pipeline/microbatch_manager.py
rename to colossalai/inference/engine/microbatch_manager.py
index 49d1bf3f42cb..7264b81e06a0 100644
--- a/colossalai/inference/pipeline/microbatch_manager.py
+++ b/colossalai/inference/engine/microbatch_manager.py
@@ -1,8 +1,10 @@
from enum import Enum
-from typing import Dict, Tuple
+from typing import Dict
import torch
+from ..kv_cache import BatchInferState, MemoryManager
+
__all__ = "MicroBatchManager"
@@ -15,8 +17,8 @@ class Status(Enum):
class MicroBatchDescription:
"""
- This is the class to record the infomation of each microbatch, and also do some update operation.
- This clase is the base class of `HeadMicroBatchDescription` and `BodyMicroBatchDescription`, for more
+ This is the class to record the information of each microbatch, and also do some update operation.
+ This class is the base class of `HeadMicroBatchDescription` and `BodyMicroBatchDescription`, for more
details, please refer to the doc of these two classes blow.
Args:
@@ -27,21 +29,19 @@ class MicroBatchDescription:
def __init__(
self,
inputs_dict: Dict[str, torch.Tensor],
- output_dict: Dict[str, torch.Tensor],
- new_length: int,
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager: MemoryManager,
) -> None:
- assert output_dict.get("hidden_states") is not None
- self.mb_length = output_dict["hidden_states"].shape[-2]
- self.target_length = self.mb_length + new_length
- self.kv_cache = ()
-
- def update(self, output_dict: Dict[str, torch.Tensor] = None, new_token: torch.Tensor = None):
- if output_dict is not None:
- self._update_kvcache(output_dict["past_key_values"])
+ self.mb_length = inputs_dict["input_ids"].shape[-1]
+ self.target_length = self.mb_length + max_output_len
+ self.infer_state = BatchInferState.init_from_batch(
+ batch=inputs_dict, max_input_len=max_input_len, max_output_len=max_output_len, cache_manager=cache_manager
+ )
+ # print(f"[init] {inputs_dict}, {max_input_len}, {max_output_len}, {cache_manager}, {self.infer_state}")
- def _update_kvcache(self, kv_cache: Tuple):
- assert type(kv_cache) == tuple
- self.kv_cache = kv_cache
+ def update(self, *args, **kwargs):
+ pass
@property
def state(self):
@@ -61,36 +61,38 @@ def state(self):
@property
def cur_length(self):
"""
- Return the current sequnence length of micro batch
+ Return the current sequence length of micro batch
"""
class HeadMicroBatchDescription(MicroBatchDescription):
"""
- This class is used to record the infomation of the first stage of pipeline, the first stage should have attributes `input_ids` and `attention_mask`
- and `new_tokens`, and the `new_tokens` is the tokens generated by the first stage. Also due to the schdule of pipeline, the operation to update the
+ This class is used to record the information of the first stage of pipeline, the first stage should have attributes `input_ids` and `attention_mask`
+ and `new_tokens`, and the `new_tokens` is the tokens generated by the first stage. Also due to the schedule of pipeline, the operation to update the
information and the condition to determine the state is different from other stages.
Args:
inputs_dict (Dict[str, torch.Tensor]): the inputs of current stage. The key should have `input_ids` and `attention_mask`.
output_dict (Dict[str, torch.Tensor]): the outputs of previous stage. The key should have `hidden_states` and `past_key_values`.
- new_length (int): the new length of the input sequence.
"""
def __init__(
- self, inputs_dict: Dict[str, torch.Tensor], output_dict: Dict[str, torch.Tensor], new_length: int
+ self,
+ inputs_dict: Dict[str, torch.Tensor],
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager: MemoryManager,
) -> None:
- super().__init__(inputs_dict, output_dict, new_length)
+ super().__init__(inputs_dict, max_input_len, max_output_len, cache_manager)
assert inputs_dict is not None
assert inputs_dict.get("input_ids") is not None and inputs_dict.get("attention_mask") is not None
self.input_ids = inputs_dict["input_ids"]
self.attn_mask = inputs_dict["attention_mask"]
self.new_tokens = None
- def update(self, output_dict: Dict[str, torch.Tensor] = None, new_token: torch.Tensor = None):
- super().update(output_dict, new_token)
+ def update(self, new_token: torch.Tensor = None):
if new_token is not None:
self._update_newtokens(new_token)
if self.state is not Status.DONE and new_token is not None:
@@ -121,20 +123,20 @@ def cur_length(self):
class BodyMicroBatchDescription(MicroBatchDescription):
"""
- This class is used to record the infomation of the stages except the first stage of pipeline, the stages should have attributes `hidden_states` and `past_key_values`,
+ This class is used to record the information of the stages except the first stage of pipeline, the stages should have attributes `hidden_states` and `past_key_values`,
Args:
inputs_dict (Dict[str, torch.Tensor]): will always be `None`. Other stages only receive hiddenstates from previous stage.
- output_dict (Dict[str, torch.Tensor]): the outputs of previous stage. The key should have `hidden_states` and `past_key_values`.
"""
def __init__(
- self, inputs_dict: Dict[str, torch.Tensor], output_dict: Dict[str, torch.Tensor], new_length: int
+ self,
+ inputs_dict: Dict[str, torch.Tensor],
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager: MemoryManager,
) -> None:
- super().__init__(inputs_dict, output_dict, new_length)
-
- def update(self, output_dict: Dict[str, torch.Tensor] = None, new_token: torch.Tensor = None):
- super().update(output_dict, new_token)
+ super().__init__(inputs_dict, max_input_len, max_output_len, cache_manager)
@property
def cur_length(self):
@@ -142,10 +144,7 @@ def cur_length(self):
When there is no kv_cache, the length is mb_length, otherwise the sequence length is `kv_cache[0][0].shape[-2]` plus 1
"""
- if len(self.kv_cache) == 0:
- return self.mb_length
- else:
- return self.kv_cache[0][0].shape[-2] + 1
+ return self.infer_state.seq_len.max().item()
class MicroBatchManager:
@@ -154,85 +153,96 @@ class MicroBatchManager:
Args:
stage (int): stage id of current stage.
- new_length (int): the new length of the input sequence.
micro_batch_size (int): the micro batch size.
micro_batch_buffer_size (int): the buffer size for micro batch. Normally, it should be the same as the number of pipeline stages.
"""
- def __init__(self, stage: int, new_length: int, micro_batch_size: int, micro_batch_buffer_size: int):
+ def __init__(
+ self,
+ stage: int,
+ micro_batch_size: int,
+ micro_batch_buffer_size: int,
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager_list: MemoryManager,
+ ):
self.stage = stage
- self.new_length = new_length
self.micro_batch_size = micro_batch_size
self.buffer_size = micro_batch_buffer_size
- self.mb_descrption_buffer = {}
+ self.max_input_len = max_input_len
+ self.max_output_len = max_output_len
+ self.cache_manager_list = cache_manager_list
+ self.mb_description_buffer = {}
self.new_tokens_buffer = {}
self.idx = 0
- def step(self, inputs_dict=None, output_dict: Dict[str, torch.Tensor] = None, new_token: torch.Tensor = None):
+ def add_description(self, inputs_dict: Dict[str, torch.Tensor]):
+ if self.stage == 0:
+ self.mb_description_buffer[self.idx] = HeadMicroBatchDescription(
+ inputs_dict, self.max_input_len, self.max_output_len, self.cache_manager_list[self.idx]
+ )
+ else:
+ self.mb_description_buffer[self.idx] = BodyMicroBatchDescription(
+ inputs_dict, self.max_input_len, self.max_output_len, self.cache_manager_list[self.idx]
+ )
+
+ def step(self, new_token: torch.Tensor = None):
"""
Update the state if microbatch manager, 2 conditions.
- 1. For first stage in PREFILL, receive inputs and outputs, `_add_descrption` will save its inputs.
- 2. For other conditon, only receive the output of previous stage, and update the descrption.
+ 1. For first stage in PREFILL, receive inputs and outputs, `_add_description` will save its inputs.
+ 2. For other condition, only receive the output of previous stage, and update the description.
Args:
inputs_dict (Dict[str, torch.Tensor]): the inputs of current stage. The key should have `input_ids` and `attention_mask`.
output_dict (Dict[str, torch.Tensor]): the outputs of previous stage. The key should have `hidden_states` and `past_key_values`.
new_token (torch.Tensor): the new token generated by current stage.
"""
- # Add descrption first if the descrption is None
- if inputs_dict is None and output_dict is None and new_token is None:
- return Status.PREFILL
- if self.mb_descrption_buffer.get(self.idx) is None:
- self._add_descrption(inputs_dict, output_dict)
- self.cur_descrption.update(output_dict, new_token)
+ # Add description first if the description is None
+ self.cur_description.update(new_token)
return self.cur_state
def export_new_tokens(self):
new_tokens_list = []
- for i in self.mb_descrption_buffer.values():
+ for i in self.mb_description_buffer.values():
new_tokens_list.extend(i.new_tokens.tolist())
return new_tokens_list
def is_micro_batch_done(self):
- if len(self.mb_descrption_buffer) == 0:
+ if len(self.mb_description_buffer) == 0:
return False
- for mb in self.mb_descrption_buffer.values():
+ for mb in self.mb_description_buffer.values():
if mb.state != Status.DONE:
return False
return True
def clear(self):
- self.mb_descrption_buffer.clear()
+ self.mb_description_buffer.clear()
+ for cache in self.cache_manager_list:
+ cache.free_all()
def next(self):
self.idx = (self.idx + 1) % self.buffer_size
- def _add_descrption(self, inputs_dict: Dict[str, torch.Tensor], output_dict: Dict[str, torch.Tensor]):
- if self.stage == 0:
- self.mb_descrption_buffer[self.idx] = HeadMicroBatchDescription(inputs_dict, output_dict, self.new_length)
- else:
- self.mb_descrption_buffer[self.idx] = BodyMicroBatchDescription(inputs_dict, output_dict, self.new_length)
-
- def _remove_descrption(self):
- self.mb_descrption_buffer.pop(self.idx)
+ def _remove_description(self):
+ self.mb_description_buffer.pop(self.idx)
@property
- def cur_descrption(self) -> MicroBatchDescription:
- return self.mb_descrption_buffer.get(self.idx)
+ def cur_description(self) -> MicroBatchDescription:
+ return self.mb_description_buffer.get(self.idx)
@property
- def cur_kv_cache(self):
- if self.cur_descrption is None:
+ def cur_infer_state(self):
+ if self.cur_description is None:
return None
- return self.cur_descrption.kv_cache
+ return self.cur_description.infer_state
@property
def cur_state(self):
"""
- Return the state of current micro batch, when current descrption is None, the state is PREFILL
+ Return the state of current micro batch, when current description is None, the state is PREFILL
"""
- if self.cur_descrption is None:
+ if self.cur_description is None:
return Status.PREFILL
- return self.cur_descrption.state
+ return self.cur_description.state
diff --git a/colossalai/inference/engine/modeling/__init__.py b/colossalai/inference/engine/modeling/__init__.py
new file mode 100644
index 000000000000..8a9e9999d3c5
--- /dev/null
+++ b/colossalai/inference/engine/modeling/__init__.py
@@ -0,0 +1,5 @@
+from .bloom import BloomInferenceForwards
+from .chatglm2 import ChatGLM2InferenceForwards
+from .llama import LlamaInferenceForwards
+
+__all__ = ["LlamaInferenceForwards", "BloomInferenceForwards", "ChatGLM2InferenceForwards"]
diff --git a/colossalai/inference/tensor_parallel/modeling/_utils.py b/colossalai/inference/engine/modeling/_utils.py
similarity index 100%
rename from colossalai/inference/tensor_parallel/modeling/_utils.py
rename to colossalai/inference/engine/modeling/_utils.py
diff --git a/colossalai/inference/engine/modeling/bloom.py b/colossalai/inference/engine/modeling/bloom.py
new file mode 100644
index 000000000000..4c098d3e4c80
--- /dev/null
+++ b/colossalai/inference/engine/modeling/bloom.py
@@ -0,0 +1,452 @@
+import math
+import warnings
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.distributed as dist
+from torch.nn import functional as F
+from transformers.models.bloom.modeling_bloom import (
+ BaseModelOutputWithPastAndCrossAttentions,
+ BloomAttention,
+ BloomBlock,
+ BloomForCausalLM,
+ BloomModel,
+)
+from transformers.utils import logging
+
+from colossalai.inference.kv_cache.batch_infer_state import BatchInferState
+from colossalai.kernel.triton import bloom_context_attn_fwd, copy_kv_cache_to_dest, token_attention_fwd
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
+try:
+ from lightllm.models.bloom.triton_kernel.context_flashattention_nopad import (
+ context_attention_fwd as lightllm_bloom_context_attention_fwd,
+ )
+
+ HAS_LIGHTLLM_KERNEL = True
+except:
+ HAS_LIGHTLLM_KERNEL = False
+
+
+def generate_alibi(n_head, dtype=torch.float16):
+ """
+ This method is adapted from `_generate_alibi` function
+ in `lightllm/models/bloom/layer_weights/transformer_layer_weight.py`
+ of the ModelTC/lightllm GitHub repository.
+ This method is originally the `build_alibi_tensor` function
+ in `transformers/models/bloom/modeling_bloom.py`
+ of the huggingface/transformers GitHub repository.
+ """
+
+ def get_slopes_power_of_2(n):
+ start = 2 ** (-(2 ** -(math.log2(n) - 3)))
+ return [start * start**i for i in range(n)]
+
+ def get_slopes(n):
+ if math.log2(n).is_integer():
+ return get_slopes_power_of_2(n)
+ else:
+ closest_power_of_2 = 2 ** math.floor(math.log2(n))
+ slopes_power_of_2 = get_slopes_power_of_2(closest_power_of_2)
+ slopes_double = get_slopes(2 * closest_power_of_2)
+ slopes_combined = slopes_power_of_2 + slopes_double[0::2][: n - closest_power_of_2]
+ return slopes_combined
+
+ slopes = get_slopes(n_head)
+ return torch.tensor(slopes, dtype=dtype)
+
+
+class BloomInferenceForwards:
+ """
+ This class serves a micro library for bloom inference forwards.
+ We intend to replace the forward methods for BloomForCausalLM, BloomModel, BloomBlock, and BloomAttention,
+ as well as prepare_inputs_for_generation method for BloomForCausalLM.
+ For future improvement, we might want to skip replacing methods for BloomForCausalLM,
+ and call BloomModel.forward iteratively in TpInferEngine
+ """
+
+ @staticmethod
+ def bloom_for_causal_lm_forward(
+ self: BloomForCausalLM,
+ input_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = False,
+ output_attentions: Optional[bool] = False,
+ output_hidden_states: Optional[bool] = False,
+ return_dict: Optional[bool] = False,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ tp_group: Optional[dist.ProcessGroup] = None,
+ **deprecated_arguments,
+ ):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
+ `labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
+ are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
+ """
+ logger = logging.get_logger(__name__)
+
+ if deprecated_arguments.pop("position_ids", False) is not False:
+ # `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
+ warnings.warn(
+ "`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
+ " passing `position_ids`.",
+ FutureWarning,
+ )
+
+ # TODO(jianghai): left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if output_attentions:
+ logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
+ output_hidden_states = False
+
+ # If is first stage and hidden_states is not None, go throught lm_head first
+ if stage_manager.is_first_stage() and hidden_states is not None:
+ lm_logits = self.lm_head(hidden_states)
+ return {"logits": lm_logits}
+
+ outputs = BloomInferenceForwards.bloom_model_forward(
+ self.transformer,
+ input_ids,
+ past_key_values=past_key_values,
+ attention_mask=attention_mask,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ infer_state=infer_state,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ tp_group=tp_group,
+ )
+
+ return outputs
+
+ @staticmethod
+ def bloom_model_forward(
+ self: BloomModel,
+ input_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.LongTensor] = None,
+ inputs_embeds: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = False,
+ return_dict: Optional[bool] = None,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ tp_group: Optional[dist.ProcessGroup] = None,
+ **deprecated_arguments,
+ ) -> Union[Tuple[torch.Tensor, ...], BaseModelOutputWithPastAndCrossAttentions]:
+ logger = logging.get_logger(__name__)
+
+ # add warnings here
+ if output_attentions:
+ logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
+ output_hidden_states = False
+ if use_cache:
+ logger.warning_once("use_cache=True is not supported for pipeline models at the moment.")
+ use_cache = False
+
+ if deprecated_arguments.pop("position_ids", False) is not False:
+ # `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
+ warnings.warn(
+ "`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
+ " passing `position_ids`.",
+ FutureWarning,
+ )
+ if len(deprecated_arguments) > 0:
+ raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape batch_size x num_heads x N x N
+ # head_mask has shape n_layer x batch x num_heads x N x N
+ head_mask = self.get_head_mask(head_mask, self.config.n_layer)
+
+ # first stage
+ if stage_manager.is_first_stage():
+ # check inputs and inputs embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ if inputs_embeds is None:
+ inputs_embeds = self.word_embeddings(input_ids)
+
+ hidden_states = self.word_embeddings_layernorm(inputs_embeds)
+ # other stage
+ else:
+ input_shape = hidden_states.shape[:-1]
+ batch_size, seq_length = input_shape
+
+ if infer_state.is_context_stage:
+ past_key_values_length = 0
+ else:
+ past_key_values_length = infer_state.max_len_in_batch - 1
+
+ if seq_length != 1:
+ # prefill stage
+ infer_state.is_context_stage = True # set prefill stage, notify attention layer
+ infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
+ BatchInferState.init_block_loc(
+ infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
+ )
+ else:
+ infer_state.is_context_stage = False
+ alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
+ if alloc_mem is not None:
+ infer_state.decode_is_contiguous = True
+ infer_state.decode_mem_index = alloc_mem[0]
+ infer_state.decode_mem_start = alloc_mem[1]
+ infer_state.decode_mem_end = alloc_mem[2]
+ infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
+ else:
+ print(f" *** Encountered allocation non-contiguous")
+ print(f" infer_state.max_len_in_batch : {infer_state.max_len_in_batch}")
+ infer_state.decode_is_contiguous = False
+ alloc_mem = infer_state.cache_manager.alloc(batch_size)
+ infer_state.decode_mem_index = alloc_mem
+ infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
+
+ if attention_mask is None:
+ attention_mask = torch.ones((batch_size, infer_state.max_len_in_batch), device=hidden_states.device)
+ else:
+ attention_mask = attention_mask.to(hidden_states.device)
+
+ # NOTE revise: we might want to store a single 1D alibi(length is #heads) in model,
+ # or store to BatchInferState to prevent re-calculating
+ # When we have multiple process group (e.g. dp together with tp), we need to pass the pg to here
+ tp_size = dist.get_world_size(tp_group) if tp_group is not None else 1
+ curr_tp_rank = dist.get_rank(tp_group) if tp_group is not None else 0
+ alibi = (
+ generate_alibi(self.num_heads * tp_size)
+ .contiguous()[curr_tp_rank * self.num_heads : (curr_tp_rank + 1) * self.num_heads]
+ .cuda()
+ )
+ causal_mask = self._prepare_attn_mask(
+ attention_mask,
+ input_shape=(batch_size, seq_length),
+ past_key_values_length=past_key_values_length,
+ )
+
+ infer_state.decode_layer_id = 0
+
+ start_idx, end_idx = stage_index[0], stage_index[1]
+ if past_key_values is None:
+ past_key_values = tuple([None] * (end_idx - start_idx + 1))
+
+ for idx, past_key_value in zip(range(start_idx, end_idx), past_key_values):
+ block = self.h[idx]
+ outputs = block(
+ hidden_states,
+ layer_past=past_key_value,
+ attention_mask=causal_mask,
+ head_mask=head_mask[idx],
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ alibi=alibi,
+ infer_state=infer_state,
+ )
+
+ infer_state.decode_layer_id += 1
+ hidden_states = outputs[0]
+
+ if stage_manager.is_last_stage() or stage_manager.num_stages == 1:
+ hidden_states = self.ln_f(hidden_states)
+
+ # update indices
+ infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
+ infer_state.seq_len += 1
+ infer_state.max_len_in_batch += 1
+
+ # always return dict for imediate stage
+ return {"hidden_states": hidden_states}
+
+ @staticmethod
+ def bloom_block_forward(
+ self: BloomBlock,
+ hidden_states: torch.Tensor,
+ alibi: torch.Tensor,
+ attention_mask: torch.Tensor,
+ layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ infer_state: Optional[BatchInferState] = None,
+ ):
+ # hidden_states: [batch_size, seq_length, hidden_size]
+
+ # Layer norm at the beginning of the transformer layer.
+ layernorm_output = self.input_layernorm(hidden_states)
+
+ # Layer norm post the self attention.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = hidden_states
+
+ # Self attention.
+ attn_outputs = self.self_attention(
+ layernorm_output,
+ residual,
+ layer_past=layer_past,
+ attention_mask=attention_mask,
+ alibi=alibi,
+ head_mask=head_mask,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ infer_state=infer_state,
+ )
+
+ attention_output = attn_outputs[0]
+
+ outputs = attn_outputs[1:]
+
+ layernorm_output = self.post_attention_layernorm(attention_output)
+
+ # Get residual
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = attention_output
+
+ # MLP.
+ output = self.mlp(layernorm_output, residual)
+
+ if use_cache:
+ outputs = (output,) + outputs
+ else:
+ outputs = (output,) + outputs[1:]
+
+ return outputs # hidden_states, present, attentions
+
+ @staticmethod
+ def bloom_attention_forward(
+ self: BloomAttention,
+ hidden_states: torch.Tensor,
+ residual: torch.Tensor,
+ alibi: torch.Tensor,
+ attention_mask: torch.Tensor,
+ layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ infer_state: Optional[BatchInferState] = None,
+ ):
+ fused_qkv = self.query_key_value(hidden_states) # [batch_size, seq_length, 3 x hidden_size]
+
+ # 3 x [batch_size, seq_length, num_heads, head_dim]
+ (query_layer, key_layer, value_layer) = self._split_heads(fused_qkv)
+ batch_size, q_length, H, D_HEAD = query_layer.shape
+ k = key_layer.reshape(-1, H, D_HEAD) # batch_size * q_length, H, D_HEAD, q_lenth == 1
+ v = value_layer.reshape(-1, H, D_HEAD) # batch_size * q_length, H, D_HEAD, q_lenth == 1
+
+ mem_manager = infer_state.cache_manager
+ layer_id = infer_state.decode_layer_id
+
+ if infer_state.is_context_stage:
+ # context process
+ max_input_len = q_length
+ b_start_loc = infer_state.start_loc
+ b_seq_len = infer_state.seq_len[:batch_size]
+ q = query_layer.reshape(-1, H, D_HEAD)
+
+ copy_kv_cache_to_dest(k, infer_state.context_mem_index, mem_manager.key_buffer[layer_id])
+ copy_kv_cache_to_dest(v, infer_state.context_mem_index, mem_manager.value_buffer[layer_id])
+
+ # output = self.output[:batch_size*q_length, :, :]
+ output = torch.empty_like(q)
+
+ if HAS_LIGHTLLM_KERNEL:
+ lightllm_bloom_context_attention_fwd(q, k, v, output, alibi, b_start_loc, b_seq_len, max_input_len)
+ else:
+ bloom_context_attn_fwd(q, k, v, output, b_start_loc, b_seq_len, max_input_len, alibi)
+
+ context_layer = output.view(batch_size, q_length, H * D_HEAD)
+ else:
+ # query_layer = query_layer.transpose(1, 2).reshape(batch_size * self.num_heads, q_length, self.head_dim)
+ # need shape: batch_size, H, D_HEAD (q_length == 1), input q shape : (batch_size, q_length(1), H, D_HEAD)
+ assert q_length == 1, "for non-context process, we only support q_length == 1"
+ q = query_layer.reshape(-1, H, D_HEAD)
+
+ if infer_state.decode_is_contiguous:
+ # if decode is contiguous, then we copy to key cache and value cache in cache manager directly
+ cache_k = infer_state.cache_manager.key_buffer[layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_v = infer_state.cache_manager.value_buffer[layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_k.copy_(k)
+ cache_v.copy_(v)
+ else:
+ # if decode is not contiguous, use triton kernel to copy key and value cache
+ # k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head]
+ copy_kv_cache_to_dest(k, infer_state.decode_mem_index, mem_manager.key_buffer[layer_id])
+ copy_kv_cache_to_dest(v, infer_state.decode_mem_index, mem_manager.value_buffer[layer_id])
+
+ b_start_loc = infer_state.start_loc
+ b_loc = infer_state.block_loc
+ b_seq_len = infer_state.seq_len
+ output = torch.empty_like(q)
+ token_attention_fwd(
+ q,
+ mem_manager.key_buffer[layer_id],
+ mem_manager.value_buffer[layer_id],
+ output,
+ b_loc,
+ b_start_loc,
+ b_seq_len,
+ infer_state.max_len_in_batch,
+ alibi,
+ )
+
+ context_layer = output.view(batch_size, q_length, H * D_HEAD)
+
+ # NOTE: always set present as none for now, instead of returning past key value to the next decoding,
+ # we create the past key value pair from the cache manager
+ present = None
+
+ # aggregate results across tp ranks. See here: https://github.com/pytorch/pytorch/issues/76232
+ if self.pretraining_tp > 1 and self.slow_but_exact:
+ slices = self.hidden_size / self.pretraining_tp
+ output_tensor = torch.zeros_like(context_layer)
+ for i in range(self.pretraining_tp):
+ output_tensor = output_tensor + F.linear(
+ context_layer[:, :, int(i * slices) : int((i + 1) * slices)],
+ self.dense.weight[:, int(i * slices) : int((i + 1) * slices)],
+ )
+ else:
+ output_tensor = self.dense(context_layer)
+
+ # dropout is not required here during inference
+ output_tensor = residual + output_tensor
+
+ outputs = (output_tensor, present)
+ assert output_attentions is False, "we do not support output_attentions at this time"
+
+ return outputs
diff --git a/colossalai/inference/engine/modeling/chatglm2.py b/colossalai/inference/engine/modeling/chatglm2.py
new file mode 100644
index 000000000000..56e777bb2b87
--- /dev/null
+++ b/colossalai/inference/engine/modeling/chatglm2.py
@@ -0,0 +1,492 @@
+from typing import List, Optional, Tuple
+
+import torch
+from transformers.utils import logging
+
+from colossalai.inference.kv_cache import BatchInferState
+from colossalai.kernel.triton.token_attention_kernel import Llama2TokenAttentionForwards
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer import ShardConfig
+from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import (
+ ChatGLMForConditionalGeneration,
+ ChatGLMModel,
+ GLMBlock,
+ GLMTransformer,
+ SelfAttention,
+ split_tensor_along_last_dim,
+)
+
+from ._utils import copy_kv_to_mem_cache
+
+try:
+ from lightllm.models.chatglm2.triton_kernel.rotary_emb import rotary_emb_fwd as chatglm2_rotary_emb_fwd
+ from lightllm.models.llama2.triton_kernel.context_flashattention_nopad import (
+ context_attention_fwd as lightllm_llama2_context_attention_fwd,
+ )
+
+ HAS_LIGHTLLM_KERNEL = True
+except:
+ print("please install lightllm from source to run inference: https://github.com/ModelTC/lightllm")
+ HAS_LIGHTLLM_KERNEL = False
+
+
+def get_masks(self, input_ids, past_length, padding_mask=None):
+ batch_size, seq_length = input_ids.shape
+ full_attention_mask = torch.ones(batch_size, seq_length, seq_length, device=input_ids.device)
+ full_attention_mask.tril_()
+ if past_length:
+ full_attention_mask = torch.cat(
+ (
+ torch.ones(batch_size, seq_length, past_length, device=input_ids.device),
+ full_attention_mask,
+ ),
+ dim=-1,
+ )
+
+ if padding_mask is not None:
+ full_attention_mask = full_attention_mask * padding_mask.unsqueeze(1)
+ if not past_length and padding_mask is not None:
+ full_attention_mask -= padding_mask.unsqueeze(-1) - 1
+ full_attention_mask = (full_attention_mask < 0.5).bool()
+ full_attention_mask.unsqueeze_(1)
+ return full_attention_mask
+
+
+def get_position_ids(batch_size, seq_length, device):
+ position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)
+ return position_ids
+
+
+class ChatGLM2InferenceForwards:
+ """
+ This class holds forwards for Chatglm2 inference.
+ We intend to replace the forward methods for ChatGLMModel, ChatGLMEecoderLayer, and ChatGLMAttention.
+ """
+
+ @staticmethod
+ def chatglm_for_conditional_generation_forward(
+ self: ChatGLMForConditionalGeneration,
+ input_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = True,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ return_last_logit: Optional[bool] = False,
+ infer_state: Optional[BatchInferState] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ shard_config: ShardConfig = None,
+ ):
+ logger = logging.get_logger(__name__)
+
+ if output_attentions:
+ logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
+ output_hidden_states = False
+
+ # If is first stage and hidden_states is not None, go throught lm_head first
+ if stage_manager.is_first_stage() and hidden_states is not None:
+ if return_last_logit:
+ hidden_states = hidden_states[-1:]
+ lm_logits = self.transformer.output_layer(hidden_states)
+ lm_logits = lm_logits.transpose(0, 1).contiguous()
+ return {"logits": lm_logits}
+
+ outputs = self.transformer(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ attention_mask=attention_mask,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ infer_state=infer_state,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ shard_config=shard_config,
+ )
+
+ return outputs
+
+ @staticmethod
+ def chatglm_model_forward(
+ self: ChatGLMModel,
+ input_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.BoolTensor] = None,
+ full_attention_mask: Optional[torch.BoolTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ shard_config: ShardConfig = None,
+ ):
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+
+ if stage_manager.is_first_stage():
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+ if inputs_embeds is None:
+ inputs_embeds = self.embedding(input_ids)
+ if position_ids is None:
+ position_ids = get_position_ids(batch_size, seq_length, input_ids.device)
+ hidden_states = inputs_embeds
+ else:
+ assert hidden_states is not None, "hidden_states should not be None in non-first stage"
+ seq_length, batch_size, _ = hidden_states.shape
+ if position_ids is None:
+ position_ids = get_position_ids(batch_size, seq_length, hidden_states.device)
+
+ if infer_state.is_context_stage:
+ past_key_values_length = 0
+ else:
+ past_key_values_length = infer_state.max_len_in_batch - 1
+
+ seq_length_with_past = seq_length + past_key_values_length
+
+ # prefill stage at first
+ if seq_length != 1:
+ infer_state.is_context_stage = True
+ infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
+ infer_state.init_block_loc(
+ infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
+ )
+ else:
+ infer_state.is_context_stage = False
+ alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
+ if alloc_mem is not None:
+ infer_state.decode_is_contiguous = True
+ infer_state.decode_mem_index = alloc_mem[0]
+ infer_state.decode_mem_start = alloc_mem[1]
+ infer_state.decode_mem_end = alloc_mem[2]
+ infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
+ else:
+ print(f" *** Encountered allocation non-contiguous")
+ print(
+ f" infer_state.cache_manager.past_key_values_length: {infer_state.cache_manager.past_key_values_length}"
+ )
+ infer_state.decode_is_contiguous = False
+ alloc_mem = infer_state.cache_manager.alloc(batch_size)
+ infer_state.decode_mem_index = alloc_mem
+ infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
+
+ # related to rotary embedding
+ if infer_state.is_context_stage:
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
+ position_ids.view(-1).shape[0], -1
+ )
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
+ position_ids.view(-1).shape[0], -1
+ )
+ else:
+ seq_len = infer_state.seq_len
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
+ infer_state.other_kv_index = infer_state.block_loc[0, infer_state.max_len_in_batch - 1].item()
+
+ if self.pre_seq_len is not None:
+ if past_key_values is None:
+ past_key_values = self.get_prompt(
+ batch_size=batch_size,
+ device=input_ids.device,
+ dtype=inputs_embeds.dtype,
+ )
+ if attention_mask is not None:
+ attention_mask = torch.cat(
+ [
+ attention_mask.new_ones((batch_size, self.pre_seq_len)),
+ attention_mask,
+ ],
+ dim=-1,
+ )
+ if full_attention_mask is None:
+ if (attention_mask is not None and not attention_mask.all()) or (past_key_values and seq_length != 1):
+ full_attention_mask = get_masks(
+ self, input_ids, infer_state.cache_manager.past_key_values_length, padding_mask=attention_mask
+ )
+
+ # Run encoder.
+ hidden_states = self.encoder(
+ hidden_states,
+ full_attention_mask,
+ kv_caches=past_key_values,
+ use_cache=use_cache,
+ output_hidden_states=output_hidden_states,
+ infer_state=infer_state,
+ stage_manager=stage_manager,
+ stage_index=stage_index,
+ shard_config=shard_config,
+ )
+
+ # update indices
+ infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
+ infer_state.seq_len += 1
+ infer_state.max_len_in_batch += 1
+
+ return {"hidden_states": hidden_states}
+
+ @staticmethod
+ def chatglm_encoder_forward(
+ self: GLMTransformer,
+ hidden_states,
+ attention_mask,
+ kv_caches=None,
+ use_cache: Optional[bool] = True,
+ output_hidden_states: Optional[bool] = False,
+ infer_state: Optional[BatchInferState] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ stage_index: Optional[List[int]] = None,
+ shard_config: ShardConfig = None,
+ ):
+ hidden_states = hidden_states.transpose(0, 1).contiguous()
+
+ infer_state.decode_layer_id = 0
+ start_idx, end_idx = stage_index[0], stage_index[1]
+ if kv_caches is None:
+ kv_caches = tuple([None] * (end_idx - start_idx + 1))
+
+ for idx, kv_cache in zip(range(start_idx, end_idx), kv_caches):
+ layer = self.layers[idx]
+ layer_ret = layer(
+ hidden_states,
+ attention_mask,
+ kv_cache=kv_cache,
+ use_cache=use_cache,
+ infer_state=infer_state,
+ )
+ infer_state.decode_layer_id += 1
+
+ hidden_states, _ = layer_ret
+
+ hidden_states = hidden_states.transpose(0, 1).contiguous()
+
+ if self.post_layer_norm and (stage_manager.is_last_stage() or stage_manager.num_stages == 1):
+ # Final layer norm.
+ hidden_states = self.final_layernorm(hidden_states)
+
+ return hidden_states
+
+ @staticmethod
+ def chatglm_glmblock_forward(
+ self: GLMBlock,
+ hidden_states,
+ attention_mask,
+ kv_cache=None,
+ use_cache=True,
+ infer_state: Optional[BatchInferState] = None,
+ ):
+ # hidden_states: [s, b, h]
+
+ # Layer norm at the beginning of the transformer layer.
+ layernorm_output = self.input_layernorm(hidden_states)
+ # Self attention.
+ attention_output, kv_cache = self.self_attention(
+ layernorm_output,
+ attention_mask,
+ kv_cache=kv_cache,
+ use_cache=use_cache,
+ infer_state=infer_state,
+ )
+ # Residual connection.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = hidden_states
+ layernorm_input = torch.nn.functional.dropout(attention_output, p=self.hidden_dropout, training=self.training)
+ layernorm_input = residual + layernorm_input
+ # Layer norm post the self attention.
+ layernorm_output = self.post_attention_layernorm(layernorm_input)
+ # MLP.
+ mlp_output = self.mlp(layernorm_output)
+
+ # Second residual connection.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = layernorm_input
+
+ output = torch.nn.functional.dropout(mlp_output, p=self.hidden_dropout, training=self.training)
+ output = residual + output
+ return output, kv_cache
+
+ @staticmethod
+ def chatglm_flash_attn_kvcache_forward(
+ self: SelfAttention,
+ hidden_states,
+ attention_mask,
+ kv_cache=None,
+ use_cache=True,
+ infer_state: Optional[BatchInferState] = None,
+ ):
+ assert use_cache is True, "use_cache should be set to True using this chatglm attention"
+ # hidden_states: original :[sq, b, h] --> this [b, sq, h]
+ batch_size = hidden_states.shape[0]
+ hidden_size = hidden_states.shape[-1]
+ # Attention heads [sq, b, h] --> [sq, b, (np * 3 * hn)]
+ mixed_x_layer = self.query_key_value(hidden_states)
+ if self.multi_query_attention:
+ (query_layer, key_layer, value_layer) = mixed_x_layer.split(
+ [
+ self.num_attention_heads_per_partition * self.hidden_size_per_attention_head,
+ self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
+ self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
+ ],
+ dim=-1,
+ )
+ query_layer = query_layer.view(
+ query_layer.size()[:-1]
+ + (
+ self.num_attention_heads_per_partition,
+ self.hidden_size_per_attention_head,
+ )
+ )
+ key_layer = key_layer.view(
+ key_layer.size()[:-1]
+ + (
+ self.num_multi_query_groups_per_partition,
+ self.hidden_size_per_attention_head,
+ )
+ )
+ value_layer = value_layer.view(
+ value_layer.size()[:-1]
+ + (
+ self.num_multi_query_groups_per_partition,
+ self.hidden_size_per_attention_head,
+ )
+ )
+
+ else:
+ new_tensor_shape = mixed_x_layer.size()[:-1] + (
+ self.num_attention_heads_per_partition,
+ 3 * self.hidden_size_per_attention_head,
+ )
+ mixed_x_layer = mixed_x_layer.view(*new_tensor_shape)
+ # [sq, b, np, 3 * hn] --> 3 [sq, b, np, hn]
+ (query_layer, key_layer, value_layer) = split_tensor_along_last_dim(mixed_x_layer, 3)
+ cos, sin = infer_state.position_cos, infer_state.position_sin
+
+ chatglm2_rotary_emb_fwd(
+ query_layer.view(-1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head), cos, sin
+ )
+ if self.multi_query_attention:
+ chatglm2_rotary_emb_fwd(
+ key_layer.view(-1, self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head),
+ cos,
+ sin,
+ )
+ else:
+ chatglm2_rotary_emb_fwd(
+ key_layer.view(-1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head),
+ cos,
+ sin,
+ )
+
+ # reshape q k v to [bsz*sql, num_heads, head_dim] 2*1 ,32/2 ,128
+ query_layer = query_layer.reshape(
+ -1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head
+ )
+ key_layer = key_layer.reshape(
+ -1, self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head
+ )
+ value_layer = value_layer.reshape(
+ -1, self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head
+ )
+
+ if infer_state.is_context_stage:
+ # first token generation:
+ # copy key and value calculated in current step to memory manager
+ copy_kv_to_mem_cache(
+ infer_state.decode_layer_id,
+ key_layer,
+ value_layer,
+ infer_state.context_mem_index,
+ infer_state.cache_manager,
+ )
+ attn_output = torch.empty_like(query_layer.contiguous().view(-1, self.projection_size))
+
+ # NOTE: no bug in context attn fwd (del it )
+ lightllm_llama2_context_attention_fwd(
+ query_layer,
+ key_layer,
+ value_layer,
+ attn_output.view(-1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head),
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+
+ else:
+ if infer_state.decode_is_contiguous:
+ # if decode is contiguous, then we copy to key cache and value cache in cache manager directly
+ cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_k.copy_(key_layer)
+ cache_v.copy_(value_layer)
+ else:
+ # if decode is not contiguous, use triton kernel to copy key and value cache
+ # k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head
+ copy_kv_to_mem_cache(
+ infer_state.decode_layer_id,
+ key_layer,
+ value_layer,
+ infer_state.decode_mem_index,
+ infer_state.cache_manager,
+ )
+
+ # second token and follows
+ attn_output = torch.empty_like(query_layer.contiguous().view(-1, self.projection_size))
+ cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
+ : infer_state.decode_mem_end, :, :
+ ]
+ cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
+ : infer_state.decode_mem_end, :, :
+ ]
+
+ # ==================================
+ # core attention computation is replaced by triton kernel
+ # ==================================
+ Llama2TokenAttentionForwards.token_attn(
+ query_layer,
+ cache_k,
+ cache_v,
+ attn_output,
+ infer_state.block_loc,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ infer_state.other_kv_index,
+ )
+
+ # =================
+ # Output:[b,sq, h]
+ # =================
+ output = self.dense(attn_output).reshape(batch_size, -1, hidden_size)
+
+ return output, kv_cache
diff --git a/colossalai/inference/engine/modeling/llama.py b/colossalai/inference/engine/modeling/llama.py
new file mode 100644
index 000000000000..a7efb4026be0
--- /dev/null
+++ b/colossalai/inference/engine/modeling/llama.py
@@ -0,0 +1,503 @@
+# This code is adapted from huggingface transformers: https://github.com/huggingface/transformers/blob/v4.34.1/src/transformers/models/llama/modeling_llama.py
+import math
+from typing import List, Optional, Tuple
+
+import torch
+from transformers.models.llama.modeling_llama import LlamaAttention, LlamaDecoderLayer, LlamaForCausalLM, LlamaModel
+from transformers.utils import logging
+
+from colossalai.inference.kv_cache.batch_infer_state import BatchInferState
+from colossalai.kernel.triton import llama_context_attn_fwd, token_attention_fwd
+from colossalai.kernel.triton.token_attention_kernel import Llama2TokenAttentionForwards
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
+from ._utils import copy_kv_to_mem_cache
+
+try:
+ from lightllm.models.llama2.triton_kernel.context_flashattention_nopad import (
+ context_attention_fwd as lightllm_llama2_context_attention_fwd,
+ )
+ from lightllm.models.llama.triton_kernel.context_flashattention_nopad import (
+ context_attention_fwd as lightllm_context_attention_fwd,
+ )
+ from lightllm.models.llama.triton_kernel.rotary_emb import rotary_emb_fwd as llama_rotary_embedding_fwd
+
+ HAS_LIGHTLLM_KERNEL = True
+except:
+ print("please install lightllm from source to run inference: https://github.com/ModelTC/lightllm")
+ HAS_LIGHTLLM_KERNEL = False
+
+try:
+ from colossalai.kernel.triton.flash_decoding import token_flash_decoding
+
+ HAS_TRITON_FLASH_DECODING_KERNEL = True
+except:
+ print(
+ "no triton flash decoding support, please install lightllm from https://github.com/ModelTC/lightllm/blob/ece7b43f8a6dfa74027adc77c2c176cff28c76c8"
+ )
+ HAS_TRITON_FLASH_DECODING_KERNEL = False
+
+try:
+ from flash_attn import flash_attn_with_kvcache
+
+ HAS_FLASH_KERNEL = True
+except:
+ HAS_FLASH_KERNEL = False
+ print("please install flash attentiom from https://github.com/Dao-AILab/flash-attention")
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
+ # The first two dimensions of cos and sin are always 1, so we can `squeeze` them.
+ cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
+ sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
+ cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+ sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+def llama_triton_context_attention(
+ query_states, key_states, value_states, attn_output, infer_state, num_key_value_groups=1
+):
+ if num_key_value_groups == 1:
+ if HAS_LIGHTLLM_KERNEL is False:
+ llama_context_attn_fwd(
+ query_states,
+ key_states,
+ value_states,
+ attn_output,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+ else:
+ lightllm_context_attention_fwd(
+ query_states,
+ key_states,
+ value_states,
+ attn_output,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+ else:
+ assert HAS_LIGHTLLM_KERNEL is True, "You have to install lightllm kernels to run llama2 model"
+ lightllm_llama2_context_attention_fwd(
+ query_states,
+ key_states,
+ value_states,
+ attn_output,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+
+
+def llama_triton_token_attention(
+ query_states, attn_output, infer_state, num_key_value_groups=1, q_head_num=-1, head_dim=-1
+):
+ if HAS_TRITON_FLASH_DECODING_KERNEL and q_head_num != -1 and head_dim != -1:
+ token_flash_decoding(
+ q=query_states,
+ o_tensor=attn_output,
+ infer_state=infer_state,
+ q_head_num=q_head_num,
+ head_dim=head_dim,
+ cache_k=infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
+ cache_v=infer_state.cache_manager.value_buffer[infer_state.decode_layer_id],
+ )
+ return
+
+ if num_key_value_groups == 1:
+ token_attention_fwd(
+ query_states,
+ infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
+ infer_state.cache_manager.value_buffer[infer_state.decode_layer_id],
+ attn_output,
+ infer_state.block_loc,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+ else:
+ Llama2TokenAttentionForwards.token_attn(
+ query_states,
+ infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
+ infer_state.cache_manager.value_buffer[infer_state.decode_layer_id],
+ attn_output,
+ infer_state.block_loc,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ infer_state.other_kv_index,
+ )
+
+
+class LlamaInferenceForwards:
+ """
+ This class holds forwards for llama inference.
+ We intend to replace the forward methods for LlamaModel, LlamaDecoderLayer, and LlamaAttention for LlamaForCausalLM.
+ """
+
+ @staticmethod
+ def llama_causal_lm_forward(
+ self: LlamaForCausalLM,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ """
+ logger = logging.get_logger(__name__)
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if output_attentions:
+ logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
+ output_hidden_states = False
+
+ # If is first stage and hidden_states is None, go throught lm_head first
+ if stage_manager.is_first_stage() and hidden_states is not None:
+ lm_logits = self.lm_head(hidden_states)
+ return {"logits": lm_logits}
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = LlamaInferenceForwards.llama_model_forward(
+ self.model,
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ infer_state=infer_state,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ )
+
+ return outputs
+
+ @staticmethod
+ def llama_model_forward(
+ self: LlamaModel,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ # retrieve input_ids and inputs_embeds
+ if stage_manager is None or stage_manager.is_first_stage():
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+ hidden_states = inputs_embeds
+ else:
+ assert stage_manager is not None
+ assert hidden_states is not None, f"hidden_state should not be none in stage {stage_manager.stage}"
+ input_shape = hidden_states.shape[:-1]
+ batch_size, seq_length = input_shape
+ device = hidden_states.device
+
+ if infer_state.is_context_stage:
+ past_key_values_length = 0
+ else:
+ past_key_values_length = infer_state.max_len_in_batch - 1
+
+ # NOTE: differentiate with prefill stage
+ # block_loc require different value-assigning method for two different stage
+ if use_cache and seq_length != 1:
+ # NOTE assume prefill stage
+ # allocate memory block
+ infer_state.is_context_stage = True # set prefill stage, notify attention layer
+ infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
+ infer_state.init_block_loc(
+ infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
+ )
+ else:
+ infer_state.is_context_stage = False
+ alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
+ if alloc_mem is not None:
+ infer_state.decode_is_contiguous = True
+ infer_state.decode_mem_index = alloc_mem[0]
+ infer_state.decode_mem_start = alloc_mem[1]
+ infer_state.decode_mem_end = alloc_mem[2]
+ infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
+ else:
+ infer_state.decode_is_contiguous = False
+ alloc_mem = infer_state.cache_manager.alloc(batch_size)
+ infer_state.decode_mem_index = alloc_mem
+ infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
+
+ if position_ids is None:
+ position_ids = torch.arange(
+ past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
+ )
+ position_ids = position_ids.repeat(batch_size, 1)
+ position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
+ else:
+ position_ids = position_ids.view(-1, seq_length).long()
+
+ if infer_state.is_context_stage:
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
+ position_ids.view(-1).shape[0], -1
+ )
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
+ position_ids.view(-1).shape[0], -1
+ )
+
+ else:
+ seq_len = infer_state.seq_len
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
+ infer_state.other_kv_index = infer_state.block_loc[0, infer_state.max_len_in_batch - 1].item()
+
+ # embed positions
+ if attention_mask is None:
+ attention_mask = torch.ones(
+ (batch_size, infer_state.max_len_in_batch), dtype=torch.bool, device=hidden_states.device
+ )
+
+ attention_mask = self._prepare_decoder_attention_mask(
+ attention_mask, (batch_size, seq_length), hidden_states, past_key_values_length
+ )
+
+ # decoder layers
+ infer_state.decode_layer_id = 0
+
+ start_idx, end_idx = stage_index[0], stage_index[1]
+ if past_key_values is None:
+ past_key_values = tuple([None] * (end_idx - start_idx + 1))
+
+ for idx, past_key_value in zip(range(start_idx, end_idx), past_key_values):
+ decoder_layer = self.layers[idx]
+ # NOTE: modify here for passing args to decoder layer
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ infer_state=infer_state,
+ )
+ infer_state.decode_layer_id += 1
+ hidden_states = layer_outputs[0]
+
+ if stage_manager.is_last_stage() or stage_manager.num_stages == 1:
+ hidden_states = self.norm(hidden_states)
+
+ # update indices
+ # infer_state.block_loc[:, infer_state.max_len_in_batch-1] = infer_state.total_token_num + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
+ infer_state.start_loc += torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
+ infer_state.seq_len += 1
+ infer_state.max_len_in_batch += 1
+
+ return {"hidden_states": hidden_states}
+
+ @staticmethod
+ def llama_decoder_layer_forward(
+ self: LlamaDecoderLayer,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ infer_state: Optional[BatchInferState] = None,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ infer_state=infer_state,
+ )
+
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+ @staticmethod
+ def llama_flash_attn_kvcache_forward(
+ self: LlamaAttention,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ infer_state: Optional[BatchInferState] = None,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ assert use_cache is True, "use_cache should be set to True using this llama attention"
+
+ bsz, q_len, _ = hidden_states.size()
+
+ # NOTE might think about better way to handle transposed k and v
+ # key_states [bs, seq_len, num_heads, head_dim/embed_size_per_head]
+ # key_states_transposed [bs, num_heads, seq_len, head_dim/embed_size_per_head]
+
+ query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim)
+ key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_key_value_heads, self.head_dim)
+ value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_key_value_heads, self.head_dim)
+
+ # NOTE might want to revise
+ # need some way to record the length of past key values cache
+ # since we won't return past_key_value_cache right now
+
+ cos, sin = infer_state.position_cos, infer_state.position_sin
+
+ llama_rotary_embedding_fwd(query_states.view(-1, self.num_heads, self.head_dim), cos, sin)
+ llama_rotary_embedding_fwd(key_states.view(-1, self.num_key_value_heads, self.head_dim), cos, sin)
+
+ query_states = query_states.reshape(-1, self.num_heads, self.head_dim)
+ key_states = key_states.reshape(-1, self.num_key_value_heads, self.head_dim)
+ value_states = value_states.reshape(-1, self.num_key_value_heads, self.head_dim)
+
+ if infer_state.is_context_stage:
+ # first token generation
+ # copy key and value calculated in current step to memory manager
+ copy_kv_to_mem_cache(
+ infer_state.decode_layer_id,
+ key_states,
+ value_states,
+ infer_state.context_mem_index,
+ infer_state.cache_manager,
+ )
+ attn_output = torch.empty_like(query_states)
+
+ llama_triton_context_attention(
+ query_states,
+ key_states,
+ value_states,
+ attn_output,
+ infer_state,
+ num_key_value_groups=self.num_key_value_groups,
+ )
+ else:
+ if infer_state.decode_is_contiguous:
+ # if decode is contiguous, then we copy to key cache and value cache in cache manager directly
+ cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_k.copy_(key_states)
+ cache_v.copy_(value_states)
+ else:
+ # if decode is not contiguous, use triton kernel to copy key and value cache
+ # k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head
+ copy_kv_to_mem_cache(
+ infer_state.decode_layer_id,
+ key_states,
+ value_states,
+ infer_state.decode_mem_index,
+ infer_state.cache_manager,
+ )
+
+ if HAS_LIGHTLLM_KERNEL:
+ attn_output = torch.empty_like(query_states)
+ llama_triton_token_attention(
+ query_states=query_states,
+ attn_output=attn_output,
+ infer_state=infer_state,
+ num_key_value_groups=self.num_key_value_groups,
+ q_head_num=q_len * self.num_heads,
+ head_dim=self.head_dim,
+ )
+ else:
+ self.num_heads // self.num_key_value_heads
+ cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id]
+ cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id]
+
+ query_states = query_states.view(bsz, -1, self.num_heads, self.head_dim)
+ copy_cache_k = cache_k.view(bsz, -1, self.num_key_value_heads, self.head_dim)
+ copy_cache_v = cache_v.view(bsz, -1, self.num_key_value_heads, self.head_dim)
+
+ attn_output = flash_attn_with_kvcache(
+ q=query_states,
+ k_cache=copy_cache_k,
+ v_cache=copy_cache_v,
+ softmax_scale=1 / math.sqrt(self.head_dim),
+ causal=True,
+ )
+
+ attn_output = attn_output.view(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ # return past_key_value as None
+ return attn_output, None, None
diff --git a/colossalai/inference/engine/policies/__init__.py b/colossalai/inference/engine/policies/__init__.py
new file mode 100644
index 000000000000..269d1c57b276
--- /dev/null
+++ b/colossalai/inference/engine/policies/__init__.py
@@ -0,0 +1,11 @@
+from .bloom import BloomModelInferPolicy
+from .chatglm2 import ChatGLM2InferPolicy
+from .llama import LlamaModelInferPolicy
+
+model_policy_map = {
+ "llama": LlamaModelInferPolicy,
+ "bloom": BloomModelInferPolicy,
+ "chatglm": ChatGLM2InferPolicy,
+}
+
+__all__ = ["LlamaModelInferPolicy", "BloomModelInferPolicy", "ChatGLM2InferPolicy", "model_polic_map"]
diff --git a/colossalai/inference/engine/policies/bloom.py b/colossalai/inference/engine/policies/bloom.py
new file mode 100644
index 000000000000..5bc47c3c1a49
--- /dev/null
+++ b/colossalai/inference/engine/policies/bloom.py
@@ -0,0 +1,127 @@
+from functools import partial
+from typing import List
+
+import torch
+from torch.nn import LayerNorm, Module
+
+import colossalai.shardformer.layer as col_nn
+from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
+from colossalai.shardformer.policies.bloom import BloomForCausalLMPolicy
+
+from ..modeling.bloom import BloomInferenceForwards
+
+try:
+ from colossalai.kernel.triton import layer_norm
+
+ HAS_TRITON_NORM = True
+except:
+ print("Some of our kernels require triton. You might want to install triton from https://github.com/openai/triton")
+ HAS_TRITON_NORM = False
+
+
+def get_triton_layernorm_forward():
+ if HAS_TRITON_NORM:
+
+ def _triton_layernorm_forward(self: LayerNorm, hidden_states: torch.Tensor):
+ return layer_norm(hidden_states, self.weight.data, self.bias, self.eps)
+
+ return _triton_layernorm_forward
+ else:
+ return None
+
+
+class BloomModelInferPolicy(BloomForCausalLMPolicy):
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ from transformers.models.bloom.modeling_bloom import BloomAttention, BloomBlock, BloomForCausalLM, BloomModel
+
+ policy = super().module_policy()
+ if self.shard_config.extra_kwargs.get("quant", None) == "gptq":
+ from colossalai.inference.quant.gptq.cai_gptq import ColCaiQuantLinear, RowCaiQuantLinear
+
+ policy[BloomBlock] = ModulePolicyDescription(
+ attribute_replacement={
+ "self_attention.hidden_size": self.model.config.hidden_size
+ // self.shard_config.tensor_parallel_size,
+ "self_attention.split_size": self.model.config.hidden_size
+ // self.shard_config.tensor_parallel_size,
+ "self_attention.num_heads": self.model.config.n_head // self.shard_config.tensor_parallel_size,
+ },
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attention.query_key_value",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 3},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attention.dense", target_module=RowCaiQuantLinear, kwargs={"split_num": 1}
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attention.attention_dropout",
+ target_module=col_nn.DropoutForParallelInput,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.dense_h_to_4h", target_module=ColCaiQuantLinear, kwargs={"split_num": 1}
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.dense_4h_to_h", target_module=RowCaiQuantLinear, kwargs={"split_num": 1}
+ ),
+ ],
+ )
+ # NOTE set inference mode to shard config
+ self.shard_config._infer()
+
+ # set as default, in inference we also use pipeline style forward, just setting stage as 1
+ self.set_pipeline_forward(
+ model_cls=BloomForCausalLM,
+ new_forward=partial(
+ BloomInferenceForwards.bloom_for_causal_lm_forward,
+ tp_group=self.shard_config.tensor_parallel_process_group,
+ ),
+ policy=policy,
+ )
+
+ method_replacement = {"forward": BloomInferenceForwards.bloom_model_forward}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=BloomModel)
+
+ method_replacement = {"forward": BloomInferenceForwards.bloom_block_forward}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=BloomBlock)
+
+ method_replacement = {"forward": BloomInferenceForwards.bloom_attention_forward}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=BloomAttention
+ )
+
+ if HAS_TRITON_NORM:
+ infer_method = get_triton_layernorm_forward()
+ method_replacement = {"forward": partial(infer_method)}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=LayerNorm
+ )
+
+ return policy
+
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ assert self.pipeline_stage_manager is not None
+
+ if self.model.__class__.__name__ == "BloomModel":
+ module = self.model
+ else:
+ module = self.model.transformer
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = stage_manager.distribute_layers(len(module.h))
+ if stage_manager.is_first_stage():
+ held_layers.append(module.word_embeddings)
+ held_layers.append(module.word_embeddings_layernorm)
+ held_layers.append(self.model.lm_head)
+ start_idx, end_idx = stage_manager.get_stage_index(layers_per_stage)
+ held_layers.extend(module.h[start_idx:end_idx])
+ if stage_manager.is_last_stage():
+ held_layers.append(module.ln_f)
+
+ return held_layers
diff --git a/colossalai/inference/engine/policies/chatglm2.py b/colossalai/inference/engine/policies/chatglm2.py
new file mode 100644
index 000000000000..c7c6f3b927e1
--- /dev/null
+++ b/colossalai/inference/engine/policies/chatglm2.py
@@ -0,0 +1,89 @@
+from typing import List
+
+import torch.nn as nn
+
+from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import (
+ ChatGLMForConditionalGeneration,
+ ChatGLMModel,
+ GLMBlock,
+ GLMTransformer,
+ SelfAttention,
+)
+
+# import colossalai
+from colossalai.shardformer.policies.chatglm2 import ChatGLMModelPolicy
+
+from ..modeling._utils import init_to_get_rotary
+from ..modeling.chatglm2 import ChatGLM2InferenceForwards
+
+try:
+ HAS_TRITON_RMSNORM = True
+except:
+ print("you should install triton from https://github.com/openai/triton")
+ HAS_TRITON_RMSNORM = False
+
+
+class ChatGLM2InferPolicy(ChatGLMModelPolicy):
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ policy = super().module_policy()
+ self.shard_config._infer()
+
+ model_infer_forward = ChatGLM2InferenceForwards.chatglm_model_forward
+ method_replacement = {"forward": model_infer_forward}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=ChatGLMModel)
+
+ encoder_infer_forward = ChatGLM2InferenceForwards.chatglm_encoder_forward
+ method_replacement = {"forward": encoder_infer_forward}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=GLMTransformer
+ )
+
+ encoder_layer_infer_forward = ChatGLM2InferenceForwards.chatglm_glmblock_forward
+ method_replacement = {"forward": encoder_layer_infer_forward}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=GLMBlock)
+
+ attn_infer_forward = ChatGLM2InferenceForwards.chatglm_flash_attn_kvcache_forward
+ method_replacement = {"forward": attn_infer_forward}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=SelfAttention
+ )
+ if self.shard_config.enable_tensor_parallelism:
+ policy[GLMBlock].attribute_replacement["self_attention.num_multi_query_groups_per_partition"] = (
+ self.model.config.multi_query_group_num // self.shard_config.tensor_parallel_size
+ )
+ # for rmsnorm and others, we need to check the shape
+
+ self.set_pipeline_forward(
+ model_cls=ChatGLMForConditionalGeneration,
+ new_forward=ChatGLM2InferenceForwards.chatglm_for_conditional_generation_forward,
+ policy=policy,
+ )
+
+ return policy
+
+ def get_held_layers(self) -> List[nn.Module]:
+ module = self.model.transformer
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = stage_manager.distribute_layers(module.num_layers)
+ if stage_manager.is_first_stage():
+ held_layers.append(module.embedding)
+ held_layers.append(module.output_layer)
+ start_idx, end_idx = stage_manager.get_stage_index(layers_per_stage)
+ held_layers.extend(module.encoder.layers[start_idx:end_idx])
+ if stage_manager.is_last_stage():
+ if module.encoder.post_layer_norm:
+ held_layers.append(module.encoder.final_layernorm)
+
+ # rotary_pos_emb is needed for all stages
+ held_layers.append(module.rotary_pos_emb)
+
+ return held_layers
+
+ def postprocess(self):
+ init_to_get_rotary(self.model.transformer)
+ return self.model
diff --git a/colossalai/inference/engine/policies/llama.py b/colossalai/inference/engine/policies/llama.py
new file mode 100644
index 000000000000..a57a4e50cdb9
--- /dev/null
+++ b/colossalai/inference/engine/policies/llama.py
@@ -0,0 +1,206 @@
+from functools import partial
+from typing import List
+
+import torch
+from torch.nn import Module
+from transformers.models.llama.modeling_llama import (
+ LlamaAttention,
+ LlamaDecoderLayer,
+ LlamaForCausalLM,
+ LlamaModel,
+ LlamaRMSNorm,
+)
+
+from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
+
+# import colossalai
+from colossalai.shardformer.policies.llama import LlamaForCausalLMPolicy
+
+from ..modeling._utils import init_to_get_rotary
+from ..modeling.llama import LlamaInferenceForwards
+
+try:
+ from colossalai.kernel.triton import rmsnorm_forward
+
+ HAS_TRITON_RMSNORM = True
+except:
+ print("you should install triton from https://github.com/openai/triton")
+ HAS_TRITON_RMSNORM = False
+
+
+def get_triton_rmsnorm_forward():
+ if HAS_TRITON_RMSNORM:
+
+ def _triton_rmsnorm_forward(self: LlamaRMSNorm, hidden_states: torch.Tensor):
+ return rmsnorm_forward(hidden_states, self.weight.data, self.variance_epsilon)
+
+ return _triton_rmsnorm_forward
+ else:
+ return None
+
+
+class LlamaModelInferPolicy(LlamaForCausalLMPolicy):
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ policy = super().module_policy()
+ decoder_attribute_replacement = {
+ "self_attn.hidden_size": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
+ "self_attn.num_heads": self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
+ "self_attn.num_key_value_heads": self.model.config.num_key_value_heads
+ // self.shard_config.tensor_parallel_size,
+ }
+ if self.shard_config.extra_kwargs.get("quant", None) == "gptq":
+ from colossalai.inference.quant.gptq.cai_gptq import ColCaiQuantLinear, RowCaiQuantLinear
+
+ policy[LlamaDecoderLayer] = ModulePolicyDescription(
+ attribute_replacement=decoder_attribute_replacement,
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attn.q_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.k_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.v_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.o_proj",
+ target_module=RowCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.gate_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.up_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.down_proj",
+ target_module=RowCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ ],
+ )
+
+ elif self.shard_config.extra_kwargs.get("quant", None) == "smoothquant":
+ from colossalai.inference.quant.smoothquant.models.llama import LlamaSmoothquantDecoderLayer
+ from colossalai.inference.quant.smoothquant.models.parallel_linear import (
+ ColW8A8BFP32OFP32Linear,
+ RowW8A8B8O8Linear,
+ RowW8A8BFP32O32LinearSiLU,
+ RowW8A8BFP32OFP32Linear,
+ )
+
+ policy[LlamaSmoothquantDecoderLayer] = ModulePolicyDescription(
+ attribute_replacement=decoder_attribute_replacement,
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attn.q_proj",
+ target_module=RowW8A8B8O8Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.k_proj",
+ target_module=RowW8A8B8O8Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.v_proj",
+ target_module=RowW8A8B8O8Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.o_proj",
+ target_module=ColW8A8BFP32OFP32Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.gate_proj",
+ target_module=RowW8A8BFP32O32LinearSiLU,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.up_proj",
+ target_module=RowW8A8BFP32OFP32Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.down_proj",
+ target_module=ColW8A8BFP32OFP32Linear,
+ kwargs={"split_num": 1},
+ ),
+ ],
+ )
+ self.shard_config._infer()
+
+ infer_forward = LlamaInferenceForwards.llama_model_forward
+ method_replacement = {"forward": partial(infer_forward)}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=LlamaModel)
+
+ infer_forward = LlamaInferenceForwards.llama_decoder_layer_forward
+ method_replacement = {"forward": partial(infer_forward)}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=LlamaDecoderLayer
+ )
+
+ infer_forward = LlamaInferenceForwards.llama_flash_attn_kvcache_forward
+ method_replacement = {"forward": partial(infer_forward)}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=LlamaAttention
+ )
+
+ # set as default, in inference we also use pipeline style forward, just setting stage as 1
+ self.set_pipeline_forward(
+ model_cls=LlamaForCausalLM, new_forward=LlamaInferenceForwards.llama_causal_lm_forward, policy=policy
+ )
+
+ infer_forward = None
+ if HAS_TRITON_RMSNORM:
+ infer_forward = get_triton_rmsnorm_forward()
+
+ if infer_forward is not None:
+ method_replacement = {"forward": partial(infer_forward)}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=LlamaRMSNorm
+ )
+
+ return policy
+
+ def postprocess(self):
+ init_to_get_rotary(self.model.model)
+ return self.model
+
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ assert self.pipeline_stage_manager is not None
+
+ if self.model.__class__.__name__ == "LlamaModel":
+ module = self.model
+ else:
+ module = self.model.model
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = stage_manager.distribute_layers(len(module.layers))
+ if stage_manager.is_first_stage():
+ held_layers.append(module.embed_tokens)
+ held_layers.append(self.model.lm_head)
+ start_idx, end_idx = stage_manager.get_stage_index(layers_per_stage)
+ held_layers.extend(module.layers[start_idx:end_idx])
+ if stage_manager.is_last_stage():
+ held_layers.append(module.norm)
+
+ return held_layers
diff --git a/colossalai/inference/kv_cache/__init__.py b/colossalai/inference/kv_cache/__init__.py
new file mode 100644
index 000000000000..5b6ca182efae
--- /dev/null
+++ b/colossalai/inference/kv_cache/__init__.py
@@ -0,0 +1,2 @@
+from .batch_infer_state import BatchInferState
+from .kvcache_manager import MemoryManager
diff --git a/colossalai/inference/kv_cache/batch_infer_state.py b/colossalai/inference/kv_cache/batch_infer_state.py
new file mode 100644
index 000000000000..f707a86df37e
--- /dev/null
+++ b/colossalai/inference/kv_cache/batch_infer_state.py
@@ -0,0 +1,118 @@
+# might want to consider combine with InferenceConfig in colossalai/ppinference/inference_config.py later
+from dataclasses import dataclass
+
+import torch
+from transformers.tokenization_utils_base import BatchEncoding
+
+from .kvcache_manager import MemoryManager
+
+
+# adapted from: lightllm/server/router/model_infer/infer_batch.py
+@dataclass
+class BatchInferState:
+ r"""
+ Information to be passed and used for a batch of inputs during
+ a single model forward
+ """
+ batch_size: int
+ max_len_in_batch: int
+
+ cache_manager: MemoryManager = None
+
+ block_loc: torch.Tensor = None
+ start_loc: torch.Tensor = None
+ seq_len: torch.Tensor = None
+ past_key_values_len: int = None
+
+ is_context_stage: bool = False
+ context_mem_index: torch.Tensor = None
+ decode_is_contiguous: bool = None
+ decode_mem_start: int = None
+ decode_mem_end: int = None
+ decode_mem_index: torch.Tensor = None
+ decode_layer_id: int = None
+
+ device: torch.device = torch.device("cuda")
+
+ @property
+ def total_token_num(self):
+ # return self.batch_size * self.max_len_in_batch
+ assert self.seq_len is not None and self.seq_len.size(0) > 0
+ return int(torch.sum(self.seq_len))
+
+ def set_cache_manager(self, manager: MemoryManager):
+ self.cache_manager = manager
+
+ # adapted from: https://github.com/ModelTC/lightllm/blob/28c1267cfca536b7b4f28e921e03de735b003039/lightllm/common/infer_utils.py#L1
+ @staticmethod
+ def init_block_loc(
+ b_loc: torch.Tensor, seq_len: torch.Tensor, max_len_in_batch: int, alloc_mem_index: torch.Tensor
+ ):
+ """in-place update block loc mapping based on the sequence length of the inputs in current bath"""
+ start_index = 0
+ seq_len_numpy = seq_len.cpu().numpy()
+ for i, cur_seq_len in enumerate(seq_len_numpy):
+ b_loc[i, max_len_in_batch - cur_seq_len : max_len_in_batch] = alloc_mem_index[
+ start_index : start_index + cur_seq_len
+ ]
+ start_index += cur_seq_len
+ return
+
+ @classmethod
+ def init_from_batch(
+ cls,
+ batch: torch.Tensor,
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager: MemoryManager,
+ ):
+ if not isinstance(batch, (BatchEncoding, dict, list, torch.Tensor)):
+ raise TypeError(f"batch type {type(batch)} is not supported in prepare_batch_state")
+
+ input_ids_list = None
+ attention_mask = None
+
+ if isinstance(batch, (BatchEncoding, dict)):
+ input_ids_list = batch["input_ids"]
+ attention_mask = batch["attention_mask"]
+ else:
+ input_ids_list = batch
+ if isinstance(input_ids_list[0], int): # for a single input
+ input_ids_list = [input_ids_list]
+ attention_mask = [attention_mask] if attention_mask is not None else attention_mask
+
+ batch_size = len(input_ids_list)
+
+ seq_start_indexes = torch.zeros(batch_size, dtype=torch.int32, device="cuda")
+ seq_lengths = torch.zeros(batch_size, dtype=torch.int32, device="cuda")
+ start_index = 0
+
+ max_len_in_batch = -1
+ if isinstance(batch, (BatchEncoding, dict)):
+ for i, attn_mask in enumerate(attention_mask):
+ curr_seq_len = len(attn_mask)
+ seq_lengths[i] = curr_seq_len
+ seq_start_indexes[i] = start_index
+ start_index += curr_seq_len
+ max_len_in_batch = curr_seq_len if curr_seq_len > max_len_in_batch else max_len_in_batch
+ else:
+ length = max(len(input_id) for input_id in input_ids_list)
+ for i, input_ids in enumerate(input_ids_list):
+ curr_seq_len = length
+ seq_lengths[i] = curr_seq_len
+ seq_start_indexes[i] = start_index
+ start_index += curr_seq_len
+ max_len_in_batch = curr_seq_len if curr_seq_len > max_len_in_batch else max_len_in_batch
+ block_loc = torch.zeros((batch_size, max_input_len + max_output_len), dtype=torch.long, device="cuda")
+
+ return cls(
+ batch_size=batch_size,
+ max_len_in_batch=max_len_in_batch,
+ seq_len=seq_lengths.to("cuda"),
+ start_loc=seq_start_indexes.to("cuda"),
+ block_loc=block_loc,
+ decode_layer_id=0,
+ past_key_values_len=0,
+ is_context_stage=True,
+ cache_manager=cache_manager,
+ )
diff --git a/colossalai/inference/kv_cache/kvcache_manager.py b/colossalai/inference/kv_cache/kvcache_manager.py
new file mode 100644
index 000000000000..dda46a756cc3
--- /dev/null
+++ b/colossalai/inference/kv_cache/kvcache_manager.py
@@ -0,0 +1,106 @@
+"""
+Refered/Modified from lightllm/common/mem_manager.py
+of the ModelTC/lightllm GitHub repository
+https://github.com/ModelTC/lightllm/blob/050af3ce65edca617e2f30ec2479397d5bb248c9/lightllm/common/mem_manager.py
+we slightly changed it to make it suitable for our colossal-ai shardformer TP-engine design.
+"""
+import torch
+from transformers.utils import logging
+
+
+class MemoryManager:
+ r"""
+ Manage token block indexes and allocate physical memory for key and value cache
+
+ Args:
+ size: maximum token number used as the size of key and value buffer
+ dtype: data type of cached key and value
+ head_num: number of heads the memory manager is responsible for
+ head_dim: embedded size per head
+ layer_num: the number of layers in the model
+ device: device used to store the key and value cache
+ """
+
+ def __init__(
+ self,
+ size: int,
+ dtype: torch.dtype,
+ head_num: int,
+ head_dim: int,
+ layer_num: int,
+ device: torch.device = torch.device("cuda"),
+ ):
+ self.logger = logging.get_logger(__name__)
+ self.available_size = size
+ self.max_len_in_batch = 0
+ self._init_mem_states(size, device)
+ self._init_kv_buffers(size, device, dtype, head_num, head_dim, layer_num)
+
+ def _init_mem_states(self, size, device):
+ """Initialize tensors used to manage memory states"""
+ self.mem_state = torch.ones((size,), dtype=torch.bool, device=device)
+ self.mem_cum_sum = torch.empty((size,), dtype=torch.int32, device=device)
+ self.indexes = torch.arange(0, size, dtype=torch.long, device=device)
+
+ def _init_kv_buffers(self, size, device, dtype, head_num, head_dim, layer_num):
+ """Initialize key buffer and value buffer on specified device"""
+ self.key_buffer = [
+ torch.empty((size, head_num, head_dim), dtype=dtype, device=device) for _ in range(layer_num)
+ ]
+ self.value_buffer = [
+ torch.empty((size, head_num, head_dim), dtype=dtype, device=device) for _ in range(layer_num)
+ ]
+
+ @torch.no_grad()
+ def alloc(self, required_size):
+ """allocate space of required_size by providing indexes representing available physical spaces"""
+ if required_size > self.available_size:
+ self.logger.warning(f"No enough cache: required_size {required_size} " f"left_size {self.available_size}")
+ return None
+ torch.cumsum(self.mem_state, dim=0, dtype=torch.int32, out=self.mem_cum_sum)
+ select_index = torch.logical_and(self.mem_cum_sum <= required_size, self.mem_state == 1)
+ select_index = self.indexes[select_index]
+ self.mem_state[select_index] = 0
+ self.available_size -= len(select_index)
+ return select_index
+
+ @torch.no_grad()
+ def alloc_contiguous(self, required_size):
+ """allocate contiguous space of required_size"""
+ if required_size > self.available_size:
+ self.logger.warning(f"No enough cache: required_size {required_size} " f"left_size {self.available_size}")
+ return None
+ torch.cumsum(self.mem_state, dim=0, dtype=torch.int32, out=self.mem_cum_sum)
+ sum_size = len(self.mem_cum_sum)
+ loc_sums = (
+ self.mem_cum_sum[required_size - 1 :]
+ - self.mem_cum_sum[0 : sum_size - required_size + 1]
+ + self.mem_state[0 : sum_size - required_size + 1]
+ )
+ can_used_loc = self.indexes[0 : sum_size - required_size + 1][loc_sums == required_size]
+ if can_used_loc.shape[0] == 0:
+ self.logger.info(
+ f"No enough contiguous cache: required_size {required_size} " f"left_size {self.available_size}"
+ )
+ return None
+ start_loc = can_used_loc[0]
+ select_index = self.indexes[start_loc : start_loc + required_size]
+ self.mem_state[select_index] = 0
+ self.available_size -= len(select_index)
+ start = start_loc.item()
+ end = start + required_size
+ return select_index, start, end
+
+ @torch.no_grad()
+ def free(self, free_index):
+ """free memory by updating memory states based on given indexes"""
+ self.available_size += free_index.shape[0]
+ self.mem_state[free_index] = 1
+
+ @torch.no_grad()
+ def free_all(self):
+ """free all memory by updating memory states"""
+ self.available_size = len(self.mem_state)
+ self.mem_state[:] = 1
+ self.max_len_in_batch = 0
+ # self.logger.info("freed all space of memory manager")
diff --git a/colossalai/inference/pipeline/__init__.py b/colossalai/inference/pipeline/__init__.py
deleted file mode 100644
index 41af9f3ef948..000000000000
--- a/colossalai/inference/pipeline/__init__.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from .engine import PPInferEngine
-
-__all__ = ["PPInferEngine"]
diff --git a/colossalai/inference/pipeline/engine.py b/colossalai/inference/pipeline/engine.py
deleted file mode 100644
index 4f42385caf8f..000000000000
--- a/colossalai/inference/pipeline/engine.py
+++ /dev/null
@@ -1,97 +0,0 @@
-import torch
-import torch.nn as nn
-
-from colossalai.cluster import ProcessGroupMesh
-from colossalai.pipeline.schedule.generate import GenerateSchedule
-from colossalai.pipeline.stage_manager import PipelineStageManager
-from colossalai.shardformer import ShardConfig, ShardFormer
-from colossalai.shardformer.policies.base_policy import Policy
-
-from .microbatch_manager import MicroBatchManager
-
-
-class PPInferEngine:
- """
- PPInferEngine is a class that handles the pipeline parallel inference.
-
- Args:
- pp_size (int): the number of pipeline stages.
- pp_model (`nn.Module`): the model already in pipeline parallelism style.
- model (`nn.Module`): the model not in pipeline style, and will be modified with `ShardFormer`.
- model_policy (`colossalai.shardformer.policies.base_policy.Policy`): the policy to shardformer model.
- micro_batch_size (int): the micro batch size.
- micro_batch_buffer_size (int): the buffer size for micro batch. Normally, it should be the same as the number of pipeline stages.
- new_length (int): the new length of the input sequence.
- early_stopping (bool): whether to stop early.
-
- Example:
-
- ```python
- from colossalai.ppinference import PPInferEngine
- from transformers import GPT2LMHeadModel, GPT2Tokenizer
-
- model = transformers.GPT2LMHeadModel.from_pretrained('gpt2')
- # assume the model is infered with 4 pipeline stages
- inferengine = PPInferEngine(pp_size=4, model=model, model_policy={Your own policy for pipeline sharding})
-
- input = ["Hello, my dog is cute, and I like"]
- tokenized_input = tokenizer(input, return_tensors='pt')
- output = engine.inference([tokenized_input])
- ```
-
- """
-
- def __init__(
- self,
- pp_size: int,
- dtype: str = "fp16",
- pp_model: nn.Module = None,
- model: nn.Module = None,
- model_policy: Policy = None,
- new_length: int = 32,
- micro_batch_size: int = 1,
- micro_batch_buffer_size: int = None,
- verbose: bool = False,
- # TODO: implement early_stopping, and various gerneration options
- early_stopping: bool = False,
- do_sample: bool = False,
- num_beams: int = 1,
- ) -> None:
- assert pp_model or (model and model_policy), "Either pp_model or model with model_policy should be provided."
- self.pp_size = pp_size
- self.pg_mesh = ProcessGroupMesh(pp_size)
- self.stage_manager = PipelineStageManager(self.pg_mesh, 0, True)
- self.mb_manager = MicroBatchManager(
- self.stage_manager.stage, new_length, micro_batch_size, micro_batch_buffer_size or pp_size
- )
- self.verbose = verbose
- self.schedule = GenerateSchedule(self.stage_manager, self.mb_manager, verbose)
-
- assert dtype in ["fp16", "fp32", "bf16"], "dtype should be one of 'fp16', 'fp32', 'bf16'"
- if dtype == "fp16":
- model.half()
- elif dtype == "bf16":
- model.to(torch.bfloat16)
- self.model = pp_model or self._shardformer(model, model_policy)
-
- def inference(self, input_list):
- out, timestamp = self.schedule.generate_step(self.model, iter(input_list))
- if self.verbose:
- return out, timestamp
- else:
- return out
-
- def _shardformer(self, model, model_policy):
- shardconfig = ShardConfig(
- tensor_parallel_process_group=None,
- pipeline_stage_manager=self.stage_manager,
- enable_tensor_parallelism=False,
- enable_fused_normalization=False,
- enable_all_optimization=False,
- enable_flash_attention=False,
- enable_jit_fused=False,
- enable_sequence_parallelism=False,
- )
- shardformer = ShardFormer(shard_config=shardconfig)
- shard_model, _ = shardformer.optimize(model, model_policy)
- return shard_model.cuda()
diff --git a/colossalai/inference/pipeline/modeling/gpt2.py b/colossalai/inference/pipeline/modeling/gpt2.py
deleted file mode 100644
index d2bfcb8b6842..000000000000
--- a/colossalai/inference/pipeline/modeling/gpt2.py
+++ /dev/null
@@ -1,280 +0,0 @@
-from typing import Dict, List, Optional, Tuple, Union
-
-import torch
-from transformers.modeling_outputs import BaseModelOutputWithPastAndCrossAttentions, CausalLMOutputWithCrossAttentions
-from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel, GPT2Model
-from transformers.utils import logging
-
-from colossalai.pipeline.stage_manager import PipelineStageManager
-
-
-class GPT2PipelineForwards:
- """
- This class serves as a micro library for forward function substitution of GPT2 models
- under pipeline setting.
- """
-
- @staticmethod
- def gpt2_model_forward(
- self: GPT2Model,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- token_type_ids: Optional[torch.LongTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- encoder_hidden_states: Optional[torch.Tensor] = None,
- encoder_attention_mask: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- ) -> Union[Dict, Tuple, BaseModelOutputWithPastAndCrossAttentions]:
- # This function is modified on the basis of transformers.models.gpt2.modeling_gpt2.GPT2Model.forward.
- # Please refer to original code of transformers for more details.
- logger = logging.get_logger(__name__)
-
- # Preprocess passed in arguments
- if output_attentions:
- logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
- output_attentions = False
- if output_hidden_states:
- logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
- output_hidden_states = False
-
- use_cache = use_cache if use_cache is not None else self.config.use_cache
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- if past_key_values is None:
- past_length = 0
- past_key_values = tuple([None] * len(self.h))
- else:
- past_length = past_key_values[0][0].size(-2)
-
- if stage_manager.is_first_stage():
- if input_ids is not None and inputs_embeds is not None:
- raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
- elif input_ids is not None:
- input_shape = input_ids.size()
- input_ids = input_ids.view(-1, input_shape[-1])
- batch_size = input_ids.shape[0]
- elif inputs_embeds is not None:
- input_shape = inputs_embeds.size()[:-1]
- batch_size = inputs_embeds.shape[0]
- else:
- raise ValueError("You have to specify either input_ids or inputs_embeds")
-
- device = input_ids.device if input_ids is not None else inputs_embeds.device
- if token_type_ids is not None:
- token_type_ids = token_type_ids.view(-1, input_shape[-1])
- else:
- if hidden_states is None:
- raise ValueError("hidden_states shouldn't be None for stages other than the first stage.")
- input_shape = hidden_states.size()[:-1]
- batch_size, seq_length = input_shape[0], input_shape[1]
- device = hidden_states.device
-
- # GPT2Attention mask.
- if attention_mask is not None:
- if batch_size <= 0:
- raise ValueError("batch_size has to be defined and > 0")
- attention_mask = attention_mask.view(batch_size, -1)
- # We create a 3D attention mask from a 2D tensor mask.
- # Sizes are [batch_size, 1, 1, to_seq_length]
- # So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
- # this attention mask is more simple than the triangular masking of causal attention
- # used in OpenAI GPT, we just need to prepare the broadcast dimension here.
- attention_mask = attention_mask[:, None, None, :]
-
- # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
- # masked positions, this operation will create a tensor which is 0.0 for
- # positions we want to attend and the dtype's smallest value for masked positions.
- # Since we are adding it to the raw scores before the softmax, this is
- # effectively the same as removing these entirely.
- attention_mask = attention_mask.to(dtype=self.dtype) # fp16 compatibility
- attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min
-
- # If a 2D or 3D attention mask is provided for the cross-attention
- # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
- if self.config.add_cross_attention and encoder_hidden_states is not None:
- encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
- encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
- if encoder_attention_mask is None:
- encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
- encoder_attention_mask = self.invert_attention_mask(encoder_attention_mask)
- else:
- encoder_attention_mask = None
-
- # Prepare head mask if needed
- # 1.0 in head_mask indicate we keep the head
- # attention_probs has shape bsz x n_heads x N x N
- # head_mask has shape n_layer x batch x n_heads x N x N
- head_mask = self.get_head_mask(head_mask, self.config.n_layer)
-
- if stage_manager.is_first_stage():
- if position_ids is not None:
- position_ids = position_ids.view(-1, input_shape[-1])
- else:
- position_ids = torch.arange(past_length, input_shape[-1] + past_length, dtype=torch.long, device=device)
- position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
-
- if inputs_embeds is None:
- inputs_embeds = self.wte(input_ids)
- position_embeds = self.wpe(position_ids)
- hidden_states = inputs_embeds + position_embeds
- if token_type_ids is not None:
- token_type_embeds = self.wte(token_type_ids)
- hidden_states = hidden_states + token_type_embeds
- hidden_states = self.drop(hidden_states)
-
- output_shape = input_shape + (hidden_states.size(-1),)
-
- if self.gradient_checkpointing and self.training:
- if use_cache:
- logger.warning_once(
- "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
- )
- use_cache = False
-
- presents = () if use_cache else None
- all_self_attentions = () if output_attentions else None
- all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
- all_hidden_states = () if output_hidden_states else None
-
- # Going through held blocks.
- start_idx, end_idx = stage_index[0], stage_index[1]
- for i, layer_past in zip(range(start_idx, end_idx), past_key_values):
- block = self.h[i]
- # Model parallel
- if self.model_parallel:
- torch.cuda.set_device(hidden_states.device)
- # Ensure layer_past is on same device as hidden_states (might not be correct)
- if layer_past is not None:
- layer_past = tuple(past_state.to(hidden_states.device) for past_state in layer_past)
- # Ensure that attention_mask is always on the same device as hidden_states
- if attention_mask is not None:
- attention_mask = attention_mask.to(hidden_states.device)
- if isinstance(head_mask, torch.Tensor):
- head_mask = head_mask.to(hidden_states.device)
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- if self.gradient_checkpointing and self.training:
-
- def create_custom_forward(module):
- def custom_forward(*inputs):
- # None for past_key_value
- return module(*inputs, use_cache, output_attentions)
-
- return custom_forward
-
- outputs = torch.utils.checkpoint.checkpoint(
- create_custom_forward(block),
- hidden_states,
- None,
- attention_mask,
- head_mask[i],
- encoder_hidden_states,
- encoder_attention_mask,
- )
- else:
- outputs = block(
- hidden_states,
- layer_past=layer_past,
- attention_mask=attention_mask,
- head_mask=head_mask[i],
- encoder_hidden_states=encoder_hidden_states,
- encoder_attention_mask=encoder_attention_mask,
- use_cache=use_cache,
- output_attentions=output_attentions,
- )
-
- hidden_states = outputs[0]
- if use_cache is True:
- presents = presents + (outputs[1],)
-
- if output_attentions:
- all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
- if self.config.add_cross_attention:
- all_cross_attentions = all_cross_attentions + (outputs[3 if use_cache else 2],)
-
- # Model Parallel: If it's the last layer for that device, put things on the next device
- if self.model_parallel:
- for k, v in self.device_map.items():
- if i == v[-1] and "cuda:" + str(k) != self.last_device:
- hidden_states = hidden_states.to("cuda:" + str(k + 1))
-
- if stage_manager.is_last_stage():
- hidden_states = self.ln_f(hidden_states)
-
- hidden_states = hidden_states.view(output_shape)
-
- # Add last hidden state
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- return {"hidden_states": hidden_states, "past_key_values": presents}
-
- @staticmethod
- def gpt2_lmhead_model_forward(
- self: GPT2LMHeadModel,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- token_type_ids: Optional[torch.LongTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- encoder_hidden_states: Optional[torch.Tensor] = None,
- encoder_attention_mask: Optional[torch.FloatTensor] = None,
- labels: Optional[torch.LongTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- ) -> Union[Dict, Tuple, CausalLMOutputWithCrossAttentions]:
- r"""
- labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
- Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
- `labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
- are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
-
- This function is modified on the basis of transformers.models.gpt2.modeling_gpt2.GPT2LMHeadModel.forward.
- Please refer to original code of transformers for more details.
- """
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- # If is first stage and after warmup, go throught lm_head first
- if stage_manager.is_first_stage() and hidden_states is not None:
- lm_logits = self.lm_head(hidden_states)
- return {"logits": lm_logits}
-
- # Not first stage or before warmup, go through gpt2 model
- outputs = GPT2PipelineForwards.gpt2_model_forward(
- self.transformer,
- input_ids,
- past_key_values=past_key_values,
- attention_mask=attention_mask,
- token_type_ids=token_type_ids,
- position_ids=position_ids,
- head_mask=head_mask,
- inputs_embeds=inputs_embeds,
- encoder_hidden_states=encoder_hidden_states,
- encoder_attention_mask=encoder_attention_mask,
- use_cache=use_cache,
- output_attentions=output_attentions,
- output_hidden_states=output_hidden_states,
- return_dict=return_dict,
- stage_manager=stage_manager,
- hidden_states=hidden_states,
- stage_index=stage_index,
- )
-
- return outputs
diff --git a/colossalai/inference/pipeline/modeling/llama.py b/colossalai/inference/pipeline/modeling/llama.py
deleted file mode 100644
index f46e1fbdd7b3..000000000000
--- a/colossalai/inference/pipeline/modeling/llama.py
+++ /dev/null
@@ -1,229 +0,0 @@
-from typing import List, Optional
-
-import torch
-from transformers.models.llama.modeling_llama import LlamaForCausalLM, LlamaModel
-from transformers.utils import logging
-
-from colossalai.pipeline.stage_manager import PipelineStageManager
-
-
-class LlamaPipelineForwards:
- """
- This class serves as a micro library for forward function substitution of Llama models
- under pipeline setting.
- """
-
- def llama_model_forward(
- self: LlamaModel,
- input_ids: torch.LongTensor = None,
- attention_mask: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[List[torch.FloatTensor]] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- ):
- logger = logging.get_logger(__name__)
-
- # Preprocess passed in arguments
- if output_attentions:
- logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
- output_attentions = False
- if output_hidden_states:
- logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
- output_hidden_states = False
-
- use_cache = use_cache if use_cache is not None else self.config.use_cache
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- # retrieve input_ids and inputs_embeds
- if stage_manager.is_first_stage():
- if input_ids is not None and inputs_embeds is not None:
- raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
- elif input_ids is not None:
- batch_size, seq_length = input_ids.shape
- elif inputs_embeds is not None:
- batch_size, seq_length, _ = inputs_embeds.shape
- else:
- raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
- device = input_ids.device if input_ids is not None else inputs_embeds.device
- if inputs_embeds is None:
- inputs_embeds = self.embed_tokens(input_ids)
- hidden_states = inputs_embeds
- else:
- input_shape = hidden_states.shape[:-1]
- batch_size, seq_length = input_shape
- device = hidden_states.device
-
- seq_length_with_past = seq_length
- past_key_values_length = 0
-
- if past_key_values is not None:
- past_key_values_length = past_key_values[0][0].shape[2]
- seq_length_with_past = seq_length_with_past + past_key_values_length
-
- if position_ids is None:
- position_ids = torch.arange(
- past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
- )
- position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
- else:
- position_ids = position_ids.view(-1, seq_length).long()
-
- # embed positions, for the first stage, hidden_states is the input embeddings,
- # for the other stages, hidden_states is the output of the previous stage
- if attention_mask is None:
- attention_mask = torch.ones(
- (batch_size, seq_length_with_past), dtype=torch.bool, device=hidden_states.device
- )
- attention_mask = self._prepare_decoder_attention_mask(
- attention_mask, (batch_size, seq_length), hidden_states, past_key_values_length
- )
-
- if self.gradient_checkpointing and self.training:
- if use_cache:
- logger.warning_once(
- "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
- )
- use_cache = False
-
- # decoder layers
- all_hidden_states = () if output_hidden_states else None
- all_self_attns = () if output_attentions else None
- next_decoder_cache = () if use_cache else None
-
- start_idx, end_idx = stage_index[0], stage_index[1]
- if past_key_values is None:
- past_key_values = tuple([None] * (end_idx - start_idx + 1))
-
- for idx, past_key_value in zip(range(start_idx, end_idx), past_key_values):
- decoder_layer = self.layers[idx]
- if output_hidden_states:
- all_hidden_states += (hidden_states,)
-
- # past_key_value = past_key_values[idx] if past_key_values is not None else None
-
- if self.gradient_checkpointing and self.training:
-
- def create_custom_forward(module):
- def custom_forward(*inputs):
- # None for past_key_value
- return module(*inputs, output_attentions, None)
-
- return custom_forward
-
- layer_outputs = torch.utils.checkpoint.checkpoint(
- create_custom_forward(decoder_layer),
- hidden_states,
- attention_mask,
- position_ids,
- None,
- )
- else:
- layer_outputs = decoder_layer(
- hidden_states,
- attention_mask=attention_mask,
- position_ids=position_ids,
- past_key_value=past_key_value,
- output_attentions=output_attentions,
- use_cache=use_cache,
- )
-
- hidden_states = layer_outputs[0]
-
- if use_cache:
- next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
- if output_attentions:
- all_self_attns += (layer_outputs[1],)
-
- if stage_manager.is_last_stage():
- hidden_states = self.norm(hidden_states)
-
- # add hidden states from the last decoder layer
- if output_hidden_states:
- all_hidden_states += (hidden_states,)
- next_cache = next_decoder_cache if use_cache else None
-
- # always return dict for imediate stage
- return {"hidden_states": hidden_states, "past_key_values": next_cache}
-
- def llama_for_causal_lm_forward(
- self: LlamaForCausalLM,
- input_ids: torch.LongTensor = None,
- attention_mask: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[List[torch.FloatTensor]] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- labels: Optional[torch.LongTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- ):
- r"""
- Args:
- labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
- Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
- config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
- (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
-
- Returns:
-
- Example:
-
- ```python
- >>> from transformers import AutoTokenizer, LlamaForCausalLM
-
- >>> model = LlamaForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
- >>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
-
- >>> prompt = "Hey, are you consciours? Can you talk to me?"
- >>> inputs = tokenizer(prompt, return_tensors="pt")
-
- >>> # Generate
- >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
- >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
- "Hey, are you consciours? Can you talk to me?\nI'm not consciours, but I can talk to you."
- ```"""
- logger = logging.get_logger(__name__)
-
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- if output_attentions:
- logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
- output_attentions = False
- if output_hidden_states:
- logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
- output_hidden_states = False
-
- # If is first stage and after warmup, go throught lm_head first
- if stage_manager.is_first_stage() and hidden_states is not None:
- lm_logits = self.lm_head(hidden_states)
- return {"logits": lm_logits}
-
- # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
- outputs = LlamaPipelineForwards.llama_model_forward(
- self.model,
- input_ids=input_ids,
- attention_mask=attention_mask,
- position_ids=position_ids,
- past_key_values=past_key_values,
- inputs_embeds=inputs_embeds,
- use_cache=use_cache,
- output_attentions=output_attentions,
- output_hidden_states=output_hidden_states,
- return_dict=return_dict,
- stage_manager=stage_manager,
- hidden_states=hidden_states,
- stage_index=stage_index,
- )
-
- return outputs
diff --git a/colossalai/inference/pipeline/policy/gpt2_ppinfer.py b/colossalai/inference/pipeline/policy/gpt2_ppinfer.py
deleted file mode 100644
index 51e6425b113e..000000000000
--- a/colossalai/inference/pipeline/policy/gpt2_ppinfer.py
+++ /dev/null
@@ -1,74 +0,0 @@
-from functools import partial
-from typing import Callable, Dict, List
-
-from torch import Tensor, nn
-
-import colossalai.shardformer.layer as col_nn
-from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
-from colossalai.shardformer.policies.gpt2 import GPT2Policy
-
-from ..modeling.gpt2 import GPT2PipelineForwards
-
-
-class GPT2LMHeadModelPipelinePolicy(GPT2Policy):
- def __init__(self) -> None:
- super().__init__()
-
- def module_policy(self):
- from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
-
- module_policy = super().module_policy()
-
- if self.shard_config.enable_tensor_parallelism:
- addon_module = {
- GPT2LMHeadModel: ModulePolicyDescription(
- sub_module_replacement=[
- SubModuleReplacementDescription(
- suffix="lm_head", target_module=col_nn.Linear1D_Col, kwargs={"gather_output": True}
- )
- ]
- )
- }
- module_policy.update(addon_module)
-
- if self.pipeline_stage_manager is not None:
- self.set_pipeline_forward(
- model_cls=GPT2LMHeadModel,
- new_forward=GPT2PipelineForwards.gpt2_lmhead_model_forward,
- policy=module_policy,
- )
- return module_policy
-
- def get_held_layers(self) -> List[nn.Module]:
- held_layers = super().get_held_layers()
- # make the tie weight lm_head and embedding in the same device to save memory
- # if self.pipeline_stage_manager.is_first_stage():
- if self.pipeline_stage_manager.is_first_stage():
- held_layers.append(self.model.lm_head)
- return held_layers
-
- def get_shared_params(self) -> List[Dict[int, Tensor]]:
- """The weights of wte and lm_head are shared."""
- module = self.model
- stage_manager = self.pipeline_stage_manager
- if stage_manager is not None:
- if stage_manager.num_stages > 1 and id(module.transformer.wte.weight) == id(module.lm_head.weight):
- first_stage, last_stage = 0, stage_manager.num_stages - 1
- return [{first_stage: module.transformer.wte.weight, last_stage: module.lm_head.weight}]
- return []
-
- def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, policy: Dict) -> None:
- """If under pipeline parallel setting, replacing the original forward method of huggingface
- to customized forward method, and add this changing to policy."""
- if not self.pipeline_stage_manager:
- raise ValueError("set_pipeline_forward method can only be called when pipeline parallel is enabled.")
- stage_manager = self.pipeline_stage_manager
- if self.model.__class__.__name__ == "GPT2Model":
- module = self.model
- else:
- module = self.model.transformer
-
- layers_per_stage = Policy.distribute_layers(len(module.h), stage_manager.num_stages)
- stage_index = Policy.get_stage_index(layers_per_stage, stage_manager.stage)
- method_replacement = {"forward": partial(new_forward, stage_manager=stage_manager, stage_index=stage_index)}
- self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=model_cls)
diff --git a/colossalai/inference/pipeline/policy/llama_ppinfer.py b/colossalai/inference/pipeline/policy/llama_ppinfer.py
deleted file mode 100644
index 6e12ed61bf7b..000000000000
--- a/colossalai/inference/pipeline/policy/llama_ppinfer.py
+++ /dev/null
@@ -1,48 +0,0 @@
-from typing import List
-
-from torch.nn import Module
-
-from colossalai.shardformer.layer import Linear1D_Col
-from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
-from colossalai.shardformer.policies.llama import LlamaPolicy
-
-from ..modeling.llama import LlamaPipelineForwards
-
-
-class LlamaForCausalLMPipelinePolicy(LlamaPolicy):
- def __init__(self) -> None:
- super().__init__()
-
- def module_policy(self):
- from transformers import LlamaForCausalLM
-
- policy = super().module_policy()
-
- if self.shard_config.enable_tensor_parallelism:
- # add a new item for casual lm
- new_item = {
- LlamaForCausalLM: ModulePolicyDescription(
- sub_module_replacement=[
- SubModuleReplacementDescription(
- suffix="lm_head", target_module=Linear1D_Col, kwargs=dict(gather_output=True)
- )
- ]
- )
- }
- policy.update(new_item)
-
- if self.pipeline_stage_manager:
- # set None as default
- self.set_pipeline_forward(
- model_cls=LlamaForCausalLM, new_forward=LlamaPipelineForwards.llama_for_causal_lm_forward, policy=policy
- )
-
- return policy
-
- def get_held_layers(self) -> List[Module]:
- """Get pipeline layers for current stage."""
- stage_manager = self.pipeline_stage_manager
- held_layers = super().get_held_layers()
- if stage_manager.is_first_stage():
- held_layers.append(self.model.lm_head)
- return held_layers
diff --git a/colossalai/inference/pipeline/utils.py b/colossalai/inference/pipeline/utils.py
deleted file mode 100644
index c26aa4e40b71..000000000000
--- a/colossalai/inference/pipeline/utils.py
+++ /dev/null
@@ -1,35 +0,0 @@
-from typing import Set
-
-import torch.nn as nn
-
-from colossalai.shardformer._utils import getattr_, setattr_
-
-
-def set_tensors_to_none(model: nn.Module, include: Set[str] = set()) -> None:
- """
- Set all parameters and buffers of model to None
-
- Args:
- model (nn.Module): The model to set
- """
- for module_suffix in include:
- set_module = getattr_(model, module_suffix)
- for n, p in set_module.named_parameters():
- setattr_(set_module, n, None)
- for n, buf in set_module.named_buffers():
- setattr_(set_module, n, None)
- setattr_(model, module_suffix, None)
-
-
-def get_suffix_name(suffix: str, name: str):
- """
- Get the suffix name of the module, as `suffix.name` when name is string or `suffix[name]` when name is a digit,
- and 'name' when `suffix` is empty.
-
- Args:
- suffix (str): The suffix of the suffix module
- name (str): The name of the current module
- """
- point = "" if suffix is "" else "."
- suffix_name = suffix + f"[{name}]" if name.isdigit() else suffix + f"{point}{name}"
- return suffix_name
diff --git a/colossalai/inference/quant/__init__.py b/colossalai/inference/quant/__init__.py
new file mode 100644
index 000000000000..18e0de9cc9fc
--- /dev/null
+++ b/colossalai/inference/quant/__init__.py
@@ -0,0 +1 @@
+from .smoothquant.models.llama import SmoothLlamaForCausalLM
diff --git a/colossalai/inference/quant/gptq/__init__.py b/colossalai/inference/quant/gptq/__init__.py
index c035f397923a..4cf1fd658a41 100644
--- a/colossalai/inference/quant/gptq/__init__.py
+++ b/colossalai/inference/quant/gptq/__init__.py
@@ -2,3 +2,4 @@
if HAS_AUTO_GPTQ:
from .cai_gptq import CaiGPTQLinearOp, CaiQuantLinear
+ from .gptq_manager import GPTQManager
diff --git a/colossalai/inference/quant/gptq/gptq_manager.py b/colossalai/inference/quant/gptq/gptq_manager.py
new file mode 100644
index 000000000000..2d352fbef2b9
--- /dev/null
+++ b/colossalai/inference/quant/gptq/gptq_manager.py
@@ -0,0 +1,61 @@
+import torch
+
+
+class GPTQManager:
+ def __init__(self, quant_config, max_input_len: int = 1):
+ self.max_dq_buffer_size = 1
+ self.max_inner_outer_dim = 1
+ self.bits = quant_config.bits
+ self.use_act_order = quant_config.desc_act
+ self.max_input_len = 1
+ self.gptq_temp_state_buffer = None
+ self.gptq_temp_dq_buffer = None
+ self.quant_config = quant_config
+
+ def post_init_gptq_buffer(self, model: torch.nn.Module) -> None:
+ from .cai_gptq import CaiQuantLinear
+
+ HAS_GPTQ_CUDA = False
+ try:
+ from colossalai.kernel.op_builder.gptq import GPTQBuilder
+
+ gptq_cuda = GPTQBuilder().load()
+ HAS_GPTQ_CUDA = True
+ except ImportError:
+ warnings.warn("CUDA gptq is not installed")
+ HAS_GPTQ_CUDA = False
+
+ for name, submodule in model.named_modules():
+ if isinstance(submodule, CaiQuantLinear):
+ self.max_dq_buffer_size = max(self.max_dq_buffer_size, submodule.qweight.numel() * 8)
+
+ if self.use_act_order:
+ self.max_inner_outer_dim = max(
+ self.max_inner_outer_dim, submodule.infeatures, submodule.outfeatures
+ )
+ self.bits = submodule.bits
+ if not (HAS_GPTQ_CUDA and self.bits == 4):
+ return
+
+ max_input_len = 1
+ if self.use_act_order:
+ max_input_len = self.max_input_len
+ # The temp_state buffer is required to reorder X in the act-order case.
+ # The temp_dq buffer is required to dequantize weights when using cuBLAS, typically for the prefill.
+ self.gptq_temp_state_buffer = torch.zeros(
+ (max_input_len, self.max_inner_outer_dim), dtype=torch.float16, device=torch.cuda.current_device()
+ )
+ self.gptq_temp_dq_buffer = torch.zeros(
+ (1, self.max_dq_buffer_size), dtype=torch.float16, device=torch.cuda.current_device()
+ )
+
+ gptq_cuda.prepare_buffers(
+ torch.device(torch.cuda.current_device()), self.gptq_temp_state_buffer, self.gptq_temp_dq_buffer
+ )
+ # Using the default from exllama repo here.
+ matmul_recons_thd = 8
+ matmul_fused_remap = False
+ matmul_no_half2 = False
+ gptq_cuda.set_tuning_params(matmul_recons_thd, matmul_fused_remap, matmul_no_half2)
+
+ torch.cuda.empty_cache()
diff --git a/colossalai/inference/quant/smoothquant/models/__init__.py b/colossalai/inference/quant/smoothquant/models/__init__.py
index 77541d8610c5..1663028da138 100644
--- a/colossalai/inference/quant/smoothquant/models/__init__.py
+++ b/colossalai/inference/quant/smoothquant/models/__init__.py
@@ -4,9 +4,7 @@
HAS_TORCH_INT = True
except ImportError:
HAS_TORCH_INT = False
- raise ImportError(
- "Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int"
- )
+ print("Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int")
if HAS_TORCH_INT:
from .llama import LLamaSmoothquantAttention, LlamaSmoothquantMLP
diff --git a/colossalai/inference/quant/smoothquant/models/base_model.py b/colossalai/inference/quant/smoothquant/models/base_model.py
index 6a1d96ecec8f..f3afe5d83bb0 100644
--- a/colossalai/inference/quant/smoothquant/models/base_model.py
+++ b/colossalai/inference/quant/smoothquant/models/base_model.py
@@ -9,7 +9,6 @@
from os.path import isdir, isfile, join
from typing import Dict, List, Optional, Union
-import accelerate
import numpy as np
import torch
import torch.nn as nn
@@ -21,8 +20,16 @@
from transformers.utils.generic import ContextManagers
from transformers.utils.hub import PushToHubMixin, cached_file
-from colossalai.inference.tensor_parallel.batch_infer_state import BatchInferState
-from colossalai.inference.tensor_parallel.kvcache_manager import MemoryManager
+from colossalai.inference.kv_cache.batch_infer_state import BatchInferState, MemoryManager
+
+try:
+ import accelerate
+
+ HAS_ACCELERATE = True
+except ImportError:
+ HAS_ACCELERATE = False
+ print("accelerate is not installed.")
+
SUPPORTED_MODELS = ["llama"]
@@ -87,7 +94,6 @@ def init_batch_state(self, max_output_len=256, **kwargs):
batch_infer_state.start_loc = seq_start_indexes.to("cuda")
batch_infer_state.block_loc = block_loc
batch_infer_state.decode_layer_id = 0
- batch_infer_state.past_key_values_len = 0
batch_infer_state.is_context_stage = True
batch_infer_state.set_cache_manager(self.cache_manager)
batch_infer_state.cache_manager.free_all()
diff --git a/colossalai/inference/quant/smoothquant/models/linear.py b/colossalai/inference/quant/smoothquant/models/linear.py
index 969c390a0849..03d994b32489 100644
--- a/colossalai/inference/quant/smoothquant/models/linear.py
+++ b/colossalai/inference/quant/smoothquant/models/linear.py
@@ -1,17 +1,25 @@
# modified from torch-int: https://github.com/Guangxuan-Xiao/torch-int/blob/main/torch_int/nn/linear.py
import torch
-from torch_int._CUDA import linear_a8_w8_b8_o8, linear_a8_w8_bfp32_ofp32
-from torch_int.functional.quantization import quantize_per_tensor_absmax
+
+try:
+ from torch_int._CUDA import linear_a8_w8_b8_o8, linear_a8_w8_bfp32_ofp32
+ from torch_int.functional.quantization import quantize_per_tensor_absmax
+
+ HAS_TORCH_INT = True
+except ImportError:
+ HAS_TORCH_INT = False
+ print("Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int")
+
try:
from colossalai.kernel.op_builder.smoothquant import SmoothquantBuilder
smoothquant_cuda = SmoothquantBuilder().load()
HAS_SMOOTHQUANT_CUDA = True
-except ImportError:
+except:
HAS_SMOOTHQUANT_CUDA = False
- raise ImportError("CUDA smoothquant linear is not installed")
+ print("CUDA smoothquant linear is not installed")
class W8A8BFP32O32LinearSiLU(torch.nn.Module):
@@ -138,21 +146,23 @@ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
)
self.register_buffer(
"bias",
- torch.zeros(self.out_features, dtype=torch.float32, requires_grad=False),
+ torch.zeros((1, self.out_features), dtype=torch.float32, requires_grad=False),
)
self.register_buffer("a", torch.tensor(alpha))
def _apply(self, fn):
# prevent the bias from being converted to half
super()._apply(fn)
- self.bias = self.bias.to(torch.float32)
+ if self.bias is not None:
+ self.bias = self.bias.to(torch.float32)
return self
def to(self, *args, **kwargs):
super().to(*args, **kwargs)
self.weight = self.weight.to(*args, **kwargs)
- self.bias = self.bias.to(*args, **kwargs)
- self.bias = self.bias.to(torch.float32)
+ if self.bias is not None:
+ self.bias = self.bias.to(*args, **kwargs)
+ self.bias = self.bias.to(torch.float32)
return self
@torch.no_grad()
diff --git a/colossalai/inference/quant/smoothquant/models/llama.py b/colossalai/inference/quant/smoothquant/models/llama.py
index 4c3d6dcc0b23..bb74dc49d7af 100644
--- a/colossalai/inference/quant/smoothquant/models/llama.py
+++ b/colossalai/inference/quant/smoothquant/models/llama.py
@@ -8,7 +8,6 @@
import torch
import torch.nn as nn
import torch.nn.functional as F
-from torch_int.nn.bmm import BMM_S8T_S8N_F32T, BMM_S8T_S8N_S8T
from transformers import PreTrainedModel
from transformers.modeling_outputs import BaseModelOutputWithPast
from transformers.models.llama.configuration_llama import LlamaConfig
@@ -18,12 +17,11 @@
LlamaDecoderLayer,
LlamaMLP,
LlamaRotaryEmbedding,
- repeat_kv,
rotate_half,
)
from transformers.utils import add_start_docstrings_to_model_forward
-from colossalai.inference.tensor_parallel.batch_infer_state import BatchInferState
+from colossalai.inference.kv_cache.batch_infer_state import BatchInferState
from colossalai.kernel.triton import (
copy_kv_cache_to_dest,
int8_rotary_embedding_fwd,
@@ -31,10 +29,31 @@
smooth_token_attention_fwd,
)
+try:
+ from torch_int.nn.bmm import BMM_S8T_S8N_F32T, BMM_S8T_S8N_S8T
+
+ HAS_TORCH_INT = True
+except ImportError:
+ HAS_TORCH_INT = False
+ print("Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int")
+
+
from .base_model import BaseSmoothForCausalLM
from .linear import W8A8B8O8Linear, W8A8BFP32O32LinearSiLU, W8A8BFP32OFP32Linear
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """
+ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
+ num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
+
+
class LLamaSmoothquantAttention(nn.Module):
def __init__(
self,
@@ -116,7 +135,6 @@ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
def forward(
self,
hidden_states: torch.Tensor,
- rotary_emb: Tuple[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
@@ -131,8 +149,7 @@ def forward(
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
- cos = rotary_emb[0]
- sin = rotary_emb[1]
+ cos, sin = infer_state.position_cos, infer_state.position_sin
int8_rotary_embedding_fwd(
query_states.view(-1, self.num_heads, self.head_dim),
@@ -149,12 +166,6 @@ def forward(
self.k_rotary_output_scale.item(),
)
- # NOTE might want to revise
- # need some way to record the length of past key values cache
- # since we won't return past_key_value_cache right now
- if infer_state.decode_layer_id == 0: # once per model.forward
- infer_state.cache_manager.past_key_values_length += q_len # seq_len
-
def _copy_kv_to_mem_cache(layer_id, key_buffer, value_buffer, context_mem_index, mem_manager):
copy_kv_cache_to_dest(key_buffer, context_mem_index, mem_manager.key_buffer[layer_id])
copy_kv_cache_to_dest(value_buffer, context_mem_index, mem_manager.value_buffer[layer_id])
@@ -229,7 +240,7 @@ def _copy_kv_to_mem_cache(layer_id, key_buffer, value_buffer, context_mem_index,
infer_state.block_loc,
infer_state.start_loc,
infer_state.seq_len,
- infer_state.cache_manager.past_key_values_length,
+ infer_state.max_len_in_batch,
)
attn_output = attn_output.view(bsz, q_len, self.num_heads * self.head_dim)
@@ -354,7 +365,6 @@ def pack(
def forward(
self,
hidden_states: torch.Tensor,
- rotary_emb: Tuple[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
@@ -384,7 +394,6 @@ def forward(
# Self Attention
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
- rotary_emb=rotary_emb,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
@@ -592,17 +601,13 @@ def llama_model_forward(
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
- seq_length_with_past = seq_length
- past_key_values_length = 0
-
infer_state = self.infer_state
+ if infer_state.is_context_stage:
+ past_key_values_length = 0
+ else:
+ past_key_values_length = infer_state.max_len_in_batch - 1
- if past_key_values is not None:
- # NOT READY FOR PRIME TIME
- # dummy but work, revise it
- past_key_values_length = infer_state.cache_manager.past_key_values_length
- # past_key_values_length = past_key_values[0][0].shape[2]
- seq_length_with_past = seq_length_with_past + past_key_values_length
+ seq_length_with_past = seq_length + past_key_values_length
# NOTE: differentiate with prefill stage
# block_loc require different value-assigning method for two different stage
@@ -623,9 +628,7 @@ def llama_model_forward(
infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
else:
print(f" *** Encountered allocation non-contiguous")
- print(
- f" infer_state.cache_manager.past_key_values_length: {infer_state.cache_manager.past_key_values_length}"
- )
+ print(f" infer_state.cache_manager.max_len_in_batch: {infer_state.max_len_in_batch}")
infer_state.decode_is_contiguous = False
alloc_mem = infer_state.cache_manager.alloc(batch_size)
infer_state.decode_mem_index = alloc_mem
@@ -662,15 +665,15 @@ def llama_model_forward(
raise NotImplementedError("not implement gradient_checkpointing and training options ")
if past_key_values_length == 0:
- position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
position_ids.view(-1).shape[0], -1
)
- position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
position_ids.view(-1).shape[0], -1
)
else:
- position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(batch_size, -1)
- position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(batch_size, -1)
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(batch_size, -1)
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(batch_size, -1)
# decoder layers
all_hidden_states = () if output_hidden_states else None
@@ -685,7 +688,6 @@ def llama_model_forward(
layer_outputs = decoder_layer(
hidden_states,
- rotary_emb=(position_cos, position_sin),
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
@@ -713,6 +715,7 @@ def llama_model_forward(
infer_state.is_context_stage = False
infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
infer_state.seq_len += 1
+ infer_state.max_len_in_batch += 1
next_cache = next_decoder_cache if use_cache else None
if not return_dict:
diff --git a/colossalai/inference/quant/smoothquant/models/parallel_linear.py b/colossalai/inference/quant/smoothquant/models/parallel_linear.py
new file mode 100644
index 000000000000..962b687a1d05
--- /dev/null
+++ b/colossalai/inference/quant/smoothquant/models/parallel_linear.py
@@ -0,0 +1,264 @@
+from typing import List, Union
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from torch.distributed import ProcessGroup
+
+from colossalai.lazy import LazyInitContext
+from colossalai.shardformer.layer import ParallelModule
+
+from .linear import W8A8B8O8Linear, W8A8BFP32O32LinearSiLU, W8A8BFP32OFP32Linear
+
+
+def split_row_copy(smooth_linear, para_linear, tp_size=1, tp_rank=0, split_num=1):
+ qweights = smooth_linear.weight.split(smooth_linear.out_features // split_num, dim=0)
+ if smooth_linear.bias is not None:
+ bias = smooth_linear.bias.split(smooth_linear.out_features // split_num, dim=0)
+
+ smooth_split_out_features = para_linear.out_features // split_num
+
+ for i in range(split_num):
+ para_linear.weight[i * smooth_split_out_features : (i + 1) * smooth_split_out_features, :] = qweights[i][
+ tp_rank * smooth_split_out_features : (tp_rank + 1) * smooth_split_out_features, :
+ ]
+
+ if para_linear.bias is not None:
+ para_linear.bias[:, i * smooth_split_out_features : (i + 1) * smooth_split_out_features] = bias[i][
+ :, tp_rank * smooth_split_out_features : (tp_rank + 1) * smooth_split_out_features
+ ]
+
+
+def split_column_copy(smooth_linear, para_linear, tp_rank=0, split_num=1):
+ qweights = smooth_linear.weight.split(smooth_linear.in_features // split_num, dim=-1)
+
+ smooth_split_in_features = para_linear.in_features // split_num
+
+ for i in range(split_num):
+ para_linear.weight[:, i * smooth_split_in_features : (i + 1) * smooth_split_in_features] = qweights[i][
+ :, tp_rank * smooth_split_in_features : (tp_rank + 1) * smooth_split_in_features
+ ]
+
+ if smooth_linear.bias is not None:
+ para_linear.bias.copy_(smooth_linear.bias)
+
+
+class RowW8A8B8O8Linear(W8A8B8O8Linear, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ out_features = module.out_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if out_features < tp_size:
+ return module
+
+ if out_features % tp_size != 0:
+ raise ValueError(
+ f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = RowW8A8B8O8Linear(module.in_features, module.out_features // tp_size)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = module.a.clone().detach()
+ linear_1d.b = module.b.clone().detach()
+ split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ return linear_1d
+
+
+class ColW8A8B8O8Linear(W8A8B8O8Linear, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ in_features = module.in_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if in_features < tp_size:
+ return module
+
+ if in_features % tp_size != 0:
+ raise ValueError(
+ f"The size of in_features:{in_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = ColW8A8B8O8Linear(module.in_features // tp_size, module.out_features)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = torch.tensor(module.a)
+ linear_1d.b = torch.tensor(module.b)
+
+ split_column_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ if linear_1d.bias is not None:
+ linear_1d.bias = linear_1d.bias // tp_size
+
+ return linear_1d
+
+ @torch.no_grad()
+ def forward(self, x):
+ output = super().forward(x)
+ if self.tp_size > 1:
+ dist.all_reduce(output, op=dist.ReduceOp.SUM, group=self.process_group)
+ return output
+
+
+class RowW8A8BFP32O32LinearSiLU(W8A8BFP32O32LinearSiLU, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ out_features = module.out_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if out_features < tp_size:
+ return module
+
+ if out_features % tp_size != 0:
+ raise ValueError(
+ f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = RowW8A8BFP32O32LinearSiLU(module.in_features, module.out_features // tp_size)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = module.a.clone().detach()
+
+ split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ return linear_1d
+
+
+class RowW8A8BFP32OFP32Linear(W8A8BFP32OFP32Linear, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ out_features = module.out_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if out_features < tp_size:
+ return module
+
+ if out_features % tp_size != 0:
+ raise ValueError(
+ f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = RowW8A8BFP32OFP32Linear(module.in_features, module.out_features // tp_size)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = module.a.clone().detach()
+
+ split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ return linear_1d
+
+
+class ColW8A8BFP32OFP32Linear(W8A8BFP32OFP32Linear, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ in_features = module.in_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if in_features < tp_size:
+ return module
+
+ if in_features % tp_size != 0:
+ raise ValueError(
+ f"The size of in_features:{in_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = ColW8A8BFP32OFP32Linear(module.in_features // tp_size, module.out_features)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = module.a.clone().detach()
+
+ split_column_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ if linear_1d.bias is not None:
+ linear_1d.bias = linear_1d.bias / tp_size
+
+ return linear_1d
+
+ @torch.no_grad()
+ def forward(self, x):
+ output = super().forward(x)
+ if self.tp_size > 1:
+ dist.all_reduce(output, op=dist.ReduceOp.SUM, group=self.process_group)
+ return output
diff --git a/colossalai/inference/tensor_parallel/batch_infer_state.py b/colossalai/inference/tensor_parallel/batch_infer_state.py
deleted file mode 100644
index 33e79ec04bcb..000000000000
--- a/colossalai/inference/tensor_parallel/batch_infer_state.py
+++ /dev/null
@@ -1,58 +0,0 @@
-# might want to consider combine with InferenceConfig in colossalai/ppinference/inference_config.py later
-from dataclasses import dataclass
-
-import torch
-
-from .kvcache_manager import MemoryManager
-
-
-# adapted from: lightllm/server/router/model_infer/infer_batch.py
-@dataclass
-class BatchInferState:
- r"""
- Information to be passed and used for a batch of inputs during
- a single model forward
- """
- batch_size: int
- max_len_in_batch: int
-
- cache_manager: MemoryManager = None
-
- block_loc: torch.Tensor = None
- start_loc: torch.Tensor = None
- seq_len: torch.Tensor = None
- past_key_values_len: int = None
-
- is_context_stage: bool = False
- context_mem_index: torch.Tensor = None
- decode_is_contiguous: bool = None
- decode_mem_start: int = None
- decode_mem_end: int = None
- decode_mem_index: torch.Tensor = None
- decode_layer_id: int = None
-
- device: torch.device = torch.device("cuda")
-
- @property
- def total_token_num(self):
- # return self.batch_size * self.max_len_in_batch
- assert self.seq_len is not None and self.seq_len.size(0) > 0
- return int(torch.sum(self.seq_len))
-
- def set_cache_manager(self, manager: MemoryManager):
- self.cache_manager = manager
-
- # adapted from: https://github.com/ModelTC/lightllm/blob/28c1267cfca536b7b4f28e921e03de735b003039/lightllm/common/infer_utils.py#L1
- @staticmethod
- def init_block_loc(
- b_loc: torch.Tensor, seq_len: torch.Tensor, max_len_in_batch: int, alloc_mem_index: torch.Tensor
- ):
- """in-place update block loc mapping based on the sequence length of the inputs in current bath"""
- start_index = 0
- seq_len_numpy = seq_len.cpu().numpy()
- for i, cur_seq_len in enumerate(seq_len_numpy):
- b_loc[i, max_len_in_batch - cur_seq_len : max_len_in_batch] = alloc_mem_index[
- start_index : start_index + cur_seq_len
- ]
- start_index += cur_seq_len
- return
diff --git a/colossalai/initialize.py b/colossalai/initialize.py
index aac57d34a2c1..aaeaad3828f5 100644
--- a/colossalai/initialize.py
+++ b/colossalai/initialize.py
@@ -6,12 +6,12 @@
from pathlib import Path
from typing import Dict, Union
-import torch
import torch.distributed as dist
+from colossalai.accelerator import get_accelerator
from colossalai.context import Config
from colossalai.logging import get_dist_logger
-from colossalai.utils import set_device, set_seed
+from colossalai.utils import set_seed
def launch(
@@ -47,14 +47,18 @@ def launch(
if rank == 0:
warnings.warn("`config` is deprecated and will be removed soon.")
+ cur_accelerator = get_accelerator()
+
+ backend = cur_accelerator.communication_backend
+
# init default process group
init_method = f"tcp://[{host}]:{port}"
dist.init_process_group(rank=rank, world_size=world_size, backend=backend, init_method=init_method)
# set cuda device
- if torch.cuda.is_available():
- # if local rank is not given, calculate automatically
- set_device(local_rank)
+ # if local rank is not given, calculate automatically
+ if cur_accelerator.support_set_device:
+ cur_accelerator.set_device(local_rank)
set_seed(seed)
diff --git a/colossalai/kernel/__init__.py b/colossalai/kernel/__init__.py
index 8933fc0a3c2f..e69de29bb2d1 100644
--- a/colossalai/kernel/__init__.py
+++ b/colossalai/kernel/__init__.py
@@ -1,7 +0,0 @@
-from .cuda_native import FusedScaleMaskSoftmax, LayerNorm, MultiHeadAttention
-
-__all__ = [
- "LayerNorm",
- "FusedScaleMaskSoftmax",
- "MultiHeadAttention",
-]
diff --git a/colossalai/kernel/cuda_native/csrc/gptq/column_remap.cu b/colossalai/kernel/cuda_native/csrc/gptq/column_remap.cu
deleted file mode 100644
index 2b1b366b1c02..000000000000
--- a/colossalai/kernel/cuda_native/csrc/gptq/column_remap.cu
+++ /dev/null
@@ -1,63 +0,0 @@
-// Adapted from turboderp exllama: https://github.com/turboderp/exllama
-
-#include "column_remap.cuh"
-#include "util.cuh"
-
-const int SHUF_BLOCKSIZE_X = 256;
-const int SHUF_BLOCKSIZE_Y = 16;
-
-__global__ void column_remap_kernel
-(
- const half* __restrict__ x,
- half* __restrict__ x_new,
- const int x_width,
- const int x_height,
- const uint32_t* x_map
-)
-{
- int x_column = SHUF_BLOCKSIZE_X * blockIdx.x + threadIdx.x;
- int x_row = SHUF_BLOCKSIZE_Y * blockIdx.y;
- if (x_column >= x_width) return;
- //if (x_row >= x_height) return;
-
- int x_stride = x_width;
- int x_idx = x_row * x_stride + x_column;
-
- int x_row_end = min(x_row + SHUF_BLOCKSIZE_Y, x_height);
- int x_idx_end = x_row_end * x_stride + x_column;
-
- int s_column = x_map[x_column];
- int s_idx = x_row * x_stride + s_column;
-
- while (x_idx < x_idx_end)
- {
- x_new[x_idx] = x[s_idx];
- x_idx += x_stride;
- s_idx += x_stride;
- }
-}
-
-// Remap columns in x to correspond to sequential group index before matmul
-//
-// perform x -> seq_x such that seq_x @ seq_w == x @ w
-
-void column_remap_cuda
-(
- const half* x,
- half* x_new,
- const int x_height,
- const int x_width,
- const uint32_t* x_map
-)
-{
- dim3 threads(SHUF_BLOCKSIZE_X, 1, 1);
-
- dim3 blocks
- (
- (x_width + SHUF_BLOCKSIZE_X - 1) / SHUF_BLOCKSIZE_X,
- (x_height + SHUF_BLOCKSIZE_Y - 1) / SHUF_BLOCKSIZE_Y,
- 1
- );
-
- column_remap_kernel<<
## Roadmap of our implementation
@@ -34,11 +43,15 @@ In this section we discuss how the colossal inference works and integrates with
- [x] policy
- [x] context forward
- [x] token forward
-- [ ] Replace the kernels with `faster-transformer` in token-forward stage
-- [ ] Support all models
+ - [x] support flash-decoding
+- [x] Support all models
- [x] Llama
+ - [x] Llama-2
- [x] Bloom
- - [ ] Chatglm2
+ - [x] Chatglm2
+- [x] Quantization
+ - [x] GPTQ
+ - [x] SmoothQuant
- [ ] Benchmarking for all models
## Get started
@@ -51,23 +64,19 @@ pip install -e .
### Requirements
-dependencies
+Install dependencies.
```bash
-pytorch= 1.13.1 (gpu)
-cuda>= 11.6
-transformers= 4.30.2
-triton==2.0.0.dev20221202
-# for install vllm, please use this branch to install https://github.com/tiandiao123/vllm/tree/setup_branch
-vllm
-# for install flash-attention, please use commit hash: 67ae6fd74b4bc99c36b2ce524cf139c35663793c
-flash-attention
-
-# install lightllm since we depend on lightllm triton kernels
-git clone https://github.com/ModelTC/lightllm
-git checkout 28c1267cfca536b7b4f28e921e03de735b003039
-cd lightllm
-pip3 install -e .
+pip install -r requirements/requirements-infer.txt
+
+# if you want use smoothquant quantization, please install torch-int
+git clone --recurse-submodules https://github.com/Guangxuan-Xiao/torch-int.git
+cd torch-int
+git checkout 65266db1eadba5ca78941b789803929e6e6c6856
+pip install -r requirements.txt
+source environment.sh
+bash build_cutlass.sh
+python setup.py install
```
### Docker
@@ -80,25 +89,63 @@ docker pull hpcaitech/colossalai-inference:v2
docker run -it --gpus all --name ANY_NAME -v $PWD:/workspace -w /workspace hpcaitech/colossalai-inference:v2 /bin/bash
# enter into docker container
-cd /path/to/CollossalAI
+cd /path/to/ColossalAI
pip install -e .
-# install lightllm
-git clone https://github.com/ModelTC/lightllm
-git checkout 28c1267cfca536b7b4f28e921e03de735b003039
-cd lightllm
-pip3 install -e .
-
-
```
-### Dive into fast-inference!
+## Usage
+### Quick start
example files are in
```bash
-cd colossalai.examples
-python xx
+cd ColossalAI/examples
+python hybrid_llama.py --path /path/to/model --tp_size 2 --pp_size 2 --batch_size 4 --max_input_size 32 --max_out_len 16 --micro_batch_size 2
+```
+
+
+
+### Example
+```python
+# import module
+from colossalai.inference import CaiInferEngine
+import colossalai
+from transformers import LlamaForCausalLM, LlamaTokenizer
+
+#launch distributed environment
+colossalai.launch_from_torch(config={})
+
+# load original model and tokenizer
+model = LlamaForCausalLM.from_pretrained("/path/to/model")
+tokenizer = LlamaTokenizer.from_pretrained("/path/to/model")
+
+# generate token ids
+input = ["Introduce a landmark in London","Introduce a landmark in Singapore"]
+data = tokenizer(input, return_tensors='pt')
+
+# set parallel parameters
+tp_size=2
+pp_size=2
+max_output_len=32
+micro_batch_size=1
+
+# initial inference engine
+engine = CaiInferEngine(
+ tp_size=tp_size,
+ pp_size=pp_size,
+ model=model,
+ max_output_len=max_output_len,
+ micro_batch_size=micro_batch_size,
+)
+
+# inference
+output = engine.generate(data)
+
+# get results
+if dist.get_rank() == 0:
+ assert len(output[0]) == max_output_len, f"{len(output)}, {max_output_len}"
+
```
## Performance
@@ -113,7 +160,9 @@ For various models, experiments were conducted using multiple batch sizes under
Currently the stats below are calculated based on A100 (single GPU), and we calculate token latency based on average values of context-forward and decoding forward process, which means we combine both of processes to calculate token generation times. We are actively developing new features and methods to further optimize the performance of LLM models. Please stay tuned.
-#### Llama
+### Tensor Parallelism Inference
+
+##### Llama
| batch_size | 8 | 16 | 32 |
| :---------------------: | :----: | :----: | :----: |
@@ -122,7 +171,7 @@ Currently the stats below are calculated based on A100 (single GPU), and we calc

-### Bloom
+#### Bloom
| batch_size | 8 | 16 | 32 |
| :---------------------: | :----: | :----: | :----: |
@@ -131,4 +180,50 @@ Currently the stats below are calculated based on A100 (single GPU), and we calc

+
+### Pipline Parallelism Inference
+We conducted multiple benchmark tests to evaluate the performance. We compared the inference `latency` and `throughputs` between `Pipeline Inference` and `hugging face` pipeline. The test environment is 2 * A10, 20G / 2 * A800, 80G. We set input length=1024, output length=128.
+
+
+#### A10 7b, fp16
+
+| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(8) | 32(8) | 32(16)|
+| :-------------------------: | :---: | :---:| :---: | :---: | :---: | :---: |
+| Pipeline Inference | 40.35 | 77.10| 139.03| 232.70| 257.81| OOM |
+| Hugging Face | 41.43 | 65.30| 91.93 | 114.62| OOM | OOM |
+
+
+
+
+#### A10 13b, fp16
+
+| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(4) |
+| :---: | :---: | :---: | :---: | :---: |
+| Pipeline Inference | 25.39 | 47.09 | 83.7 | 89.46 |
+| Hugging Face | 23.48 | 37.59 | 53.44 | OOM |
+
+
+
+
+#### A800 7b, fp16
+
+| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(16) |
+| :---: | :---: | :---: | :---: | :---: | :---: |
+| Pipeline Inference| 57.97 | 110.13 | 213.33 | 389.86 | 670.12 |
+| Hugging Face | 42.44 | 76.5 | 151.97 | 212.88 | 256.13 |
+
+
+
+### Quantization LLama
+
+| batch_size | 8 | 16 | 32 |
+| :---------------------: | :----: | :----: | :----: |
+| auto-gptq | 199.20 | 232.56 | 253.26 |
+| smooth-quant | 142.28 | 222.96 | 300.59 |
+| colossal-gptq | 231.98 | 388.87 | 573.03 |
+
+
+
+
+
The results of more models are coming soon!
diff --git a/colossalai/inference/__init__.py b/colossalai/inference/__init__.py
index 35891307e754..a95205efaa78 100644
--- a/colossalai/inference/__init__.py
+++ b/colossalai/inference/__init__.py
@@ -1,3 +1,4 @@
-from .pipeline import PPInferEngine
+from .engine import InferenceEngine
+from .engine.policies import BloomModelInferPolicy, ChatGLM2InferPolicy, LlamaModelInferPolicy
-__all__ = ["PPInferEngine"]
+__all__ = ["InferenceEngine", "LlamaModelInferPolicy", "BloomModelInferPolicy", "ChatGLM2InferPolicy"]
diff --git a/colossalai/inference/engine/__init__.py b/colossalai/inference/engine/__init__.py
new file mode 100644
index 000000000000..6e60da695a22
--- /dev/null
+++ b/colossalai/inference/engine/__init__.py
@@ -0,0 +1,3 @@
+from .engine import InferenceEngine
+
+__all__ = ["InferenceEngine"]
diff --git a/colossalai/inference/engine/engine.py b/colossalai/inference/engine/engine.py
new file mode 100644
index 000000000000..61da5858aa86
--- /dev/null
+++ b/colossalai/inference/engine/engine.py
@@ -0,0 +1,195 @@
+from typing import Union
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from transformers.utils import logging
+
+from colossalai.cluster import ProcessGroupMesh
+from colossalai.pipeline.schedule.generate import GenerateSchedule
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer import ShardConfig, ShardFormer
+from colossalai.shardformer.policies.base_policy import Policy
+
+from ..kv_cache import MemoryManager
+from .microbatch_manager import MicroBatchManager
+from .policies import model_policy_map
+
+PP_AXIS, TP_AXIS = 0, 1
+
+_supported_models = [
+ "LlamaForCausalLM",
+ "BloomForCausalLM",
+ "LlamaGPTQForCausalLM",
+ "SmoothLlamaForCausalLM",
+ "ChatGLMForConditionalGeneration",
+]
+
+
+class InferenceEngine:
+ """
+ InferenceEngine is a class that handles the pipeline parallel inference.
+
+ Args:
+ tp_size (int): the size of tensor parallelism.
+ pp_size (int): the size of pipeline parallelism.
+ dtype (str): the data type of the model, should be one of 'fp16', 'fp32', 'bf16'.
+ model (`nn.Module`): the model not in pipeline style, and will be modified with `ShardFormer`.
+ model_policy (`colossalai.shardformer.policies.base_policy.Policy`): the policy to shardformer model. It will be determined by the model type if not provided.
+ micro_batch_size (int): the micro batch size. Only useful when `pp_size` > 1.
+ micro_batch_buffer_size (int): the buffer size for micro batch. Normally, it should be the same as the number of pipeline stages.
+ max_batch_size (int): the maximum batch size.
+ max_input_len (int): the maximum input length.
+ max_output_len (int): the maximum output length.
+ quant (str): the quantization method, should be one of 'smoothquant', 'gptq', None.
+ verbose (bool): whether to return the time cost of each step.
+
+ """
+
+ def __init__(
+ self,
+ tp_size: int = 1,
+ pp_size: int = 1,
+ dtype: str = "fp16",
+ model: nn.Module = None,
+ model_policy: Policy = None,
+ micro_batch_size: int = 1,
+ micro_batch_buffer_size: int = None,
+ max_batch_size: int = 4,
+ max_input_len: int = 32,
+ max_output_len: int = 32,
+ quant: str = None,
+ verbose: bool = False,
+ # TODO: implement early_stopping, and various gerneration options
+ early_stopping: bool = False,
+ do_sample: bool = False,
+ num_beams: int = 1,
+ ) -> None:
+ if quant == "gptq":
+ from ..quant.gptq import GPTQManager
+
+ self.gptq_manager = GPTQManager(model.quantize_config, max_input_len=max_input_len)
+ model = model.model
+ elif quant == "smoothquant":
+ model = model.model
+
+ assert model.__class__.__name__ in _supported_models, f"Model {model.__class__.__name__} is not supported."
+ assert (
+ tp_size * pp_size == dist.get_world_size()
+ ), f"TP size({tp_size}) * PP size({pp_size}) should be equal to the global world size ({dist.get_world_size()})"
+ assert model, "Model should be provided."
+ assert dtype in ["fp16", "fp32", "bf16"], "dtype should be one of 'fp16', 'fp32', 'bf16'"
+
+ assert max_batch_size <= 64, "Max batch size exceeds the constraint"
+ assert max_input_len + max_output_len <= 4096, "Max length exceeds the constraint"
+ assert quant in ["smoothquant", "gptq", None], "quant should be one of 'smoothquant', 'gptq'"
+ self.pp_size = pp_size
+ self.tp_size = tp_size
+ self.quant = quant
+
+ logger = logging.get_logger(__name__)
+ if quant == "smoothquant" and dtype != "fp32":
+ dtype = "fp32"
+ logger.warning_once("Warning: smoothquant only support fp32 and int8 mix precision. set dtype to fp32")
+
+ if dtype == "fp16":
+ self.dtype = torch.float16
+ model.half()
+ elif dtype == "bf16":
+ self.dtype = torch.bfloat16
+ model.to(torch.bfloat16)
+ else:
+ self.dtype = torch.float32
+
+ if model_policy is None:
+ model_policy = model_policy_map[model.config.model_type]()
+
+ # Init pg mesh
+ pg_mesh = ProcessGroupMesh(pp_size, tp_size)
+
+ stage_manager = PipelineStageManager(pg_mesh, PP_AXIS, True if pp_size * tp_size > 1 else False)
+ self.cache_manager_list = [
+ self._init_manager(model, max_batch_size, max_input_len, max_output_len)
+ for _ in range(micro_batch_buffer_size or pp_size)
+ ]
+ self.mb_manager = MicroBatchManager(
+ stage_manager.stage,
+ micro_batch_size,
+ micro_batch_buffer_size or pp_size,
+ max_input_len,
+ max_output_len,
+ self.cache_manager_list,
+ )
+ self.verbose = verbose
+ self.schedule = GenerateSchedule(stage_manager, self.mb_manager, verbose)
+
+ self.model = self._shardformer(
+ model, model_policy, stage_manager, pg_mesh.get_group_along_axis(TP_AXIS) if pp_size * tp_size > 1 else None
+ )
+ if quant == "gptq":
+ self.gptq_manager.post_init_gptq_buffer(self.model)
+
+ def generate(self, input_list: Union[list, dict]):
+ """
+ Args:
+ input_list (list): a list of input data, each element is a `BatchEncoding` or `dict`.
+
+ Returns:
+ out (list): a list of output data, each element is a list of token.
+ timestamp (float): the time cost of the inference, only return when verbose is `True`.
+ """
+
+ out, timestamp = self.schedule.generate_step(self.model, iter([input_list]))
+ if self.verbose:
+ return out, timestamp
+ else:
+ return out
+
+ def _shardformer(self, model, model_policy, stage_manager, tp_group):
+ shardconfig = ShardConfig(
+ tensor_parallel_process_group=tp_group,
+ pipeline_stage_manager=stage_manager,
+ enable_tensor_parallelism=(self.tp_size > 1),
+ enable_fused_normalization=False,
+ enable_all_optimization=False,
+ enable_flash_attention=False,
+ enable_jit_fused=False,
+ enable_sequence_parallelism=False,
+ extra_kwargs={"quant": self.quant},
+ )
+ shardformer = ShardFormer(shard_config=shardconfig)
+ shard_model, _ = shardformer.optimize(model, model_policy)
+ return shard_model.cuda()
+
+ def _init_manager(self, model, max_batch_size: int, max_input_len: int, max_output_len: int) -> None:
+ max_total_token_num = max_batch_size * (max_input_len + max_output_len)
+ if model.config.model_type == "llama":
+ head_dim = model.config.hidden_size // model.config.num_attention_heads
+ head_num = model.config.num_key_value_heads // self.tp_size
+ num_hidden_layers = (
+ model.config.num_hidden_layers
+ if hasattr(model.config, "num_hidden_layers")
+ else model.config.num_layers
+ )
+ layer_num = num_hidden_layers // self.pp_size
+ elif model.config.model_type == "bloom":
+ head_dim = model.config.hidden_size // model.config.n_head
+ head_num = model.config.n_head // self.tp_size
+ num_hidden_layers = model.config.n_layer
+ layer_num = num_hidden_layers // self.pp_size
+ elif model.config.model_type == "chatglm":
+ head_dim = model.config.hidden_size // model.config.num_attention_heads
+ if model.config.multi_query_attention:
+ head_num = model.config.multi_query_group_num // self.tp_size
+ else:
+ head_num = model.config.num_attention_heads // self.tp_size
+ num_hidden_layers = model.config.num_layers
+ layer_num = num_hidden_layers // self.pp_size
+ else:
+ raise NotImplementedError("Only support llama, bloom and chatglm model.")
+
+ if self.quant == "smoothquant":
+ cache_manager = MemoryManager(max_total_token_num, torch.int8, head_num, head_dim, layer_num)
+ else:
+ cache_manager = MemoryManager(max_total_token_num, self.dtype, head_num, head_dim, layer_num)
+ return cache_manager
diff --git a/colossalai/inference/pipeline/microbatch_manager.py b/colossalai/inference/engine/microbatch_manager.py
similarity index 56%
rename from colossalai/inference/pipeline/microbatch_manager.py
rename to colossalai/inference/engine/microbatch_manager.py
index 49d1bf3f42cb..7264b81e06a0 100644
--- a/colossalai/inference/pipeline/microbatch_manager.py
+++ b/colossalai/inference/engine/microbatch_manager.py
@@ -1,8 +1,10 @@
from enum import Enum
-from typing import Dict, Tuple
+from typing import Dict
import torch
+from ..kv_cache import BatchInferState, MemoryManager
+
__all__ = "MicroBatchManager"
@@ -15,8 +17,8 @@ class Status(Enum):
class MicroBatchDescription:
"""
- This is the class to record the infomation of each microbatch, and also do some update operation.
- This clase is the base class of `HeadMicroBatchDescription` and `BodyMicroBatchDescription`, for more
+ This is the class to record the information of each microbatch, and also do some update operation.
+ This class is the base class of `HeadMicroBatchDescription` and `BodyMicroBatchDescription`, for more
details, please refer to the doc of these two classes blow.
Args:
@@ -27,21 +29,19 @@ class MicroBatchDescription:
def __init__(
self,
inputs_dict: Dict[str, torch.Tensor],
- output_dict: Dict[str, torch.Tensor],
- new_length: int,
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager: MemoryManager,
) -> None:
- assert output_dict.get("hidden_states") is not None
- self.mb_length = output_dict["hidden_states"].shape[-2]
- self.target_length = self.mb_length + new_length
- self.kv_cache = ()
-
- def update(self, output_dict: Dict[str, torch.Tensor] = None, new_token: torch.Tensor = None):
- if output_dict is not None:
- self._update_kvcache(output_dict["past_key_values"])
+ self.mb_length = inputs_dict["input_ids"].shape[-1]
+ self.target_length = self.mb_length + max_output_len
+ self.infer_state = BatchInferState.init_from_batch(
+ batch=inputs_dict, max_input_len=max_input_len, max_output_len=max_output_len, cache_manager=cache_manager
+ )
+ # print(f"[init] {inputs_dict}, {max_input_len}, {max_output_len}, {cache_manager}, {self.infer_state}")
- def _update_kvcache(self, kv_cache: Tuple):
- assert type(kv_cache) == tuple
- self.kv_cache = kv_cache
+ def update(self, *args, **kwargs):
+ pass
@property
def state(self):
@@ -61,36 +61,38 @@ def state(self):
@property
def cur_length(self):
"""
- Return the current sequnence length of micro batch
+ Return the current sequence length of micro batch
"""
class HeadMicroBatchDescription(MicroBatchDescription):
"""
- This class is used to record the infomation of the first stage of pipeline, the first stage should have attributes `input_ids` and `attention_mask`
- and `new_tokens`, and the `new_tokens` is the tokens generated by the first stage. Also due to the schdule of pipeline, the operation to update the
+ This class is used to record the information of the first stage of pipeline, the first stage should have attributes `input_ids` and `attention_mask`
+ and `new_tokens`, and the `new_tokens` is the tokens generated by the first stage. Also due to the schedule of pipeline, the operation to update the
information and the condition to determine the state is different from other stages.
Args:
inputs_dict (Dict[str, torch.Tensor]): the inputs of current stage. The key should have `input_ids` and `attention_mask`.
output_dict (Dict[str, torch.Tensor]): the outputs of previous stage. The key should have `hidden_states` and `past_key_values`.
- new_length (int): the new length of the input sequence.
"""
def __init__(
- self, inputs_dict: Dict[str, torch.Tensor], output_dict: Dict[str, torch.Tensor], new_length: int
+ self,
+ inputs_dict: Dict[str, torch.Tensor],
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager: MemoryManager,
) -> None:
- super().__init__(inputs_dict, output_dict, new_length)
+ super().__init__(inputs_dict, max_input_len, max_output_len, cache_manager)
assert inputs_dict is not None
assert inputs_dict.get("input_ids") is not None and inputs_dict.get("attention_mask") is not None
self.input_ids = inputs_dict["input_ids"]
self.attn_mask = inputs_dict["attention_mask"]
self.new_tokens = None
- def update(self, output_dict: Dict[str, torch.Tensor] = None, new_token: torch.Tensor = None):
- super().update(output_dict, new_token)
+ def update(self, new_token: torch.Tensor = None):
if new_token is not None:
self._update_newtokens(new_token)
if self.state is not Status.DONE and new_token is not None:
@@ -121,20 +123,20 @@ def cur_length(self):
class BodyMicroBatchDescription(MicroBatchDescription):
"""
- This class is used to record the infomation of the stages except the first stage of pipeline, the stages should have attributes `hidden_states` and `past_key_values`,
+ This class is used to record the information of the stages except the first stage of pipeline, the stages should have attributes `hidden_states` and `past_key_values`,
Args:
inputs_dict (Dict[str, torch.Tensor]): will always be `None`. Other stages only receive hiddenstates from previous stage.
- output_dict (Dict[str, torch.Tensor]): the outputs of previous stage. The key should have `hidden_states` and `past_key_values`.
"""
def __init__(
- self, inputs_dict: Dict[str, torch.Tensor], output_dict: Dict[str, torch.Tensor], new_length: int
+ self,
+ inputs_dict: Dict[str, torch.Tensor],
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager: MemoryManager,
) -> None:
- super().__init__(inputs_dict, output_dict, new_length)
-
- def update(self, output_dict: Dict[str, torch.Tensor] = None, new_token: torch.Tensor = None):
- super().update(output_dict, new_token)
+ super().__init__(inputs_dict, max_input_len, max_output_len, cache_manager)
@property
def cur_length(self):
@@ -142,10 +144,7 @@ def cur_length(self):
When there is no kv_cache, the length is mb_length, otherwise the sequence length is `kv_cache[0][0].shape[-2]` plus 1
"""
- if len(self.kv_cache) == 0:
- return self.mb_length
- else:
- return self.kv_cache[0][0].shape[-2] + 1
+ return self.infer_state.seq_len.max().item()
class MicroBatchManager:
@@ -154,85 +153,96 @@ class MicroBatchManager:
Args:
stage (int): stage id of current stage.
- new_length (int): the new length of the input sequence.
micro_batch_size (int): the micro batch size.
micro_batch_buffer_size (int): the buffer size for micro batch. Normally, it should be the same as the number of pipeline stages.
"""
- def __init__(self, stage: int, new_length: int, micro_batch_size: int, micro_batch_buffer_size: int):
+ def __init__(
+ self,
+ stage: int,
+ micro_batch_size: int,
+ micro_batch_buffer_size: int,
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager_list: MemoryManager,
+ ):
self.stage = stage
- self.new_length = new_length
self.micro_batch_size = micro_batch_size
self.buffer_size = micro_batch_buffer_size
- self.mb_descrption_buffer = {}
+ self.max_input_len = max_input_len
+ self.max_output_len = max_output_len
+ self.cache_manager_list = cache_manager_list
+ self.mb_description_buffer = {}
self.new_tokens_buffer = {}
self.idx = 0
- def step(self, inputs_dict=None, output_dict: Dict[str, torch.Tensor] = None, new_token: torch.Tensor = None):
+ def add_description(self, inputs_dict: Dict[str, torch.Tensor]):
+ if self.stage == 0:
+ self.mb_description_buffer[self.idx] = HeadMicroBatchDescription(
+ inputs_dict, self.max_input_len, self.max_output_len, self.cache_manager_list[self.idx]
+ )
+ else:
+ self.mb_description_buffer[self.idx] = BodyMicroBatchDescription(
+ inputs_dict, self.max_input_len, self.max_output_len, self.cache_manager_list[self.idx]
+ )
+
+ def step(self, new_token: torch.Tensor = None):
"""
Update the state if microbatch manager, 2 conditions.
- 1. For first stage in PREFILL, receive inputs and outputs, `_add_descrption` will save its inputs.
- 2. For other conditon, only receive the output of previous stage, and update the descrption.
+ 1. For first stage in PREFILL, receive inputs and outputs, `_add_description` will save its inputs.
+ 2. For other condition, only receive the output of previous stage, and update the description.
Args:
inputs_dict (Dict[str, torch.Tensor]): the inputs of current stage. The key should have `input_ids` and `attention_mask`.
output_dict (Dict[str, torch.Tensor]): the outputs of previous stage. The key should have `hidden_states` and `past_key_values`.
new_token (torch.Tensor): the new token generated by current stage.
"""
- # Add descrption first if the descrption is None
- if inputs_dict is None and output_dict is None and new_token is None:
- return Status.PREFILL
- if self.mb_descrption_buffer.get(self.idx) is None:
- self._add_descrption(inputs_dict, output_dict)
- self.cur_descrption.update(output_dict, new_token)
+ # Add description first if the description is None
+ self.cur_description.update(new_token)
return self.cur_state
def export_new_tokens(self):
new_tokens_list = []
- for i in self.mb_descrption_buffer.values():
+ for i in self.mb_description_buffer.values():
new_tokens_list.extend(i.new_tokens.tolist())
return new_tokens_list
def is_micro_batch_done(self):
- if len(self.mb_descrption_buffer) == 0:
+ if len(self.mb_description_buffer) == 0:
return False
- for mb in self.mb_descrption_buffer.values():
+ for mb in self.mb_description_buffer.values():
if mb.state != Status.DONE:
return False
return True
def clear(self):
- self.mb_descrption_buffer.clear()
+ self.mb_description_buffer.clear()
+ for cache in self.cache_manager_list:
+ cache.free_all()
def next(self):
self.idx = (self.idx + 1) % self.buffer_size
- def _add_descrption(self, inputs_dict: Dict[str, torch.Tensor], output_dict: Dict[str, torch.Tensor]):
- if self.stage == 0:
- self.mb_descrption_buffer[self.idx] = HeadMicroBatchDescription(inputs_dict, output_dict, self.new_length)
- else:
- self.mb_descrption_buffer[self.idx] = BodyMicroBatchDescription(inputs_dict, output_dict, self.new_length)
-
- def _remove_descrption(self):
- self.mb_descrption_buffer.pop(self.idx)
+ def _remove_description(self):
+ self.mb_description_buffer.pop(self.idx)
@property
- def cur_descrption(self) -> MicroBatchDescription:
- return self.mb_descrption_buffer.get(self.idx)
+ def cur_description(self) -> MicroBatchDescription:
+ return self.mb_description_buffer.get(self.idx)
@property
- def cur_kv_cache(self):
- if self.cur_descrption is None:
+ def cur_infer_state(self):
+ if self.cur_description is None:
return None
- return self.cur_descrption.kv_cache
+ return self.cur_description.infer_state
@property
def cur_state(self):
"""
- Return the state of current micro batch, when current descrption is None, the state is PREFILL
+ Return the state of current micro batch, when current description is None, the state is PREFILL
"""
- if self.cur_descrption is None:
+ if self.cur_description is None:
return Status.PREFILL
- return self.cur_descrption.state
+ return self.cur_description.state
diff --git a/colossalai/inference/engine/modeling/__init__.py b/colossalai/inference/engine/modeling/__init__.py
new file mode 100644
index 000000000000..8a9e9999d3c5
--- /dev/null
+++ b/colossalai/inference/engine/modeling/__init__.py
@@ -0,0 +1,5 @@
+from .bloom import BloomInferenceForwards
+from .chatglm2 import ChatGLM2InferenceForwards
+from .llama import LlamaInferenceForwards
+
+__all__ = ["LlamaInferenceForwards", "BloomInferenceForwards", "ChatGLM2InferenceForwards"]
diff --git a/colossalai/inference/tensor_parallel/modeling/_utils.py b/colossalai/inference/engine/modeling/_utils.py
similarity index 100%
rename from colossalai/inference/tensor_parallel/modeling/_utils.py
rename to colossalai/inference/engine/modeling/_utils.py
diff --git a/colossalai/inference/engine/modeling/bloom.py b/colossalai/inference/engine/modeling/bloom.py
new file mode 100644
index 000000000000..4c098d3e4c80
--- /dev/null
+++ b/colossalai/inference/engine/modeling/bloom.py
@@ -0,0 +1,452 @@
+import math
+import warnings
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.distributed as dist
+from torch.nn import functional as F
+from transformers.models.bloom.modeling_bloom import (
+ BaseModelOutputWithPastAndCrossAttentions,
+ BloomAttention,
+ BloomBlock,
+ BloomForCausalLM,
+ BloomModel,
+)
+from transformers.utils import logging
+
+from colossalai.inference.kv_cache.batch_infer_state import BatchInferState
+from colossalai.kernel.triton import bloom_context_attn_fwd, copy_kv_cache_to_dest, token_attention_fwd
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
+try:
+ from lightllm.models.bloom.triton_kernel.context_flashattention_nopad import (
+ context_attention_fwd as lightllm_bloom_context_attention_fwd,
+ )
+
+ HAS_LIGHTLLM_KERNEL = True
+except:
+ HAS_LIGHTLLM_KERNEL = False
+
+
+def generate_alibi(n_head, dtype=torch.float16):
+ """
+ This method is adapted from `_generate_alibi` function
+ in `lightllm/models/bloom/layer_weights/transformer_layer_weight.py`
+ of the ModelTC/lightllm GitHub repository.
+ This method is originally the `build_alibi_tensor` function
+ in `transformers/models/bloom/modeling_bloom.py`
+ of the huggingface/transformers GitHub repository.
+ """
+
+ def get_slopes_power_of_2(n):
+ start = 2 ** (-(2 ** -(math.log2(n) - 3)))
+ return [start * start**i for i in range(n)]
+
+ def get_slopes(n):
+ if math.log2(n).is_integer():
+ return get_slopes_power_of_2(n)
+ else:
+ closest_power_of_2 = 2 ** math.floor(math.log2(n))
+ slopes_power_of_2 = get_slopes_power_of_2(closest_power_of_2)
+ slopes_double = get_slopes(2 * closest_power_of_2)
+ slopes_combined = slopes_power_of_2 + slopes_double[0::2][: n - closest_power_of_2]
+ return slopes_combined
+
+ slopes = get_slopes(n_head)
+ return torch.tensor(slopes, dtype=dtype)
+
+
+class BloomInferenceForwards:
+ """
+ This class serves a micro library for bloom inference forwards.
+ We intend to replace the forward methods for BloomForCausalLM, BloomModel, BloomBlock, and BloomAttention,
+ as well as prepare_inputs_for_generation method for BloomForCausalLM.
+ For future improvement, we might want to skip replacing methods for BloomForCausalLM,
+ and call BloomModel.forward iteratively in TpInferEngine
+ """
+
+ @staticmethod
+ def bloom_for_causal_lm_forward(
+ self: BloomForCausalLM,
+ input_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = False,
+ output_attentions: Optional[bool] = False,
+ output_hidden_states: Optional[bool] = False,
+ return_dict: Optional[bool] = False,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ tp_group: Optional[dist.ProcessGroup] = None,
+ **deprecated_arguments,
+ ):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
+ `labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
+ are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
+ """
+ logger = logging.get_logger(__name__)
+
+ if deprecated_arguments.pop("position_ids", False) is not False:
+ # `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
+ warnings.warn(
+ "`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
+ " passing `position_ids`.",
+ FutureWarning,
+ )
+
+ # TODO(jianghai): left the recording kv-value tensors as () or None type, this feature may be added in the future.
+ if output_attentions:
+ logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
+ output_hidden_states = False
+
+ # If is first stage and hidden_states is not None, go throught lm_head first
+ if stage_manager.is_first_stage() and hidden_states is not None:
+ lm_logits = self.lm_head(hidden_states)
+ return {"logits": lm_logits}
+
+ outputs = BloomInferenceForwards.bloom_model_forward(
+ self.transformer,
+ input_ids,
+ past_key_values=past_key_values,
+ attention_mask=attention_mask,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ infer_state=infer_state,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ tp_group=tp_group,
+ )
+
+ return outputs
+
+ @staticmethod
+ def bloom_model_forward(
+ self: BloomModel,
+ input_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.LongTensor] = None,
+ inputs_embeds: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = False,
+ return_dict: Optional[bool] = None,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ tp_group: Optional[dist.ProcessGroup] = None,
+ **deprecated_arguments,
+ ) -> Union[Tuple[torch.Tensor, ...], BaseModelOutputWithPastAndCrossAttentions]:
+ logger = logging.get_logger(__name__)
+
+ # add warnings here
+ if output_attentions:
+ logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
+ output_hidden_states = False
+ if use_cache:
+ logger.warning_once("use_cache=True is not supported for pipeline models at the moment.")
+ use_cache = False
+
+ if deprecated_arguments.pop("position_ids", False) is not False:
+ # `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
+ warnings.warn(
+ "`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
+ " passing `position_ids`.",
+ FutureWarning,
+ )
+ if len(deprecated_arguments) > 0:
+ raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape batch_size x num_heads x N x N
+ # head_mask has shape n_layer x batch x num_heads x N x N
+ head_mask = self.get_head_mask(head_mask, self.config.n_layer)
+
+ # first stage
+ if stage_manager.is_first_stage():
+ # check inputs and inputs embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ if inputs_embeds is None:
+ inputs_embeds = self.word_embeddings(input_ids)
+
+ hidden_states = self.word_embeddings_layernorm(inputs_embeds)
+ # other stage
+ else:
+ input_shape = hidden_states.shape[:-1]
+ batch_size, seq_length = input_shape
+
+ if infer_state.is_context_stage:
+ past_key_values_length = 0
+ else:
+ past_key_values_length = infer_state.max_len_in_batch - 1
+
+ if seq_length != 1:
+ # prefill stage
+ infer_state.is_context_stage = True # set prefill stage, notify attention layer
+ infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
+ BatchInferState.init_block_loc(
+ infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
+ )
+ else:
+ infer_state.is_context_stage = False
+ alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
+ if alloc_mem is not None:
+ infer_state.decode_is_contiguous = True
+ infer_state.decode_mem_index = alloc_mem[0]
+ infer_state.decode_mem_start = alloc_mem[1]
+ infer_state.decode_mem_end = alloc_mem[2]
+ infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
+ else:
+ print(f" *** Encountered allocation non-contiguous")
+ print(f" infer_state.max_len_in_batch : {infer_state.max_len_in_batch}")
+ infer_state.decode_is_contiguous = False
+ alloc_mem = infer_state.cache_manager.alloc(batch_size)
+ infer_state.decode_mem_index = alloc_mem
+ infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
+
+ if attention_mask is None:
+ attention_mask = torch.ones((batch_size, infer_state.max_len_in_batch), device=hidden_states.device)
+ else:
+ attention_mask = attention_mask.to(hidden_states.device)
+
+ # NOTE revise: we might want to store a single 1D alibi(length is #heads) in model,
+ # or store to BatchInferState to prevent re-calculating
+ # When we have multiple process group (e.g. dp together with tp), we need to pass the pg to here
+ tp_size = dist.get_world_size(tp_group) if tp_group is not None else 1
+ curr_tp_rank = dist.get_rank(tp_group) if tp_group is not None else 0
+ alibi = (
+ generate_alibi(self.num_heads * tp_size)
+ .contiguous()[curr_tp_rank * self.num_heads : (curr_tp_rank + 1) * self.num_heads]
+ .cuda()
+ )
+ causal_mask = self._prepare_attn_mask(
+ attention_mask,
+ input_shape=(batch_size, seq_length),
+ past_key_values_length=past_key_values_length,
+ )
+
+ infer_state.decode_layer_id = 0
+
+ start_idx, end_idx = stage_index[0], stage_index[1]
+ if past_key_values is None:
+ past_key_values = tuple([None] * (end_idx - start_idx + 1))
+
+ for idx, past_key_value in zip(range(start_idx, end_idx), past_key_values):
+ block = self.h[idx]
+ outputs = block(
+ hidden_states,
+ layer_past=past_key_value,
+ attention_mask=causal_mask,
+ head_mask=head_mask[idx],
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ alibi=alibi,
+ infer_state=infer_state,
+ )
+
+ infer_state.decode_layer_id += 1
+ hidden_states = outputs[0]
+
+ if stage_manager.is_last_stage() or stage_manager.num_stages == 1:
+ hidden_states = self.ln_f(hidden_states)
+
+ # update indices
+ infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
+ infer_state.seq_len += 1
+ infer_state.max_len_in_batch += 1
+
+ # always return dict for imediate stage
+ return {"hidden_states": hidden_states}
+
+ @staticmethod
+ def bloom_block_forward(
+ self: BloomBlock,
+ hidden_states: torch.Tensor,
+ alibi: torch.Tensor,
+ attention_mask: torch.Tensor,
+ layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ infer_state: Optional[BatchInferState] = None,
+ ):
+ # hidden_states: [batch_size, seq_length, hidden_size]
+
+ # Layer norm at the beginning of the transformer layer.
+ layernorm_output = self.input_layernorm(hidden_states)
+
+ # Layer norm post the self attention.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = hidden_states
+
+ # Self attention.
+ attn_outputs = self.self_attention(
+ layernorm_output,
+ residual,
+ layer_past=layer_past,
+ attention_mask=attention_mask,
+ alibi=alibi,
+ head_mask=head_mask,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ infer_state=infer_state,
+ )
+
+ attention_output = attn_outputs[0]
+
+ outputs = attn_outputs[1:]
+
+ layernorm_output = self.post_attention_layernorm(attention_output)
+
+ # Get residual
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = attention_output
+
+ # MLP.
+ output = self.mlp(layernorm_output, residual)
+
+ if use_cache:
+ outputs = (output,) + outputs
+ else:
+ outputs = (output,) + outputs[1:]
+
+ return outputs # hidden_states, present, attentions
+
+ @staticmethod
+ def bloom_attention_forward(
+ self: BloomAttention,
+ hidden_states: torch.Tensor,
+ residual: torch.Tensor,
+ alibi: torch.Tensor,
+ attention_mask: torch.Tensor,
+ layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ infer_state: Optional[BatchInferState] = None,
+ ):
+ fused_qkv = self.query_key_value(hidden_states) # [batch_size, seq_length, 3 x hidden_size]
+
+ # 3 x [batch_size, seq_length, num_heads, head_dim]
+ (query_layer, key_layer, value_layer) = self._split_heads(fused_qkv)
+ batch_size, q_length, H, D_HEAD = query_layer.shape
+ k = key_layer.reshape(-1, H, D_HEAD) # batch_size * q_length, H, D_HEAD, q_lenth == 1
+ v = value_layer.reshape(-1, H, D_HEAD) # batch_size * q_length, H, D_HEAD, q_lenth == 1
+
+ mem_manager = infer_state.cache_manager
+ layer_id = infer_state.decode_layer_id
+
+ if infer_state.is_context_stage:
+ # context process
+ max_input_len = q_length
+ b_start_loc = infer_state.start_loc
+ b_seq_len = infer_state.seq_len[:batch_size]
+ q = query_layer.reshape(-1, H, D_HEAD)
+
+ copy_kv_cache_to_dest(k, infer_state.context_mem_index, mem_manager.key_buffer[layer_id])
+ copy_kv_cache_to_dest(v, infer_state.context_mem_index, mem_manager.value_buffer[layer_id])
+
+ # output = self.output[:batch_size*q_length, :, :]
+ output = torch.empty_like(q)
+
+ if HAS_LIGHTLLM_KERNEL:
+ lightllm_bloom_context_attention_fwd(q, k, v, output, alibi, b_start_loc, b_seq_len, max_input_len)
+ else:
+ bloom_context_attn_fwd(q, k, v, output, b_start_loc, b_seq_len, max_input_len, alibi)
+
+ context_layer = output.view(batch_size, q_length, H * D_HEAD)
+ else:
+ # query_layer = query_layer.transpose(1, 2).reshape(batch_size * self.num_heads, q_length, self.head_dim)
+ # need shape: batch_size, H, D_HEAD (q_length == 1), input q shape : (batch_size, q_length(1), H, D_HEAD)
+ assert q_length == 1, "for non-context process, we only support q_length == 1"
+ q = query_layer.reshape(-1, H, D_HEAD)
+
+ if infer_state.decode_is_contiguous:
+ # if decode is contiguous, then we copy to key cache and value cache in cache manager directly
+ cache_k = infer_state.cache_manager.key_buffer[layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_v = infer_state.cache_manager.value_buffer[layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_k.copy_(k)
+ cache_v.copy_(v)
+ else:
+ # if decode is not contiguous, use triton kernel to copy key and value cache
+ # k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head]
+ copy_kv_cache_to_dest(k, infer_state.decode_mem_index, mem_manager.key_buffer[layer_id])
+ copy_kv_cache_to_dest(v, infer_state.decode_mem_index, mem_manager.value_buffer[layer_id])
+
+ b_start_loc = infer_state.start_loc
+ b_loc = infer_state.block_loc
+ b_seq_len = infer_state.seq_len
+ output = torch.empty_like(q)
+ token_attention_fwd(
+ q,
+ mem_manager.key_buffer[layer_id],
+ mem_manager.value_buffer[layer_id],
+ output,
+ b_loc,
+ b_start_loc,
+ b_seq_len,
+ infer_state.max_len_in_batch,
+ alibi,
+ )
+
+ context_layer = output.view(batch_size, q_length, H * D_HEAD)
+
+ # NOTE: always set present as none for now, instead of returning past key value to the next decoding,
+ # we create the past key value pair from the cache manager
+ present = None
+
+ # aggregate results across tp ranks. See here: https://github.com/pytorch/pytorch/issues/76232
+ if self.pretraining_tp > 1 and self.slow_but_exact:
+ slices = self.hidden_size / self.pretraining_tp
+ output_tensor = torch.zeros_like(context_layer)
+ for i in range(self.pretraining_tp):
+ output_tensor = output_tensor + F.linear(
+ context_layer[:, :, int(i * slices) : int((i + 1) * slices)],
+ self.dense.weight[:, int(i * slices) : int((i + 1) * slices)],
+ )
+ else:
+ output_tensor = self.dense(context_layer)
+
+ # dropout is not required here during inference
+ output_tensor = residual + output_tensor
+
+ outputs = (output_tensor, present)
+ assert output_attentions is False, "we do not support output_attentions at this time"
+
+ return outputs
diff --git a/colossalai/inference/engine/modeling/chatglm2.py b/colossalai/inference/engine/modeling/chatglm2.py
new file mode 100644
index 000000000000..56e777bb2b87
--- /dev/null
+++ b/colossalai/inference/engine/modeling/chatglm2.py
@@ -0,0 +1,492 @@
+from typing import List, Optional, Tuple
+
+import torch
+from transformers.utils import logging
+
+from colossalai.inference.kv_cache import BatchInferState
+from colossalai.kernel.triton.token_attention_kernel import Llama2TokenAttentionForwards
+from colossalai.pipeline.stage_manager import PipelineStageManager
+from colossalai.shardformer import ShardConfig
+from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import (
+ ChatGLMForConditionalGeneration,
+ ChatGLMModel,
+ GLMBlock,
+ GLMTransformer,
+ SelfAttention,
+ split_tensor_along_last_dim,
+)
+
+from ._utils import copy_kv_to_mem_cache
+
+try:
+ from lightllm.models.chatglm2.triton_kernel.rotary_emb import rotary_emb_fwd as chatglm2_rotary_emb_fwd
+ from lightllm.models.llama2.triton_kernel.context_flashattention_nopad import (
+ context_attention_fwd as lightllm_llama2_context_attention_fwd,
+ )
+
+ HAS_LIGHTLLM_KERNEL = True
+except:
+ print("please install lightllm from source to run inference: https://github.com/ModelTC/lightllm")
+ HAS_LIGHTLLM_KERNEL = False
+
+
+def get_masks(self, input_ids, past_length, padding_mask=None):
+ batch_size, seq_length = input_ids.shape
+ full_attention_mask = torch.ones(batch_size, seq_length, seq_length, device=input_ids.device)
+ full_attention_mask.tril_()
+ if past_length:
+ full_attention_mask = torch.cat(
+ (
+ torch.ones(batch_size, seq_length, past_length, device=input_ids.device),
+ full_attention_mask,
+ ),
+ dim=-1,
+ )
+
+ if padding_mask is not None:
+ full_attention_mask = full_attention_mask * padding_mask.unsqueeze(1)
+ if not past_length and padding_mask is not None:
+ full_attention_mask -= padding_mask.unsqueeze(-1) - 1
+ full_attention_mask = (full_attention_mask < 0.5).bool()
+ full_attention_mask.unsqueeze_(1)
+ return full_attention_mask
+
+
+def get_position_ids(batch_size, seq_length, device):
+ position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)
+ return position_ids
+
+
+class ChatGLM2InferenceForwards:
+ """
+ This class holds forwards for Chatglm2 inference.
+ We intend to replace the forward methods for ChatGLMModel, ChatGLMEecoderLayer, and ChatGLMAttention.
+ """
+
+ @staticmethod
+ def chatglm_for_conditional_generation_forward(
+ self: ChatGLMForConditionalGeneration,
+ input_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = True,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ return_last_logit: Optional[bool] = False,
+ infer_state: Optional[BatchInferState] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ shard_config: ShardConfig = None,
+ ):
+ logger = logging.get_logger(__name__)
+
+ if output_attentions:
+ logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
+ output_hidden_states = False
+
+ # If is first stage and hidden_states is not None, go throught lm_head first
+ if stage_manager.is_first_stage() and hidden_states is not None:
+ if return_last_logit:
+ hidden_states = hidden_states[-1:]
+ lm_logits = self.transformer.output_layer(hidden_states)
+ lm_logits = lm_logits.transpose(0, 1).contiguous()
+ return {"logits": lm_logits}
+
+ outputs = self.transformer(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ attention_mask=attention_mask,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ infer_state=infer_state,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ shard_config=shard_config,
+ )
+
+ return outputs
+
+ @staticmethod
+ def chatglm_model_forward(
+ self: ChatGLMModel,
+ input_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.BoolTensor] = None,
+ full_attention_mask: Optional[torch.BoolTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ shard_config: ShardConfig = None,
+ ):
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+
+ if stage_manager.is_first_stage():
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+ if inputs_embeds is None:
+ inputs_embeds = self.embedding(input_ids)
+ if position_ids is None:
+ position_ids = get_position_ids(batch_size, seq_length, input_ids.device)
+ hidden_states = inputs_embeds
+ else:
+ assert hidden_states is not None, "hidden_states should not be None in non-first stage"
+ seq_length, batch_size, _ = hidden_states.shape
+ if position_ids is None:
+ position_ids = get_position_ids(batch_size, seq_length, hidden_states.device)
+
+ if infer_state.is_context_stage:
+ past_key_values_length = 0
+ else:
+ past_key_values_length = infer_state.max_len_in_batch - 1
+
+ seq_length_with_past = seq_length + past_key_values_length
+
+ # prefill stage at first
+ if seq_length != 1:
+ infer_state.is_context_stage = True
+ infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
+ infer_state.init_block_loc(
+ infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
+ )
+ else:
+ infer_state.is_context_stage = False
+ alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
+ if alloc_mem is not None:
+ infer_state.decode_is_contiguous = True
+ infer_state.decode_mem_index = alloc_mem[0]
+ infer_state.decode_mem_start = alloc_mem[1]
+ infer_state.decode_mem_end = alloc_mem[2]
+ infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
+ else:
+ print(f" *** Encountered allocation non-contiguous")
+ print(
+ f" infer_state.cache_manager.past_key_values_length: {infer_state.cache_manager.past_key_values_length}"
+ )
+ infer_state.decode_is_contiguous = False
+ alloc_mem = infer_state.cache_manager.alloc(batch_size)
+ infer_state.decode_mem_index = alloc_mem
+ infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
+
+ # related to rotary embedding
+ if infer_state.is_context_stage:
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
+ position_ids.view(-1).shape[0], -1
+ )
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
+ position_ids.view(-1).shape[0], -1
+ )
+ else:
+ seq_len = infer_state.seq_len
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
+ infer_state.other_kv_index = infer_state.block_loc[0, infer_state.max_len_in_batch - 1].item()
+
+ if self.pre_seq_len is not None:
+ if past_key_values is None:
+ past_key_values = self.get_prompt(
+ batch_size=batch_size,
+ device=input_ids.device,
+ dtype=inputs_embeds.dtype,
+ )
+ if attention_mask is not None:
+ attention_mask = torch.cat(
+ [
+ attention_mask.new_ones((batch_size, self.pre_seq_len)),
+ attention_mask,
+ ],
+ dim=-1,
+ )
+ if full_attention_mask is None:
+ if (attention_mask is not None and not attention_mask.all()) or (past_key_values and seq_length != 1):
+ full_attention_mask = get_masks(
+ self, input_ids, infer_state.cache_manager.past_key_values_length, padding_mask=attention_mask
+ )
+
+ # Run encoder.
+ hidden_states = self.encoder(
+ hidden_states,
+ full_attention_mask,
+ kv_caches=past_key_values,
+ use_cache=use_cache,
+ output_hidden_states=output_hidden_states,
+ infer_state=infer_state,
+ stage_manager=stage_manager,
+ stage_index=stage_index,
+ shard_config=shard_config,
+ )
+
+ # update indices
+ infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
+ infer_state.seq_len += 1
+ infer_state.max_len_in_batch += 1
+
+ return {"hidden_states": hidden_states}
+
+ @staticmethod
+ def chatglm_encoder_forward(
+ self: GLMTransformer,
+ hidden_states,
+ attention_mask,
+ kv_caches=None,
+ use_cache: Optional[bool] = True,
+ output_hidden_states: Optional[bool] = False,
+ infer_state: Optional[BatchInferState] = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ stage_index: Optional[List[int]] = None,
+ shard_config: ShardConfig = None,
+ ):
+ hidden_states = hidden_states.transpose(0, 1).contiguous()
+
+ infer_state.decode_layer_id = 0
+ start_idx, end_idx = stage_index[0], stage_index[1]
+ if kv_caches is None:
+ kv_caches = tuple([None] * (end_idx - start_idx + 1))
+
+ for idx, kv_cache in zip(range(start_idx, end_idx), kv_caches):
+ layer = self.layers[idx]
+ layer_ret = layer(
+ hidden_states,
+ attention_mask,
+ kv_cache=kv_cache,
+ use_cache=use_cache,
+ infer_state=infer_state,
+ )
+ infer_state.decode_layer_id += 1
+
+ hidden_states, _ = layer_ret
+
+ hidden_states = hidden_states.transpose(0, 1).contiguous()
+
+ if self.post_layer_norm and (stage_manager.is_last_stage() or stage_manager.num_stages == 1):
+ # Final layer norm.
+ hidden_states = self.final_layernorm(hidden_states)
+
+ return hidden_states
+
+ @staticmethod
+ def chatglm_glmblock_forward(
+ self: GLMBlock,
+ hidden_states,
+ attention_mask,
+ kv_cache=None,
+ use_cache=True,
+ infer_state: Optional[BatchInferState] = None,
+ ):
+ # hidden_states: [s, b, h]
+
+ # Layer norm at the beginning of the transformer layer.
+ layernorm_output = self.input_layernorm(hidden_states)
+ # Self attention.
+ attention_output, kv_cache = self.self_attention(
+ layernorm_output,
+ attention_mask,
+ kv_cache=kv_cache,
+ use_cache=use_cache,
+ infer_state=infer_state,
+ )
+ # Residual connection.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = hidden_states
+ layernorm_input = torch.nn.functional.dropout(attention_output, p=self.hidden_dropout, training=self.training)
+ layernorm_input = residual + layernorm_input
+ # Layer norm post the self attention.
+ layernorm_output = self.post_attention_layernorm(layernorm_input)
+ # MLP.
+ mlp_output = self.mlp(layernorm_output)
+
+ # Second residual connection.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = layernorm_input
+
+ output = torch.nn.functional.dropout(mlp_output, p=self.hidden_dropout, training=self.training)
+ output = residual + output
+ return output, kv_cache
+
+ @staticmethod
+ def chatglm_flash_attn_kvcache_forward(
+ self: SelfAttention,
+ hidden_states,
+ attention_mask,
+ kv_cache=None,
+ use_cache=True,
+ infer_state: Optional[BatchInferState] = None,
+ ):
+ assert use_cache is True, "use_cache should be set to True using this chatglm attention"
+ # hidden_states: original :[sq, b, h] --> this [b, sq, h]
+ batch_size = hidden_states.shape[0]
+ hidden_size = hidden_states.shape[-1]
+ # Attention heads [sq, b, h] --> [sq, b, (np * 3 * hn)]
+ mixed_x_layer = self.query_key_value(hidden_states)
+ if self.multi_query_attention:
+ (query_layer, key_layer, value_layer) = mixed_x_layer.split(
+ [
+ self.num_attention_heads_per_partition * self.hidden_size_per_attention_head,
+ self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
+ self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
+ ],
+ dim=-1,
+ )
+ query_layer = query_layer.view(
+ query_layer.size()[:-1]
+ + (
+ self.num_attention_heads_per_partition,
+ self.hidden_size_per_attention_head,
+ )
+ )
+ key_layer = key_layer.view(
+ key_layer.size()[:-1]
+ + (
+ self.num_multi_query_groups_per_partition,
+ self.hidden_size_per_attention_head,
+ )
+ )
+ value_layer = value_layer.view(
+ value_layer.size()[:-1]
+ + (
+ self.num_multi_query_groups_per_partition,
+ self.hidden_size_per_attention_head,
+ )
+ )
+
+ else:
+ new_tensor_shape = mixed_x_layer.size()[:-1] + (
+ self.num_attention_heads_per_partition,
+ 3 * self.hidden_size_per_attention_head,
+ )
+ mixed_x_layer = mixed_x_layer.view(*new_tensor_shape)
+ # [sq, b, np, 3 * hn] --> 3 [sq, b, np, hn]
+ (query_layer, key_layer, value_layer) = split_tensor_along_last_dim(mixed_x_layer, 3)
+ cos, sin = infer_state.position_cos, infer_state.position_sin
+
+ chatglm2_rotary_emb_fwd(
+ query_layer.view(-1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head), cos, sin
+ )
+ if self.multi_query_attention:
+ chatglm2_rotary_emb_fwd(
+ key_layer.view(-1, self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head),
+ cos,
+ sin,
+ )
+ else:
+ chatglm2_rotary_emb_fwd(
+ key_layer.view(-1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head),
+ cos,
+ sin,
+ )
+
+ # reshape q k v to [bsz*sql, num_heads, head_dim] 2*1 ,32/2 ,128
+ query_layer = query_layer.reshape(
+ -1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head
+ )
+ key_layer = key_layer.reshape(
+ -1, self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head
+ )
+ value_layer = value_layer.reshape(
+ -1, self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head
+ )
+
+ if infer_state.is_context_stage:
+ # first token generation:
+ # copy key and value calculated in current step to memory manager
+ copy_kv_to_mem_cache(
+ infer_state.decode_layer_id,
+ key_layer,
+ value_layer,
+ infer_state.context_mem_index,
+ infer_state.cache_manager,
+ )
+ attn_output = torch.empty_like(query_layer.contiguous().view(-1, self.projection_size))
+
+ # NOTE: no bug in context attn fwd (del it )
+ lightllm_llama2_context_attention_fwd(
+ query_layer,
+ key_layer,
+ value_layer,
+ attn_output.view(-1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head),
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+
+ else:
+ if infer_state.decode_is_contiguous:
+ # if decode is contiguous, then we copy to key cache and value cache in cache manager directly
+ cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_k.copy_(key_layer)
+ cache_v.copy_(value_layer)
+ else:
+ # if decode is not contiguous, use triton kernel to copy key and value cache
+ # k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head
+ copy_kv_to_mem_cache(
+ infer_state.decode_layer_id,
+ key_layer,
+ value_layer,
+ infer_state.decode_mem_index,
+ infer_state.cache_manager,
+ )
+
+ # second token and follows
+ attn_output = torch.empty_like(query_layer.contiguous().view(-1, self.projection_size))
+ cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
+ : infer_state.decode_mem_end, :, :
+ ]
+ cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
+ : infer_state.decode_mem_end, :, :
+ ]
+
+ # ==================================
+ # core attention computation is replaced by triton kernel
+ # ==================================
+ Llama2TokenAttentionForwards.token_attn(
+ query_layer,
+ cache_k,
+ cache_v,
+ attn_output,
+ infer_state.block_loc,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ infer_state.other_kv_index,
+ )
+
+ # =================
+ # Output:[b,sq, h]
+ # =================
+ output = self.dense(attn_output).reshape(batch_size, -1, hidden_size)
+
+ return output, kv_cache
diff --git a/colossalai/inference/engine/modeling/llama.py b/colossalai/inference/engine/modeling/llama.py
new file mode 100644
index 000000000000..a7efb4026be0
--- /dev/null
+++ b/colossalai/inference/engine/modeling/llama.py
@@ -0,0 +1,503 @@
+# This code is adapted from huggingface transformers: https://github.com/huggingface/transformers/blob/v4.34.1/src/transformers/models/llama/modeling_llama.py
+import math
+from typing import List, Optional, Tuple
+
+import torch
+from transformers.models.llama.modeling_llama import LlamaAttention, LlamaDecoderLayer, LlamaForCausalLM, LlamaModel
+from transformers.utils import logging
+
+from colossalai.inference.kv_cache.batch_infer_state import BatchInferState
+from colossalai.kernel.triton import llama_context_attn_fwd, token_attention_fwd
+from colossalai.kernel.triton.token_attention_kernel import Llama2TokenAttentionForwards
+from colossalai.pipeline.stage_manager import PipelineStageManager
+
+from ._utils import copy_kv_to_mem_cache
+
+try:
+ from lightllm.models.llama2.triton_kernel.context_flashattention_nopad import (
+ context_attention_fwd as lightllm_llama2_context_attention_fwd,
+ )
+ from lightllm.models.llama.triton_kernel.context_flashattention_nopad import (
+ context_attention_fwd as lightllm_context_attention_fwd,
+ )
+ from lightllm.models.llama.triton_kernel.rotary_emb import rotary_emb_fwd as llama_rotary_embedding_fwd
+
+ HAS_LIGHTLLM_KERNEL = True
+except:
+ print("please install lightllm from source to run inference: https://github.com/ModelTC/lightllm")
+ HAS_LIGHTLLM_KERNEL = False
+
+try:
+ from colossalai.kernel.triton.flash_decoding import token_flash_decoding
+
+ HAS_TRITON_FLASH_DECODING_KERNEL = True
+except:
+ print(
+ "no triton flash decoding support, please install lightllm from https://github.com/ModelTC/lightllm/blob/ece7b43f8a6dfa74027adc77c2c176cff28c76c8"
+ )
+ HAS_TRITON_FLASH_DECODING_KERNEL = False
+
+try:
+ from flash_attn import flash_attn_with_kvcache
+
+ HAS_FLASH_KERNEL = True
+except:
+ HAS_FLASH_KERNEL = False
+ print("please install flash attentiom from https://github.com/Dao-AILab/flash-attention")
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
+ # The first two dimensions of cos and sin are always 1, so we can `squeeze` them.
+ cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
+ sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
+ cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+ sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
+
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+def llama_triton_context_attention(
+ query_states, key_states, value_states, attn_output, infer_state, num_key_value_groups=1
+):
+ if num_key_value_groups == 1:
+ if HAS_LIGHTLLM_KERNEL is False:
+ llama_context_attn_fwd(
+ query_states,
+ key_states,
+ value_states,
+ attn_output,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+ else:
+ lightllm_context_attention_fwd(
+ query_states,
+ key_states,
+ value_states,
+ attn_output,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+ else:
+ assert HAS_LIGHTLLM_KERNEL is True, "You have to install lightllm kernels to run llama2 model"
+ lightllm_llama2_context_attention_fwd(
+ query_states,
+ key_states,
+ value_states,
+ attn_output,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+
+
+def llama_triton_token_attention(
+ query_states, attn_output, infer_state, num_key_value_groups=1, q_head_num=-1, head_dim=-1
+):
+ if HAS_TRITON_FLASH_DECODING_KERNEL and q_head_num != -1 and head_dim != -1:
+ token_flash_decoding(
+ q=query_states,
+ o_tensor=attn_output,
+ infer_state=infer_state,
+ q_head_num=q_head_num,
+ head_dim=head_dim,
+ cache_k=infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
+ cache_v=infer_state.cache_manager.value_buffer[infer_state.decode_layer_id],
+ )
+ return
+
+ if num_key_value_groups == 1:
+ token_attention_fwd(
+ query_states,
+ infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
+ infer_state.cache_manager.value_buffer[infer_state.decode_layer_id],
+ attn_output,
+ infer_state.block_loc,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ )
+ else:
+ Llama2TokenAttentionForwards.token_attn(
+ query_states,
+ infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
+ infer_state.cache_manager.value_buffer[infer_state.decode_layer_id],
+ attn_output,
+ infer_state.block_loc,
+ infer_state.start_loc,
+ infer_state.seq_len,
+ infer_state.max_len_in_batch,
+ infer_state.other_kv_index,
+ )
+
+
+class LlamaInferenceForwards:
+ """
+ This class holds forwards for llama inference.
+ We intend to replace the forward methods for LlamaModel, LlamaDecoderLayer, and LlamaAttention for LlamaForCausalLM.
+ """
+
+ @staticmethod
+ def llama_causal_lm_forward(
+ self: LlamaForCausalLM,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ """
+ logger = logging.get_logger(__name__)
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if output_attentions:
+ logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
+ output_attentions = False
+ if output_hidden_states:
+ logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
+ output_hidden_states = False
+
+ # If is first stage and hidden_states is None, go throught lm_head first
+ if stage_manager.is_first_stage() and hidden_states is not None:
+ lm_logits = self.lm_head(hidden_states)
+ return {"logits": lm_logits}
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = LlamaInferenceForwards.llama_model_forward(
+ self.model,
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ infer_state=infer_state,
+ stage_manager=stage_manager,
+ hidden_states=hidden_states,
+ stage_index=stage_index,
+ )
+
+ return outputs
+
+ @staticmethod
+ def llama_model_forward(
+ self: LlamaModel,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ infer_state: BatchInferState = None,
+ stage_manager: Optional[PipelineStageManager] = None,
+ hidden_states: Optional[torch.FloatTensor] = None,
+ stage_index: Optional[List[int]] = None,
+ ):
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ # retrieve input_ids and inputs_embeds
+ if stage_manager is None or stage_manager.is_first_stage():
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+ hidden_states = inputs_embeds
+ else:
+ assert stage_manager is not None
+ assert hidden_states is not None, f"hidden_state should not be none in stage {stage_manager.stage}"
+ input_shape = hidden_states.shape[:-1]
+ batch_size, seq_length = input_shape
+ device = hidden_states.device
+
+ if infer_state.is_context_stage:
+ past_key_values_length = 0
+ else:
+ past_key_values_length = infer_state.max_len_in_batch - 1
+
+ # NOTE: differentiate with prefill stage
+ # block_loc require different value-assigning method for two different stage
+ if use_cache and seq_length != 1:
+ # NOTE assume prefill stage
+ # allocate memory block
+ infer_state.is_context_stage = True # set prefill stage, notify attention layer
+ infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
+ infer_state.init_block_loc(
+ infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
+ )
+ else:
+ infer_state.is_context_stage = False
+ alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
+ if alloc_mem is not None:
+ infer_state.decode_is_contiguous = True
+ infer_state.decode_mem_index = alloc_mem[0]
+ infer_state.decode_mem_start = alloc_mem[1]
+ infer_state.decode_mem_end = alloc_mem[2]
+ infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
+ else:
+ infer_state.decode_is_contiguous = False
+ alloc_mem = infer_state.cache_manager.alloc(batch_size)
+ infer_state.decode_mem_index = alloc_mem
+ infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
+
+ if position_ids is None:
+ position_ids = torch.arange(
+ past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
+ )
+ position_ids = position_ids.repeat(batch_size, 1)
+ position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
+ else:
+ position_ids = position_ids.view(-1, seq_length).long()
+
+ if infer_state.is_context_stage:
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
+ position_ids.view(-1).shape[0], -1
+ )
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
+ position_ids.view(-1).shape[0], -1
+ )
+
+ else:
+ seq_len = infer_state.seq_len
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
+ infer_state.other_kv_index = infer_state.block_loc[0, infer_state.max_len_in_batch - 1].item()
+
+ # embed positions
+ if attention_mask is None:
+ attention_mask = torch.ones(
+ (batch_size, infer_state.max_len_in_batch), dtype=torch.bool, device=hidden_states.device
+ )
+
+ attention_mask = self._prepare_decoder_attention_mask(
+ attention_mask, (batch_size, seq_length), hidden_states, past_key_values_length
+ )
+
+ # decoder layers
+ infer_state.decode_layer_id = 0
+
+ start_idx, end_idx = stage_index[0], stage_index[1]
+ if past_key_values is None:
+ past_key_values = tuple([None] * (end_idx - start_idx + 1))
+
+ for idx, past_key_value in zip(range(start_idx, end_idx), past_key_values):
+ decoder_layer = self.layers[idx]
+ # NOTE: modify here for passing args to decoder layer
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ infer_state=infer_state,
+ )
+ infer_state.decode_layer_id += 1
+ hidden_states = layer_outputs[0]
+
+ if stage_manager.is_last_stage() or stage_manager.num_stages == 1:
+ hidden_states = self.norm(hidden_states)
+
+ # update indices
+ # infer_state.block_loc[:, infer_state.max_len_in_batch-1] = infer_state.total_token_num + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
+ infer_state.start_loc += torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
+ infer_state.seq_len += 1
+ infer_state.max_len_in_batch += 1
+
+ return {"hidden_states": hidden_states}
+
+ @staticmethod
+ def llama_decoder_layer_forward(
+ self: LlamaDecoderLayer,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ infer_state: Optional[BatchInferState] = None,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ infer_state=infer_state,
+ )
+
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+ @staticmethod
+ def llama_flash_attn_kvcache_forward(
+ self: LlamaAttention,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ infer_state: Optional[BatchInferState] = None,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ assert use_cache is True, "use_cache should be set to True using this llama attention"
+
+ bsz, q_len, _ = hidden_states.size()
+
+ # NOTE might think about better way to handle transposed k and v
+ # key_states [bs, seq_len, num_heads, head_dim/embed_size_per_head]
+ # key_states_transposed [bs, num_heads, seq_len, head_dim/embed_size_per_head]
+
+ query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim)
+ key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_key_value_heads, self.head_dim)
+ value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_key_value_heads, self.head_dim)
+
+ # NOTE might want to revise
+ # need some way to record the length of past key values cache
+ # since we won't return past_key_value_cache right now
+
+ cos, sin = infer_state.position_cos, infer_state.position_sin
+
+ llama_rotary_embedding_fwd(query_states.view(-1, self.num_heads, self.head_dim), cos, sin)
+ llama_rotary_embedding_fwd(key_states.view(-1, self.num_key_value_heads, self.head_dim), cos, sin)
+
+ query_states = query_states.reshape(-1, self.num_heads, self.head_dim)
+ key_states = key_states.reshape(-1, self.num_key_value_heads, self.head_dim)
+ value_states = value_states.reshape(-1, self.num_key_value_heads, self.head_dim)
+
+ if infer_state.is_context_stage:
+ # first token generation
+ # copy key and value calculated in current step to memory manager
+ copy_kv_to_mem_cache(
+ infer_state.decode_layer_id,
+ key_states,
+ value_states,
+ infer_state.context_mem_index,
+ infer_state.cache_manager,
+ )
+ attn_output = torch.empty_like(query_states)
+
+ llama_triton_context_attention(
+ query_states,
+ key_states,
+ value_states,
+ attn_output,
+ infer_state,
+ num_key_value_groups=self.num_key_value_groups,
+ )
+ else:
+ if infer_state.decode_is_contiguous:
+ # if decode is contiguous, then we copy to key cache and value cache in cache manager directly
+ cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
+ infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
+ ]
+ cache_k.copy_(key_states)
+ cache_v.copy_(value_states)
+ else:
+ # if decode is not contiguous, use triton kernel to copy key and value cache
+ # k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head
+ copy_kv_to_mem_cache(
+ infer_state.decode_layer_id,
+ key_states,
+ value_states,
+ infer_state.decode_mem_index,
+ infer_state.cache_manager,
+ )
+
+ if HAS_LIGHTLLM_KERNEL:
+ attn_output = torch.empty_like(query_states)
+ llama_triton_token_attention(
+ query_states=query_states,
+ attn_output=attn_output,
+ infer_state=infer_state,
+ num_key_value_groups=self.num_key_value_groups,
+ q_head_num=q_len * self.num_heads,
+ head_dim=self.head_dim,
+ )
+ else:
+ self.num_heads // self.num_key_value_heads
+ cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id]
+ cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id]
+
+ query_states = query_states.view(bsz, -1, self.num_heads, self.head_dim)
+ copy_cache_k = cache_k.view(bsz, -1, self.num_key_value_heads, self.head_dim)
+ copy_cache_v = cache_v.view(bsz, -1, self.num_key_value_heads, self.head_dim)
+
+ attn_output = flash_attn_with_kvcache(
+ q=query_states,
+ k_cache=copy_cache_k,
+ v_cache=copy_cache_v,
+ softmax_scale=1 / math.sqrt(self.head_dim),
+ causal=True,
+ )
+
+ attn_output = attn_output.view(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ # return past_key_value as None
+ return attn_output, None, None
diff --git a/colossalai/inference/engine/policies/__init__.py b/colossalai/inference/engine/policies/__init__.py
new file mode 100644
index 000000000000..269d1c57b276
--- /dev/null
+++ b/colossalai/inference/engine/policies/__init__.py
@@ -0,0 +1,11 @@
+from .bloom import BloomModelInferPolicy
+from .chatglm2 import ChatGLM2InferPolicy
+from .llama import LlamaModelInferPolicy
+
+model_policy_map = {
+ "llama": LlamaModelInferPolicy,
+ "bloom": BloomModelInferPolicy,
+ "chatglm": ChatGLM2InferPolicy,
+}
+
+__all__ = ["LlamaModelInferPolicy", "BloomModelInferPolicy", "ChatGLM2InferPolicy", "model_polic_map"]
diff --git a/colossalai/inference/engine/policies/bloom.py b/colossalai/inference/engine/policies/bloom.py
new file mode 100644
index 000000000000..5bc47c3c1a49
--- /dev/null
+++ b/colossalai/inference/engine/policies/bloom.py
@@ -0,0 +1,127 @@
+from functools import partial
+from typing import List
+
+import torch
+from torch.nn import LayerNorm, Module
+
+import colossalai.shardformer.layer as col_nn
+from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
+from colossalai.shardformer.policies.bloom import BloomForCausalLMPolicy
+
+from ..modeling.bloom import BloomInferenceForwards
+
+try:
+ from colossalai.kernel.triton import layer_norm
+
+ HAS_TRITON_NORM = True
+except:
+ print("Some of our kernels require triton. You might want to install triton from https://github.com/openai/triton")
+ HAS_TRITON_NORM = False
+
+
+def get_triton_layernorm_forward():
+ if HAS_TRITON_NORM:
+
+ def _triton_layernorm_forward(self: LayerNorm, hidden_states: torch.Tensor):
+ return layer_norm(hidden_states, self.weight.data, self.bias, self.eps)
+
+ return _triton_layernorm_forward
+ else:
+ return None
+
+
+class BloomModelInferPolicy(BloomForCausalLMPolicy):
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ from transformers.models.bloom.modeling_bloom import BloomAttention, BloomBlock, BloomForCausalLM, BloomModel
+
+ policy = super().module_policy()
+ if self.shard_config.extra_kwargs.get("quant", None) == "gptq":
+ from colossalai.inference.quant.gptq.cai_gptq import ColCaiQuantLinear, RowCaiQuantLinear
+
+ policy[BloomBlock] = ModulePolicyDescription(
+ attribute_replacement={
+ "self_attention.hidden_size": self.model.config.hidden_size
+ // self.shard_config.tensor_parallel_size,
+ "self_attention.split_size": self.model.config.hidden_size
+ // self.shard_config.tensor_parallel_size,
+ "self_attention.num_heads": self.model.config.n_head // self.shard_config.tensor_parallel_size,
+ },
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attention.query_key_value",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 3},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attention.dense", target_module=RowCaiQuantLinear, kwargs={"split_num": 1}
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attention.attention_dropout",
+ target_module=col_nn.DropoutForParallelInput,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.dense_h_to_4h", target_module=ColCaiQuantLinear, kwargs={"split_num": 1}
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.dense_4h_to_h", target_module=RowCaiQuantLinear, kwargs={"split_num": 1}
+ ),
+ ],
+ )
+ # NOTE set inference mode to shard config
+ self.shard_config._infer()
+
+ # set as default, in inference we also use pipeline style forward, just setting stage as 1
+ self.set_pipeline_forward(
+ model_cls=BloomForCausalLM,
+ new_forward=partial(
+ BloomInferenceForwards.bloom_for_causal_lm_forward,
+ tp_group=self.shard_config.tensor_parallel_process_group,
+ ),
+ policy=policy,
+ )
+
+ method_replacement = {"forward": BloomInferenceForwards.bloom_model_forward}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=BloomModel)
+
+ method_replacement = {"forward": BloomInferenceForwards.bloom_block_forward}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=BloomBlock)
+
+ method_replacement = {"forward": BloomInferenceForwards.bloom_attention_forward}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=BloomAttention
+ )
+
+ if HAS_TRITON_NORM:
+ infer_method = get_triton_layernorm_forward()
+ method_replacement = {"forward": partial(infer_method)}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=LayerNorm
+ )
+
+ return policy
+
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ assert self.pipeline_stage_manager is not None
+
+ if self.model.__class__.__name__ == "BloomModel":
+ module = self.model
+ else:
+ module = self.model.transformer
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = stage_manager.distribute_layers(len(module.h))
+ if stage_manager.is_first_stage():
+ held_layers.append(module.word_embeddings)
+ held_layers.append(module.word_embeddings_layernorm)
+ held_layers.append(self.model.lm_head)
+ start_idx, end_idx = stage_manager.get_stage_index(layers_per_stage)
+ held_layers.extend(module.h[start_idx:end_idx])
+ if stage_manager.is_last_stage():
+ held_layers.append(module.ln_f)
+
+ return held_layers
diff --git a/colossalai/inference/engine/policies/chatglm2.py b/colossalai/inference/engine/policies/chatglm2.py
new file mode 100644
index 000000000000..c7c6f3b927e1
--- /dev/null
+++ b/colossalai/inference/engine/policies/chatglm2.py
@@ -0,0 +1,89 @@
+from typing import List
+
+import torch.nn as nn
+
+from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import (
+ ChatGLMForConditionalGeneration,
+ ChatGLMModel,
+ GLMBlock,
+ GLMTransformer,
+ SelfAttention,
+)
+
+# import colossalai
+from colossalai.shardformer.policies.chatglm2 import ChatGLMModelPolicy
+
+from ..modeling._utils import init_to_get_rotary
+from ..modeling.chatglm2 import ChatGLM2InferenceForwards
+
+try:
+ HAS_TRITON_RMSNORM = True
+except:
+ print("you should install triton from https://github.com/openai/triton")
+ HAS_TRITON_RMSNORM = False
+
+
+class ChatGLM2InferPolicy(ChatGLMModelPolicy):
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ policy = super().module_policy()
+ self.shard_config._infer()
+
+ model_infer_forward = ChatGLM2InferenceForwards.chatglm_model_forward
+ method_replacement = {"forward": model_infer_forward}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=ChatGLMModel)
+
+ encoder_infer_forward = ChatGLM2InferenceForwards.chatglm_encoder_forward
+ method_replacement = {"forward": encoder_infer_forward}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=GLMTransformer
+ )
+
+ encoder_layer_infer_forward = ChatGLM2InferenceForwards.chatglm_glmblock_forward
+ method_replacement = {"forward": encoder_layer_infer_forward}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=GLMBlock)
+
+ attn_infer_forward = ChatGLM2InferenceForwards.chatglm_flash_attn_kvcache_forward
+ method_replacement = {"forward": attn_infer_forward}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=SelfAttention
+ )
+ if self.shard_config.enable_tensor_parallelism:
+ policy[GLMBlock].attribute_replacement["self_attention.num_multi_query_groups_per_partition"] = (
+ self.model.config.multi_query_group_num // self.shard_config.tensor_parallel_size
+ )
+ # for rmsnorm and others, we need to check the shape
+
+ self.set_pipeline_forward(
+ model_cls=ChatGLMForConditionalGeneration,
+ new_forward=ChatGLM2InferenceForwards.chatglm_for_conditional_generation_forward,
+ policy=policy,
+ )
+
+ return policy
+
+ def get_held_layers(self) -> List[nn.Module]:
+ module = self.model.transformer
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = stage_manager.distribute_layers(module.num_layers)
+ if stage_manager.is_first_stage():
+ held_layers.append(module.embedding)
+ held_layers.append(module.output_layer)
+ start_idx, end_idx = stage_manager.get_stage_index(layers_per_stage)
+ held_layers.extend(module.encoder.layers[start_idx:end_idx])
+ if stage_manager.is_last_stage():
+ if module.encoder.post_layer_norm:
+ held_layers.append(module.encoder.final_layernorm)
+
+ # rotary_pos_emb is needed for all stages
+ held_layers.append(module.rotary_pos_emb)
+
+ return held_layers
+
+ def postprocess(self):
+ init_to_get_rotary(self.model.transformer)
+ return self.model
diff --git a/colossalai/inference/engine/policies/llama.py b/colossalai/inference/engine/policies/llama.py
new file mode 100644
index 000000000000..a57a4e50cdb9
--- /dev/null
+++ b/colossalai/inference/engine/policies/llama.py
@@ -0,0 +1,206 @@
+from functools import partial
+from typing import List
+
+import torch
+from torch.nn import Module
+from transformers.models.llama.modeling_llama import (
+ LlamaAttention,
+ LlamaDecoderLayer,
+ LlamaForCausalLM,
+ LlamaModel,
+ LlamaRMSNorm,
+)
+
+from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
+
+# import colossalai
+from colossalai.shardformer.policies.llama import LlamaForCausalLMPolicy
+
+from ..modeling._utils import init_to_get_rotary
+from ..modeling.llama import LlamaInferenceForwards
+
+try:
+ from colossalai.kernel.triton import rmsnorm_forward
+
+ HAS_TRITON_RMSNORM = True
+except:
+ print("you should install triton from https://github.com/openai/triton")
+ HAS_TRITON_RMSNORM = False
+
+
+def get_triton_rmsnorm_forward():
+ if HAS_TRITON_RMSNORM:
+
+ def _triton_rmsnorm_forward(self: LlamaRMSNorm, hidden_states: torch.Tensor):
+ return rmsnorm_forward(hidden_states, self.weight.data, self.variance_epsilon)
+
+ return _triton_rmsnorm_forward
+ else:
+ return None
+
+
+class LlamaModelInferPolicy(LlamaForCausalLMPolicy):
+ def __init__(self) -> None:
+ super().__init__()
+
+ def module_policy(self):
+ policy = super().module_policy()
+ decoder_attribute_replacement = {
+ "self_attn.hidden_size": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
+ "self_attn.num_heads": self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
+ "self_attn.num_key_value_heads": self.model.config.num_key_value_heads
+ // self.shard_config.tensor_parallel_size,
+ }
+ if self.shard_config.extra_kwargs.get("quant", None) == "gptq":
+ from colossalai.inference.quant.gptq.cai_gptq import ColCaiQuantLinear, RowCaiQuantLinear
+
+ policy[LlamaDecoderLayer] = ModulePolicyDescription(
+ attribute_replacement=decoder_attribute_replacement,
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attn.q_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.k_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.v_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.o_proj",
+ target_module=RowCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.gate_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.up_proj",
+ target_module=ColCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.down_proj",
+ target_module=RowCaiQuantLinear,
+ kwargs={"split_num": 1},
+ ),
+ ],
+ )
+
+ elif self.shard_config.extra_kwargs.get("quant", None) == "smoothquant":
+ from colossalai.inference.quant.smoothquant.models.llama import LlamaSmoothquantDecoderLayer
+ from colossalai.inference.quant.smoothquant.models.parallel_linear import (
+ ColW8A8BFP32OFP32Linear,
+ RowW8A8B8O8Linear,
+ RowW8A8BFP32O32LinearSiLU,
+ RowW8A8BFP32OFP32Linear,
+ )
+
+ policy[LlamaSmoothquantDecoderLayer] = ModulePolicyDescription(
+ attribute_replacement=decoder_attribute_replacement,
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="self_attn.q_proj",
+ target_module=RowW8A8B8O8Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.k_proj",
+ target_module=RowW8A8B8O8Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.v_proj",
+ target_module=RowW8A8B8O8Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="self_attn.o_proj",
+ target_module=ColW8A8BFP32OFP32Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.gate_proj",
+ target_module=RowW8A8BFP32O32LinearSiLU,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.up_proj",
+ target_module=RowW8A8BFP32OFP32Linear,
+ kwargs={"split_num": 1},
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.down_proj",
+ target_module=ColW8A8BFP32OFP32Linear,
+ kwargs={"split_num": 1},
+ ),
+ ],
+ )
+ self.shard_config._infer()
+
+ infer_forward = LlamaInferenceForwards.llama_model_forward
+ method_replacement = {"forward": partial(infer_forward)}
+ self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=LlamaModel)
+
+ infer_forward = LlamaInferenceForwards.llama_decoder_layer_forward
+ method_replacement = {"forward": partial(infer_forward)}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=LlamaDecoderLayer
+ )
+
+ infer_forward = LlamaInferenceForwards.llama_flash_attn_kvcache_forward
+ method_replacement = {"forward": partial(infer_forward)}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=LlamaAttention
+ )
+
+ # set as default, in inference we also use pipeline style forward, just setting stage as 1
+ self.set_pipeline_forward(
+ model_cls=LlamaForCausalLM, new_forward=LlamaInferenceForwards.llama_causal_lm_forward, policy=policy
+ )
+
+ infer_forward = None
+ if HAS_TRITON_RMSNORM:
+ infer_forward = get_triton_rmsnorm_forward()
+
+ if infer_forward is not None:
+ method_replacement = {"forward": partial(infer_forward)}
+ self.append_or_create_method_replacement(
+ description=method_replacement, policy=policy, target_key=LlamaRMSNorm
+ )
+
+ return policy
+
+ def postprocess(self):
+ init_to_get_rotary(self.model.model)
+ return self.model
+
+ def get_held_layers(self) -> List[Module]:
+ """Get pipeline layers for current stage."""
+ assert self.pipeline_stage_manager is not None
+
+ if self.model.__class__.__name__ == "LlamaModel":
+ module = self.model
+ else:
+ module = self.model.model
+ stage_manager = self.pipeline_stage_manager
+
+ held_layers = []
+ layers_per_stage = stage_manager.distribute_layers(len(module.layers))
+ if stage_manager.is_first_stage():
+ held_layers.append(module.embed_tokens)
+ held_layers.append(self.model.lm_head)
+ start_idx, end_idx = stage_manager.get_stage_index(layers_per_stage)
+ held_layers.extend(module.layers[start_idx:end_idx])
+ if stage_manager.is_last_stage():
+ held_layers.append(module.norm)
+
+ return held_layers
diff --git a/colossalai/inference/kv_cache/__init__.py b/colossalai/inference/kv_cache/__init__.py
new file mode 100644
index 000000000000..5b6ca182efae
--- /dev/null
+++ b/colossalai/inference/kv_cache/__init__.py
@@ -0,0 +1,2 @@
+from .batch_infer_state import BatchInferState
+from .kvcache_manager import MemoryManager
diff --git a/colossalai/inference/kv_cache/batch_infer_state.py b/colossalai/inference/kv_cache/batch_infer_state.py
new file mode 100644
index 000000000000..f707a86df37e
--- /dev/null
+++ b/colossalai/inference/kv_cache/batch_infer_state.py
@@ -0,0 +1,118 @@
+# might want to consider combine with InferenceConfig in colossalai/ppinference/inference_config.py later
+from dataclasses import dataclass
+
+import torch
+from transformers.tokenization_utils_base import BatchEncoding
+
+from .kvcache_manager import MemoryManager
+
+
+# adapted from: lightllm/server/router/model_infer/infer_batch.py
+@dataclass
+class BatchInferState:
+ r"""
+ Information to be passed and used for a batch of inputs during
+ a single model forward
+ """
+ batch_size: int
+ max_len_in_batch: int
+
+ cache_manager: MemoryManager = None
+
+ block_loc: torch.Tensor = None
+ start_loc: torch.Tensor = None
+ seq_len: torch.Tensor = None
+ past_key_values_len: int = None
+
+ is_context_stage: bool = False
+ context_mem_index: torch.Tensor = None
+ decode_is_contiguous: bool = None
+ decode_mem_start: int = None
+ decode_mem_end: int = None
+ decode_mem_index: torch.Tensor = None
+ decode_layer_id: int = None
+
+ device: torch.device = torch.device("cuda")
+
+ @property
+ def total_token_num(self):
+ # return self.batch_size * self.max_len_in_batch
+ assert self.seq_len is not None and self.seq_len.size(0) > 0
+ return int(torch.sum(self.seq_len))
+
+ def set_cache_manager(self, manager: MemoryManager):
+ self.cache_manager = manager
+
+ # adapted from: https://github.com/ModelTC/lightllm/blob/28c1267cfca536b7b4f28e921e03de735b003039/lightllm/common/infer_utils.py#L1
+ @staticmethod
+ def init_block_loc(
+ b_loc: torch.Tensor, seq_len: torch.Tensor, max_len_in_batch: int, alloc_mem_index: torch.Tensor
+ ):
+ """in-place update block loc mapping based on the sequence length of the inputs in current bath"""
+ start_index = 0
+ seq_len_numpy = seq_len.cpu().numpy()
+ for i, cur_seq_len in enumerate(seq_len_numpy):
+ b_loc[i, max_len_in_batch - cur_seq_len : max_len_in_batch] = alloc_mem_index[
+ start_index : start_index + cur_seq_len
+ ]
+ start_index += cur_seq_len
+ return
+
+ @classmethod
+ def init_from_batch(
+ cls,
+ batch: torch.Tensor,
+ max_input_len: int,
+ max_output_len: int,
+ cache_manager: MemoryManager,
+ ):
+ if not isinstance(batch, (BatchEncoding, dict, list, torch.Tensor)):
+ raise TypeError(f"batch type {type(batch)} is not supported in prepare_batch_state")
+
+ input_ids_list = None
+ attention_mask = None
+
+ if isinstance(batch, (BatchEncoding, dict)):
+ input_ids_list = batch["input_ids"]
+ attention_mask = batch["attention_mask"]
+ else:
+ input_ids_list = batch
+ if isinstance(input_ids_list[0], int): # for a single input
+ input_ids_list = [input_ids_list]
+ attention_mask = [attention_mask] if attention_mask is not None else attention_mask
+
+ batch_size = len(input_ids_list)
+
+ seq_start_indexes = torch.zeros(batch_size, dtype=torch.int32, device="cuda")
+ seq_lengths = torch.zeros(batch_size, dtype=torch.int32, device="cuda")
+ start_index = 0
+
+ max_len_in_batch = -1
+ if isinstance(batch, (BatchEncoding, dict)):
+ for i, attn_mask in enumerate(attention_mask):
+ curr_seq_len = len(attn_mask)
+ seq_lengths[i] = curr_seq_len
+ seq_start_indexes[i] = start_index
+ start_index += curr_seq_len
+ max_len_in_batch = curr_seq_len if curr_seq_len > max_len_in_batch else max_len_in_batch
+ else:
+ length = max(len(input_id) for input_id in input_ids_list)
+ for i, input_ids in enumerate(input_ids_list):
+ curr_seq_len = length
+ seq_lengths[i] = curr_seq_len
+ seq_start_indexes[i] = start_index
+ start_index += curr_seq_len
+ max_len_in_batch = curr_seq_len if curr_seq_len > max_len_in_batch else max_len_in_batch
+ block_loc = torch.zeros((batch_size, max_input_len + max_output_len), dtype=torch.long, device="cuda")
+
+ return cls(
+ batch_size=batch_size,
+ max_len_in_batch=max_len_in_batch,
+ seq_len=seq_lengths.to("cuda"),
+ start_loc=seq_start_indexes.to("cuda"),
+ block_loc=block_loc,
+ decode_layer_id=0,
+ past_key_values_len=0,
+ is_context_stage=True,
+ cache_manager=cache_manager,
+ )
diff --git a/colossalai/inference/kv_cache/kvcache_manager.py b/colossalai/inference/kv_cache/kvcache_manager.py
new file mode 100644
index 000000000000..dda46a756cc3
--- /dev/null
+++ b/colossalai/inference/kv_cache/kvcache_manager.py
@@ -0,0 +1,106 @@
+"""
+Refered/Modified from lightllm/common/mem_manager.py
+of the ModelTC/lightllm GitHub repository
+https://github.com/ModelTC/lightllm/blob/050af3ce65edca617e2f30ec2479397d5bb248c9/lightllm/common/mem_manager.py
+we slightly changed it to make it suitable for our colossal-ai shardformer TP-engine design.
+"""
+import torch
+from transformers.utils import logging
+
+
+class MemoryManager:
+ r"""
+ Manage token block indexes and allocate physical memory for key and value cache
+
+ Args:
+ size: maximum token number used as the size of key and value buffer
+ dtype: data type of cached key and value
+ head_num: number of heads the memory manager is responsible for
+ head_dim: embedded size per head
+ layer_num: the number of layers in the model
+ device: device used to store the key and value cache
+ """
+
+ def __init__(
+ self,
+ size: int,
+ dtype: torch.dtype,
+ head_num: int,
+ head_dim: int,
+ layer_num: int,
+ device: torch.device = torch.device("cuda"),
+ ):
+ self.logger = logging.get_logger(__name__)
+ self.available_size = size
+ self.max_len_in_batch = 0
+ self._init_mem_states(size, device)
+ self._init_kv_buffers(size, device, dtype, head_num, head_dim, layer_num)
+
+ def _init_mem_states(self, size, device):
+ """Initialize tensors used to manage memory states"""
+ self.mem_state = torch.ones((size,), dtype=torch.bool, device=device)
+ self.mem_cum_sum = torch.empty((size,), dtype=torch.int32, device=device)
+ self.indexes = torch.arange(0, size, dtype=torch.long, device=device)
+
+ def _init_kv_buffers(self, size, device, dtype, head_num, head_dim, layer_num):
+ """Initialize key buffer and value buffer on specified device"""
+ self.key_buffer = [
+ torch.empty((size, head_num, head_dim), dtype=dtype, device=device) for _ in range(layer_num)
+ ]
+ self.value_buffer = [
+ torch.empty((size, head_num, head_dim), dtype=dtype, device=device) for _ in range(layer_num)
+ ]
+
+ @torch.no_grad()
+ def alloc(self, required_size):
+ """allocate space of required_size by providing indexes representing available physical spaces"""
+ if required_size > self.available_size:
+ self.logger.warning(f"No enough cache: required_size {required_size} " f"left_size {self.available_size}")
+ return None
+ torch.cumsum(self.mem_state, dim=0, dtype=torch.int32, out=self.mem_cum_sum)
+ select_index = torch.logical_and(self.mem_cum_sum <= required_size, self.mem_state == 1)
+ select_index = self.indexes[select_index]
+ self.mem_state[select_index] = 0
+ self.available_size -= len(select_index)
+ return select_index
+
+ @torch.no_grad()
+ def alloc_contiguous(self, required_size):
+ """allocate contiguous space of required_size"""
+ if required_size > self.available_size:
+ self.logger.warning(f"No enough cache: required_size {required_size} " f"left_size {self.available_size}")
+ return None
+ torch.cumsum(self.mem_state, dim=0, dtype=torch.int32, out=self.mem_cum_sum)
+ sum_size = len(self.mem_cum_sum)
+ loc_sums = (
+ self.mem_cum_sum[required_size - 1 :]
+ - self.mem_cum_sum[0 : sum_size - required_size + 1]
+ + self.mem_state[0 : sum_size - required_size + 1]
+ )
+ can_used_loc = self.indexes[0 : sum_size - required_size + 1][loc_sums == required_size]
+ if can_used_loc.shape[0] == 0:
+ self.logger.info(
+ f"No enough contiguous cache: required_size {required_size} " f"left_size {self.available_size}"
+ )
+ return None
+ start_loc = can_used_loc[0]
+ select_index = self.indexes[start_loc : start_loc + required_size]
+ self.mem_state[select_index] = 0
+ self.available_size -= len(select_index)
+ start = start_loc.item()
+ end = start + required_size
+ return select_index, start, end
+
+ @torch.no_grad()
+ def free(self, free_index):
+ """free memory by updating memory states based on given indexes"""
+ self.available_size += free_index.shape[0]
+ self.mem_state[free_index] = 1
+
+ @torch.no_grad()
+ def free_all(self):
+ """free all memory by updating memory states"""
+ self.available_size = len(self.mem_state)
+ self.mem_state[:] = 1
+ self.max_len_in_batch = 0
+ # self.logger.info("freed all space of memory manager")
diff --git a/colossalai/inference/pipeline/__init__.py b/colossalai/inference/pipeline/__init__.py
deleted file mode 100644
index 41af9f3ef948..000000000000
--- a/colossalai/inference/pipeline/__init__.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from .engine import PPInferEngine
-
-__all__ = ["PPInferEngine"]
diff --git a/colossalai/inference/pipeline/engine.py b/colossalai/inference/pipeline/engine.py
deleted file mode 100644
index 4f42385caf8f..000000000000
--- a/colossalai/inference/pipeline/engine.py
+++ /dev/null
@@ -1,97 +0,0 @@
-import torch
-import torch.nn as nn
-
-from colossalai.cluster import ProcessGroupMesh
-from colossalai.pipeline.schedule.generate import GenerateSchedule
-from colossalai.pipeline.stage_manager import PipelineStageManager
-from colossalai.shardformer import ShardConfig, ShardFormer
-from colossalai.shardformer.policies.base_policy import Policy
-
-from .microbatch_manager import MicroBatchManager
-
-
-class PPInferEngine:
- """
- PPInferEngine is a class that handles the pipeline parallel inference.
-
- Args:
- pp_size (int): the number of pipeline stages.
- pp_model (`nn.Module`): the model already in pipeline parallelism style.
- model (`nn.Module`): the model not in pipeline style, and will be modified with `ShardFormer`.
- model_policy (`colossalai.shardformer.policies.base_policy.Policy`): the policy to shardformer model.
- micro_batch_size (int): the micro batch size.
- micro_batch_buffer_size (int): the buffer size for micro batch. Normally, it should be the same as the number of pipeline stages.
- new_length (int): the new length of the input sequence.
- early_stopping (bool): whether to stop early.
-
- Example:
-
- ```python
- from colossalai.ppinference import PPInferEngine
- from transformers import GPT2LMHeadModel, GPT2Tokenizer
-
- model = transformers.GPT2LMHeadModel.from_pretrained('gpt2')
- # assume the model is infered with 4 pipeline stages
- inferengine = PPInferEngine(pp_size=4, model=model, model_policy={Your own policy for pipeline sharding})
-
- input = ["Hello, my dog is cute, and I like"]
- tokenized_input = tokenizer(input, return_tensors='pt')
- output = engine.inference([tokenized_input])
- ```
-
- """
-
- def __init__(
- self,
- pp_size: int,
- dtype: str = "fp16",
- pp_model: nn.Module = None,
- model: nn.Module = None,
- model_policy: Policy = None,
- new_length: int = 32,
- micro_batch_size: int = 1,
- micro_batch_buffer_size: int = None,
- verbose: bool = False,
- # TODO: implement early_stopping, and various gerneration options
- early_stopping: bool = False,
- do_sample: bool = False,
- num_beams: int = 1,
- ) -> None:
- assert pp_model or (model and model_policy), "Either pp_model or model with model_policy should be provided."
- self.pp_size = pp_size
- self.pg_mesh = ProcessGroupMesh(pp_size)
- self.stage_manager = PipelineStageManager(self.pg_mesh, 0, True)
- self.mb_manager = MicroBatchManager(
- self.stage_manager.stage, new_length, micro_batch_size, micro_batch_buffer_size or pp_size
- )
- self.verbose = verbose
- self.schedule = GenerateSchedule(self.stage_manager, self.mb_manager, verbose)
-
- assert dtype in ["fp16", "fp32", "bf16"], "dtype should be one of 'fp16', 'fp32', 'bf16'"
- if dtype == "fp16":
- model.half()
- elif dtype == "bf16":
- model.to(torch.bfloat16)
- self.model = pp_model or self._shardformer(model, model_policy)
-
- def inference(self, input_list):
- out, timestamp = self.schedule.generate_step(self.model, iter(input_list))
- if self.verbose:
- return out, timestamp
- else:
- return out
-
- def _shardformer(self, model, model_policy):
- shardconfig = ShardConfig(
- tensor_parallel_process_group=None,
- pipeline_stage_manager=self.stage_manager,
- enable_tensor_parallelism=False,
- enable_fused_normalization=False,
- enable_all_optimization=False,
- enable_flash_attention=False,
- enable_jit_fused=False,
- enable_sequence_parallelism=False,
- )
- shardformer = ShardFormer(shard_config=shardconfig)
- shard_model, _ = shardformer.optimize(model, model_policy)
- return shard_model.cuda()
diff --git a/colossalai/inference/pipeline/modeling/gpt2.py b/colossalai/inference/pipeline/modeling/gpt2.py
deleted file mode 100644
index d2bfcb8b6842..000000000000
--- a/colossalai/inference/pipeline/modeling/gpt2.py
+++ /dev/null
@@ -1,280 +0,0 @@
-from typing import Dict, List, Optional, Tuple, Union
-
-import torch
-from transformers.modeling_outputs import BaseModelOutputWithPastAndCrossAttentions, CausalLMOutputWithCrossAttentions
-from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel, GPT2Model
-from transformers.utils import logging
-
-from colossalai.pipeline.stage_manager import PipelineStageManager
-
-
-class GPT2PipelineForwards:
- """
- This class serves as a micro library for forward function substitution of GPT2 models
- under pipeline setting.
- """
-
- @staticmethod
- def gpt2_model_forward(
- self: GPT2Model,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- token_type_ids: Optional[torch.LongTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- encoder_hidden_states: Optional[torch.Tensor] = None,
- encoder_attention_mask: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- ) -> Union[Dict, Tuple, BaseModelOutputWithPastAndCrossAttentions]:
- # This function is modified on the basis of transformers.models.gpt2.modeling_gpt2.GPT2Model.forward.
- # Please refer to original code of transformers for more details.
- logger = logging.get_logger(__name__)
-
- # Preprocess passed in arguments
- if output_attentions:
- logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
- output_attentions = False
- if output_hidden_states:
- logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
- output_hidden_states = False
-
- use_cache = use_cache if use_cache is not None else self.config.use_cache
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- if past_key_values is None:
- past_length = 0
- past_key_values = tuple([None] * len(self.h))
- else:
- past_length = past_key_values[0][0].size(-2)
-
- if stage_manager.is_first_stage():
- if input_ids is not None and inputs_embeds is not None:
- raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
- elif input_ids is not None:
- input_shape = input_ids.size()
- input_ids = input_ids.view(-1, input_shape[-1])
- batch_size = input_ids.shape[0]
- elif inputs_embeds is not None:
- input_shape = inputs_embeds.size()[:-1]
- batch_size = inputs_embeds.shape[0]
- else:
- raise ValueError("You have to specify either input_ids or inputs_embeds")
-
- device = input_ids.device if input_ids is not None else inputs_embeds.device
- if token_type_ids is not None:
- token_type_ids = token_type_ids.view(-1, input_shape[-1])
- else:
- if hidden_states is None:
- raise ValueError("hidden_states shouldn't be None for stages other than the first stage.")
- input_shape = hidden_states.size()[:-1]
- batch_size, seq_length = input_shape[0], input_shape[1]
- device = hidden_states.device
-
- # GPT2Attention mask.
- if attention_mask is not None:
- if batch_size <= 0:
- raise ValueError("batch_size has to be defined and > 0")
- attention_mask = attention_mask.view(batch_size, -1)
- # We create a 3D attention mask from a 2D tensor mask.
- # Sizes are [batch_size, 1, 1, to_seq_length]
- # So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
- # this attention mask is more simple than the triangular masking of causal attention
- # used in OpenAI GPT, we just need to prepare the broadcast dimension here.
- attention_mask = attention_mask[:, None, None, :]
-
- # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
- # masked positions, this operation will create a tensor which is 0.0 for
- # positions we want to attend and the dtype's smallest value for masked positions.
- # Since we are adding it to the raw scores before the softmax, this is
- # effectively the same as removing these entirely.
- attention_mask = attention_mask.to(dtype=self.dtype) # fp16 compatibility
- attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min
-
- # If a 2D or 3D attention mask is provided for the cross-attention
- # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
- if self.config.add_cross_attention and encoder_hidden_states is not None:
- encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
- encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
- if encoder_attention_mask is None:
- encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
- encoder_attention_mask = self.invert_attention_mask(encoder_attention_mask)
- else:
- encoder_attention_mask = None
-
- # Prepare head mask if needed
- # 1.0 in head_mask indicate we keep the head
- # attention_probs has shape bsz x n_heads x N x N
- # head_mask has shape n_layer x batch x n_heads x N x N
- head_mask = self.get_head_mask(head_mask, self.config.n_layer)
-
- if stage_manager.is_first_stage():
- if position_ids is not None:
- position_ids = position_ids.view(-1, input_shape[-1])
- else:
- position_ids = torch.arange(past_length, input_shape[-1] + past_length, dtype=torch.long, device=device)
- position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
-
- if inputs_embeds is None:
- inputs_embeds = self.wte(input_ids)
- position_embeds = self.wpe(position_ids)
- hidden_states = inputs_embeds + position_embeds
- if token_type_ids is not None:
- token_type_embeds = self.wte(token_type_ids)
- hidden_states = hidden_states + token_type_embeds
- hidden_states = self.drop(hidden_states)
-
- output_shape = input_shape + (hidden_states.size(-1),)
-
- if self.gradient_checkpointing and self.training:
- if use_cache:
- logger.warning_once(
- "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
- )
- use_cache = False
-
- presents = () if use_cache else None
- all_self_attentions = () if output_attentions else None
- all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
- all_hidden_states = () if output_hidden_states else None
-
- # Going through held blocks.
- start_idx, end_idx = stage_index[0], stage_index[1]
- for i, layer_past in zip(range(start_idx, end_idx), past_key_values):
- block = self.h[i]
- # Model parallel
- if self.model_parallel:
- torch.cuda.set_device(hidden_states.device)
- # Ensure layer_past is on same device as hidden_states (might not be correct)
- if layer_past is not None:
- layer_past = tuple(past_state.to(hidden_states.device) for past_state in layer_past)
- # Ensure that attention_mask is always on the same device as hidden_states
- if attention_mask is not None:
- attention_mask = attention_mask.to(hidden_states.device)
- if isinstance(head_mask, torch.Tensor):
- head_mask = head_mask.to(hidden_states.device)
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- if self.gradient_checkpointing and self.training:
-
- def create_custom_forward(module):
- def custom_forward(*inputs):
- # None for past_key_value
- return module(*inputs, use_cache, output_attentions)
-
- return custom_forward
-
- outputs = torch.utils.checkpoint.checkpoint(
- create_custom_forward(block),
- hidden_states,
- None,
- attention_mask,
- head_mask[i],
- encoder_hidden_states,
- encoder_attention_mask,
- )
- else:
- outputs = block(
- hidden_states,
- layer_past=layer_past,
- attention_mask=attention_mask,
- head_mask=head_mask[i],
- encoder_hidden_states=encoder_hidden_states,
- encoder_attention_mask=encoder_attention_mask,
- use_cache=use_cache,
- output_attentions=output_attentions,
- )
-
- hidden_states = outputs[0]
- if use_cache is True:
- presents = presents + (outputs[1],)
-
- if output_attentions:
- all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
- if self.config.add_cross_attention:
- all_cross_attentions = all_cross_attentions + (outputs[3 if use_cache else 2],)
-
- # Model Parallel: If it's the last layer for that device, put things on the next device
- if self.model_parallel:
- for k, v in self.device_map.items():
- if i == v[-1] and "cuda:" + str(k) != self.last_device:
- hidden_states = hidden_states.to("cuda:" + str(k + 1))
-
- if stage_manager.is_last_stage():
- hidden_states = self.ln_f(hidden_states)
-
- hidden_states = hidden_states.view(output_shape)
-
- # Add last hidden state
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- return {"hidden_states": hidden_states, "past_key_values": presents}
-
- @staticmethod
- def gpt2_lmhead_model_forward(
- self: GPT2LMHeadModel,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- token_type_ids: Optional[torch.LongTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- encoder_hidden_states: Optional[torch.Tensor] = None,
- encoder_attention_mask: Optional[torch.FloatTensor] = None,
- labels: Optional[torch.LongTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- ) -> Union[Dict, Tuple, CausalLMOutputWithCrossAttentions]:
- r"""
- labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
- Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
- `labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
- are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
-
- This function is modified on the basis of transformers.models.gpt2.modeling_gpt2.GPT2LMHeadModel.forward.
- Please refer to original code of transformers for more details.
- """
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- # If is first stage and after warmup, go throught lm_head first
- if stage_manager.is_first_stage() and hidden_states is not None:
- lm_logits = self.lm_head(hidden_states)
- return {"logits": lm_logits}
-
- # Not first stage or before warmup, go through gpt2 model
- outputs = GPT2PipelineForwards.gpt2_model_forward(
- self.transformer,
- input_ids,
- past_key_values=past_key_values,
- attention_mask=attention_mask,
- token_type_ids=token_type_ids,
- position_ids=position_ids,
- head_mask=head_mask,
- inputs_embeds=inputs_embeds,
- encoder_hidden_states=encoder_hidden_states,
- encoder_attention_mask=encoder_attention_mask,
- use_cache=use_cache,
- output_attentions=output_attentions,
- output_hidden_states=output_hidden_states,
- return_dict=return_dict,
- stage_manager=stage_manager,
- hidden_states=hidden_states,
- stage_index=stage_index,
- )
-
- return outputs
diff --git a/colossalai/inference/pipeline/modeling/llama.py b/colossalai/inference/pipeline/modeling/llama.py
deleted file mode 100644
index f46e1fbdd7b3..000000000000
--- a/colossalai/inference/pipeline/modeling/llama.py
+++ /dev/null
@@ -1,229 +0,0 @@
-from typing import List, Optional
-
-import torch
-from transformers.models.llama.modeling_llama import LlamaForCausalLM, LlamaModel
-from transformers.utils import logging
-
-from colossalai.pipeline.stage_manager import PipelineStageManager
-
-
-class LlamaPipelineForwards:
- """
- This class serves as a micro library for forward function substitution of Llama models
- under pipeline setting.
- """
-
- def llama_model_forward(
- self: LlamaModel,
- input_ids: torch.LongTensor = None,
- attention_mask: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[List[torch.FloatTensor]] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- ):
- logger = logging.get_logger(__name__)
-
- # Preprocess passed in arguments
- if output_attentions:
- logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
- output_attentions = False
- if output_hidden_states:
- logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
- output_hidden_states = False
-
- use_cache = use_cache if use_cache is not None else self.config.use_cache
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- # retrieve input_ids and inputs_embeds
- if stage_manager.is_first_stage():
- if input_ids is not None and inputs_embeds is not None:
- raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
- elif input_ids is not None:
- batch_size, seq_length = input_ids.shape
- elif inputs_embeds is not None:
- batch_size, seq_length, _ = inputs_embeds.shape
- else:
- raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
- device = input_ids.device if input_ids is not None else inputs_embeds.device
- if inputs_embeds is None:
- inputs_embeds = self.embed_tokens(input_ids)
- hidden_states = inputs_embeds
- else:
- input_shape = hidden_states.shape[:-1]
- batch_size, seq_length = input_shape
- device = hidden_states.device
-
- seq_length_with_past = seq_length
- past_key_values_length = 0
-
- if past_key_values is not None:
- past_key_values_length = past_key_values[0][0].shape[2]
- seq_length_with_past = seq_length_with_past + past_key_values_length
-
- if position_ids is None:
- position_ids = torch.arange(
- past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
- )
- position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
- else:
- position_ids = position_ids.view(-1, seq_length).long()
-
- # embed positions, for the first stage, hidden_states is the input embeddings,
- # for the other stages, hidden_states is the output of the previous stage
- if attention_mask is None:
- attention_mask = torch.ones(
- (batch_size, seq_length_with_past), dtype=torch.bool, device=hidden_states.device
- )
- attention_mask = self._prepare_decoder_attention_mask(
- attention_mask, (batch_size, seq_length), hidden_states, past_key_values_length
- )
-
- if self.gradient_checkpointing and self.training:
- if use_cache:
- logger.warning_once(
- "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
- )
- use_cache = False
-
- # decoder layers
- all_hidden_states = () if output_hidden_states else None
- all_self_attns = () if output_attentions else None
- next_decoder_cache = () if use_cache else None
-
- start_idx, end_idx = stage_index[0], stage_index[1]
- if past_key_values is None:
- past_key_values = tuple([None] * (end_idx - start_idx + 1))
-
- for idx, past_key_value in zip(range(start_idx, end_idx), past_key_values):
- decoder_layer = self.layers[idx]
- if output_hidden_states:
- all_hidden_states += (hidden_states,)
-
- # past_key_value = past_key_values[idx] if past_key_values is not None else None
-
- if self.gradient_checkpointing and self.training:
-
- def create_custom_forward(module):
- def custom_forward(*inputs):
- # None for past_key_value
- return module(*inputs, output_attentions, None)
-
- return custom_forward
-
- layer_outputs = torch.utils.checkpoint.checkpoint(
- create_custom_forward(decoder_layer),
- hidden_states,
- attention_mask,
- position_ids,
- None,
- )
- else:
- layer_outputs = decoder_layer(
- hidden_states,
- attention_mask=attention_mask,
- position_ids=position_ids,
- past_key_value=past_key_value,
- output_attentions=output_attentions,
- use_cache=use_cache,
- )
-
- hidden_states = layer_outputs[0]
-
- if use_cache:
- next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
- if output_attentions:
- all_self_attns += (layer_outputs[1],)
-
- if stage_manager.is_last_stage():
- hidden_states = self.norm(hidden_states)
-
- # add hidden states from the last decoder layer
- if output_hidden_states:
- all_hidden_states += (hidden_states,)
- next_cache = next_decoder_cache if use_cache else None
-
- # always return dict for imediate stage
- return {"hidden_states": hidden_states, "past_key_values": next_cache}
-
- def llama_for_causal_lm_forward(
- self: LlamaForCausalLM,
- input_ids: torch.LongTensor = None,
- attention_mask: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[List[torch.FloatTensor]] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- labels: Optional[torch.LongTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- stage_manager: Optional[PipelineStageManager] = None,
- hidden_states: Optional[torch.FloatTensor] = None,
- stage_index: Optional[List[int]] = None,
- ):
- r"""
- Args:
- labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
- Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
- config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
- (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
-
- Returns:
-
- Example:
-
- ```python
- >>> from transformers import AutoTokenizer, LlamaForCausalLM
-
- >>> model = LlamaForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
- >>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
-
- >>> prompt = "Hey, are you consciours? Can you talk to me?"
- >>> inputs = tokenizer(prompt, return_tensors="pt")
-
- >>> # Generate
- >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
- >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
- "Hey, are you consciours? Can you talk to me?\nI'm not consciours, but I can talk to you."
- ```"""
- logger = logging.get_logger(__name__)
-
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- if output_attentions:
- logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
- output_attentions = False
- if output_hidden_states:
- logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
- output_hidden_states = False
-
- # If is first stage and after warmup, go throught lm_head first
- if stage_manager.is_first_stage() and hidden_states is not None:
- lm_logits = self.lm_head(hidden_states)
- return {"logits": lm_logits}
-
- # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
- outputs = LlamaPipelineForwards.llama_model_forward(
- self.model,
- input_ids=input_ids,
- attention_mask=attention_mask,
- position_ids=position_ids,
- past_key_values=past_key_values,
- inputs_embeds=inputs_embeds,
- use_cache=use_cache,
- output_attentions=output_attentions,
- output_hidden_states=output_hidden_states,
- return_dict=return_dict,
- stage_manager=stage_manager,
- hidden_states=hidden_states,
- stage_index=stage_index,
- )
-
- return outputs
diff --git a/colossalai/inference/pipeline/policy/gpt2_ppinfer.py b/colossalai/inference/pipeline/policy/gpt2_ppinfer.py
deleted file mode 100644
index 51e6425b113e..000000000000
--- a/colossalai/inference/pipeline/policy/gpt2_ppinfer.py
+++ /dev/null
@@ -1,74 +0,0 @@
-from functools import partial
-from typing import Callable, Dict, List
-
-from torch import Tensor, nn
-
-import colossalai.shardformer.layer as col_nn
-from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
-from colossalai.shardformer.policies.gpt2 import GPT2Policy
-
-from ..modeling.gpt2 import GPT2PipelineForwards
-
-
-class GPT2LMHeadModelPipelinePolicy(GPT2Policy):
- def __init__(self) -> None:
- super().__init__()
-
- def module_policy(self):
- from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
-
- module_policy = super().module_policy()
-
- if self.shard_config.enable_tensor_parallelism:
- addon_module = {
- GPT2LMHeadModel: ModulePolicyDescription(
- sub_module_replacement=[
- SubModuleReplacementDescription(
- suffix="lm_head", target_module=col_nn.Linear1D_Col, kwargs={"gather_output": True}
- )
- ]
- )
- }
- module_policy.update(addon_module)
-
- if self.pipeline_stage_manager is not None:
- self.set_pipeline_forward(
- model_cls=GPT2LMHeadModel,
- new_forward=GPT2PipelineForwards.gpt2_lmhead_model_forward,
- policy=module_policy,
- )
- return module_policy
-
- def get_held_layers(self) -> List[nn.Module]:
- held_layers = super().get_held_layers()
- # make the tie weight lm_head and embedding in the same device to save memory
- # if self.pipeline_stage_manager.is_first_stage():
- if self.pipeline_stage_manager.is_first_stage():
- held_layers.append(self.model.lm_head)
- return held_layers
-
- def get_shared_params(self) -> List[Dict[int, Tensor]]:
- """The weights of wte and lm_head are shared."""
- module = self.model
- stage_manager = self.pipeline_stage_manager
- if stage_manager is not None:
- if stage_manager.num_stages > 1 and id(module.transformer.wte.weight) == id(module.lm_head.weight):
- first_stage, last_stage = 0, stage_manager.num_stages - 1
- return [{first_stage: module.transformer.wte.weight, last_stage: module.lm_head.weight}]
- return []
-
- def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, policy: Dict) -> None:
- """If under pipeline parallel setting, replacing the original forward method of huggingface
- to customized forward method, and add this changing to policy."""
- if not self.pipeline_stage_manager:
- raise ValueError("set_pipeline_forward method can only be called when pipeline parallel is enabled.")
- stage_manager = self.pipeline_stage_manager
- if self.model.__class__.__name__ == "GPT2Model":
- module = self.model
- else:
- module = self.model.transformer
-
- layers_per_stage = Policy.distribute_layers(len(module.h), stage_manager.num_stages)
- stage_index = Policy.get_stage_index(layers_per_stage, stage_manager.stage)
- method_replacement = {"forward": partial(new_forward, stage_manager=stage_manager, stage_index=stage_index)}
- self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=model_cls)
diff --git a/colossalai/inference/pipeline/policy/llama_ppinfer.py b/colossalai/inference/pipeline/policy/llama_ppinfer.py
deleted file mode 100644
index 6e12ed61bf7b..000000000000
--- a/colossalai/inference/pipeline/policy/llama_ppinfer.py
+++ /dev/null
@@ -1,48 +0,0 @@
-from typing import List
-
-from torch.nn import Module
-
-from colossalai.shardformer.layer import Linear1D_Col
-from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
-from colossalai.shardformer.policies.llama import LlamaPolicy
-
-from ..modeling.llama import LlamaPipelineForwards
-
-
-class LlamaForCausalLMPipelinePolicy(LlamaPolicy):
- def __init__(self) -> None:
- super().__init__()
-
- def module_policy(self):
- from transformers import LlamaForCausalLM
-
- policy = super().module_policy()
-
- if self.shard_config.enable_tensor_parallelism:
- # add a new item for casual lm
- new_item = {
- LlamaForCausalLM: ModulePolicyDescription(
- sub_module_replacement=[
- SubModuleReplacementDescription(
- suffix="lm_head", target_module=Linear1D_Col, kwargs=dict(gather_output=True)
- )
- ]
- )
- }
- policy.update(new_item)
-
- if self.pipeline_stage_manager:
- # set None as default
- self.set_pipeline_forward(
- model_cls=LlamaForCausalLM, new_forward=LlamaPipelineForwards.llama_for_causal_lm_forward, policy=policy
- )
-
- return policy
-
- def get_held_layers(self) -> List[Module]:
- """Get pipeline layers for current stage."""
- stage_manager = self.pipeline_stage_manager
- held_layers = super().get_held_layers()
- if stage_manager.is_first_stage():
- held_layers.append(self.model.lm_head)
- return held_layers
diff --git a/colossalai/inference/pipeline/utils.py b/colossalai/inference/pipeline/utils.py
deleted file mode 100644
index c26aa4e40b71..000000000000
--- a/colossalai/inference/pipeline/utils.py
+++ /dev/null
@@ -1,35 +0,0 @@
-from typing import Set
-
-import torch.nn as nn
-
-from colossalai.shardformer._utils import getattr_, setattr_
-
-
-def set_tensors_to_none(model: nn.Module, include: Set[str] = set()) -> None:
- """
- Set all parameters and buffers of model to None
-
- Args:
- model (nn.Module): The model to set
- """
- for module_suffix in include:
- set_module = getattr_(model, module_suffix)
- for n, p in set_module.named_parameters():
- setattr_(set_module, n, None)
- for n, buf in set_module.named_buffers():
- setattr_(set_module, n, None)
- setattr_(model, module_suffix, None)
-
-
-def get_suffix_name(suffix: str, name: str):
- """
- Get the suffix name of the module, as `suffix.name` when name is string or `suffix[name]` when name is a digit,
- and 'name' when `suffix` is empty.
-
- Args:
- suffix (str): The suffix of the suffix module
- name (str): The name of the current module
- """
- point = "" if suffix is "" else "."
- suffix_name = suffix + f"[{name}]" if name.isdigit() else suffix + f"{point}{name}"
- return suffix_name
diff --git a/colossalai/inference/quant/__init__.py b/colossalai/inference/quant/__init__.py
new file mode 100644
index 000000000000..18e0de9cc9fc
--- /dev/null
+++ b/colossalai/inference/quant/__init__.py
@@ -0,0 +1 @@
+from .smoothquant.models.llama import SmoothLlamaForCausalLM
diff --git a/colossalai/inference/quant/gptq/__init__.py b/colossalai/inference/quant/gptq/__init__.py
index c035f397923a..4cf1fd658a41 100644
--- a/colossalai/inference/quant/gptq/__init__.py
+++ b/colossalai/inference/quant/gptq/__init__.py
@@ -2,3 +2,4 @@
if HAS_AUTO_GPTQ:
from .cai_gptq import CaiGPTQLinearOp, CaiQuantLinear
+ from .gptq_manager import GPTQManager
diff --git a/colossalai/inference/quant/gptq/gptq_manager.py b/colossalai/inference/quant/gptq/gptq_manager.py
new file mode 100644
index 000000000000..2d352fbef2b9
--- /dev/null
+++ b/colossalai/inference/quant/gptq/gptq_manager.py
@@ -0,0 +1,61 @@
+import torch
+
+
+class GPTQManager:
+ def __init__(self, quant_config, max_input_len: int = 1):
+ self.max_dq_buffer_size = 1
+ self.max_inner_outer_dim = 1
+ self.bits = quant_config.bits
+ self.use_act_order = quant_config.desc_act
+ self.max_input_len = 1
+ self.gptq_temp_state_buffer = None
+ self.gptq_temp_dq_buffer = None
+ self.quant_config = quant_config
+
+ def post_init_gptq_buffer(self, model: torch.nn.Module) -> None:
+ from .cai_gptq import CaiQuantLinear
+
+ HAS_GPTQ_CUDA = False
+ try:
+ from colossalai.kernel.op_builder.gptq import GPTQBuilder
+
+ gptq_cuda = GPTQBuilder().load()
+ HAS_GPTQ_CUDA = True
+ except ImportError:
+ warnings.warn("CUDA gptq is not installed")
+ HAS_GPTQ_CUDA = False
+
+ for name, submodule in model.named_modules():
+ if isinstance(submodule, CaiQuantLinear):
+ self.max_dq_buffer_size = max(self.max_dq_buffer_size, submodule.qweight.numel() * 8)
+
+ if self.use_act_order:
+ self.max_inner_outer_dim = max(
+ self.max_inner_outer_dim, submodule.infeatures, submodule.outfeatures
+ )
+ self.bits = submodule.bits
+ if not (HAS_GPTQ_CUDA and self.bits == 4):
+ return
+
+ max_input_len = 1
+ if self.use_act_order:
+ max_input_len = self.max_input_len
+ # The temp_state buffer is required to reorder X in the act-order case.
+ # The temp_dq buffer is required to dequantize weights when using cuBLAS, typically for the prefill.
+ self.gptq_temp_state_buffer = torch.zeros(
+ (max_input_len, self.max_inner_outer_dim), dtype=torch.float16, device=torch.cuda.current_device()
+ )
+ self.gptq_temp_dq_buffer = torch.zeros(
+ (1, self.max_dq_buffer_size), dtype=torch.float16, device=torch.cuda.current_device()
+ )
+
+ gptq_cuda.prepare_buffers(
+ torch.device(torch.cuda.current_device()), self.gptq_temp_state_buffer, self.gptq_temp_dq_buffer
+ )
+ # Using the default from exllama repo here.
+ matmul_recons_thd = 8
+ matmul_fused_remap = False
+ matmul_no_half2 = False
+ gptq_cuda.set_tuning_params(matmul_recons_thd, matmul_fused_remap, matmul_no_half2)
+
+ torch.cuda.empty_cache()
diff --git a/colossalai/inference/quant/smoothquant/models/__init__.py b/colossalai/inference/quant/smoothquant/models/__init__.py
index 77541d8610c5..1663028da138 100644
--- a/colossalai/inference/quant/smoothquant/models/__init__.py
+++ b/colossalai/inference/quant/smoothquant/models/__init__.py
@@ -4,9 +4,7 @@
HAS_TORCH_INT = True
except ImportError:
HAS_TORCH_INT = False
- raise ImportError(
- "Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int"
- )
+ print("Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int")
if HAS_TORCH_INT:
from .llama import LLamaSmoothquantAttention, LlamaSmoothquantMLP
diff --git a/colossalai/inference/quant/smoothquant/models/base_model.py b/colossalai/inference/quant/smoothquant/models/base_model.py
index 6a1d96ecec8f..f3afe5d83bb0 100644
--- a/colossalai/inference/quant/smoothquant/models/base_model.py
+++ b/colossalai/inference/quant/smoothquant/models/base_model.py
@@ -9,7 +9,6 @@
from os.path import isdir, isfile, join
from typing import Dict, List, Optional, Union
-import accelerate
import numpy as np
import torch
import torch.nn as nn
@@ -21,8 +20,16 @@
from transformers.utils.generic import ContextManagers
from transformers.utils.hub import PushToHubMixin, cached_file
-from colossalai.inference.tensor_parallel.batch_infer_state import BatchInferState
-from colossalai.inference.tensor_parallel.kvcache_manager import MemoryManager
+from colossalai.inference.kv_cache.batch_infer_state import BatchInferState, MemoryManager
+
+try:
+ import accelerate
+
+ HAS_ACCELERATE = True
+except ImportError:
+ HAS_ACCELERATE = False
+ print("accelerate is not installed.")
+
SUPPORTED_MODELS = ["llama"]
@@ -87,7 +94,6 @@ def init_batch_state(self, max_output_len=256, **kwargs):
batch_infer_state.start_loc = seq_start_indexes.to("cuda")
batch_infer_state.block_loc = block_loc
batch_infer_state.decode_layer_id = 0
- batch_infer_state.past_key_values_len = 0
batch_infer_state.is_context_stage = True
batch_infer_state.set_cache_manager(self.cache_manager)
batch_infer_state.cache_manager.free_all()
diff --git a/colossalai/inference/quant/smoothquant/models/linear.py b/colossalai/inference/quant/smoothquant/models/linear.py
index 969c390a0849..03d994b32489 100644
--- a/colossalai/inference/quant/smoothquant/models/linear.py
+++ b/colossalai/inference/quant/smoothquant/models/linear.py
@@ -1,17 +1,25 @@
# modified from torch-int: https://github.com/Guangxuan-Xiao/torch-int/blob/main/torch_int/nn/linear.py
import torch
-from torch_int._CUDA import linear_a8_w8_b8_o8, linear_a8_w8_bfp32_ofp32
-from torch_int.functional.quantization import quantize_per_tensor_absmax
+
+try:
+ from torch_int._CUDA import linear_a8_w8_b8_o8, linear_a8_w8_bfp32_ofp32
+ from torch_int.functional.quantization import quantize_per_tensor_absmax
+
+ HAS_TORCH_INT = True
+except ImportError:
+ HAS_TORCH_INT = False
+ print("Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int")
+
try:
from colossalai.kernel.op_builder.smoothquant import SmoothquantBuilder
smoothquant_cuda = SmoothquantBuilder().load()
HAS_SMOOTHQUANT_CUDA = True
-except ImportError:
+except:
HAS_SMOOTHQUANT_CUDA = False
- raise ImportError("CUDA smoothquant linear is not installed")
+ print("CUDA smoothquant linear is not installed")
class W8A8BFP32O32LinearSiLU(torch.nn.Module):
@@ -138,21 +146,23 @@ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
)
self.register_buffer(
"bias",
- torch.zeros(self.out_features, dtype=torch.float32, requires_grad=False),
+ torch.zeros((1, self.out_features), dtype=torch.float32, requires_grad=False),
)
self.register_buffer("a", torch.tensor(alpha))
def _apply(self, fn):
# prevent the bias from being converted to half
super()._apply(fn)
- self.bias = self.bias.to(torch.float32)
+ if self.bias is not None:
+ self.bias = self.bias.to(torch.float32)
return self
def to(self, *args, **kwargs):
super().to(*args, **kwargs)
self.weight = self.weight.to(*args, **kwargs)
- self.bias = self.bias.to(*args, **kwargs)
- self.bias = self.bias.to(torch.float32)
+ if self.bias is not None:
+ self.bias = self.bias.to(*args, **kwargs)
+ self.bias = self.bias.to(torch.float32)
return self
@torch.no_grad()
diff --git a/colossalai/inference/quant/smoothquant/models/llama.py b/colossalai/inference/quant/smoothquant/models/llama.py
index 4c3d6dcc0b23..bb74dc49d7af 100644
--- a/colossalai/inference/quant/smoothquant/models/llama.py
+++ b/colossalai/inference/quant/smoothquant/models/llama.py
@@ -8,7 +8,6 @@
import torch
import torch.nn as nn
import torch.nn.functional as F
-from torch_int.nn.bmm import BMM_S8T_S8N_F32T, BMM_S8T_S8N_S8T
from transformers import PreTrainedModel
from transformers.modeling_outputs import BaseModelOutputWithPast
from transformers.models.llama.configuration_llama import LlamaConfig
@@ -18,12 +17,11 @@
LlamaDecoderLayer,
LlamaMLP,
LlamaRotaryEmbedding,
- repeat_kv,
rotate_half,
)
from transformers.utils import add_start_docstrings_to_model_forward
-from colossalai.inference.tensor_parallel.batch_infer_state import BatchInferState
+from colossalai.inference.kv_cache.batch_infer_state import BatchInferState
from colossalai.kernel.triton import (
copy_kv_cache_to_dest,
int8_rotary_embedding_fwd,
@@ -31,10 +29,31 @@
smooth_token_attention_fwd,
)
+try:
+ from torch_int.nn.bmm import BMM_S8T_S8N_F32T, BMM_S8T_S8N_S8T
+
+ HAS_TORCH_INT = True
+except ImportError:
+ HAS_TORCH_INT = False
+ print("Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int")
+
+
from .base_model import BaseSmoothForCausalLM
from .linear import W8A8B8O8Linear, W8A8BFP32O32LinearSiLU, W8A8BFP32OFP32Linear
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """
+ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
+ num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
+
+
class LLamaSmoothquantAttention(nn.Module):
def __init__(
self,
@@ -116,7 +135,6 @@ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
def forward(
self,
hidden_states: torch.Tensor,
- rotary_emb: Tuple[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
@@ -131,8 +149,7 @@ def forward(
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
- cos = rotary_emb[0]
- sin = rotary_emb[1]
+ cos, sin = infer_state.position_cos, infer_state.position_sin
int8_rotary_embedding_fwd(
query_states.view(-1, self.num_heads, self.head_dim),
@@ -149,12 +166,6 @@ def forward(
self.k_rotary_output_scale.item(),
)
- # NOTE might want to revise
- # need some way to record the length of past key values cache
- # since we won't return past_key_value_cache right now
- if infer_state.decode_layer_id == 0: # once per model.forward
- infer_state.cache_manager.past_key_values_length += q_len # seq_len
-
def _copy_kv_to_mem_cache(layer_id, key_buffer, value_buffer, context_mem_index, mem_manager):
copy_kv_cache_to_dest(key_buffer, context_mem_index, mem_manager.key_buffer[layer_id])
copy_kv_cache_to_dest(value_buffer, context_mem_index, mem_manager.value_buffer[layer_id])
@@ -229,7 +240,7 @@ def _copy_kv_to_mem_cache(layer_id, key_buffer, value_buffer, context_mem_index,
infer_state.block_loc,
infer_state.start_loc,
infer_state.seq_len,
- infer_state.cache_manager.past_key_values_length,
+ infer_state.max_len_in_batch,
)
attn_output = attn_output.view(bsz, q_len, self.num_heads * self.head_dim)
@@ -354,7 +365,6 @@ def pack(
def forward(
self,
hidden_states: torch.Tensor,
- rotary_emb: Tuple[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
@@ -384,7 +394,6 @@ def forward(
# Self Attention
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
- rotary_emb=rotary_emb,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
@@ -592,17 +601,13 @@ def llama_model_forward(
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
- seq_length_with_past = seq_length
- past_key_values_length = 0
-
infer_state = self.infer_state
+ if infer_state.is_context_stage:
+ past_key_values_length = 0
+ else:
+ past_key_values_length = infer_state.max_len_in_batch - 1
- if past_key_values is not None:
- # NOT READY FOR PRIME TIME
- # dummy but work, revise it
- past_key_values_length = infer_state.cache_manager.past_key_values_length
- # past_key_values_length = past_key_values[0][0].shape[2]
- seq_length_with_past = seq_length_with_past + past_key_values_length
+ seq_length_with_past = seq_length + past_key_values_length
# NOTE: differentiate with prefill stage
# block_loc require different value-assigning method for two different stage
@@ -623,9 +628,7 @@ def llama_model_forward(
infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
else:
print(f" *** Encountered allocation non-contiguous")
- print(
- f" infer_state.cache_manager.past_key_values_length: {infer_state.cache_manager.past_key_values_length}"
- )
+ print(f" infer_state.cache_manager.max_len_in_batch: {infer_state.max_len_in_batch}")
infer_state.decode_is_contiguous = False
alloc_mem = infer_state.cache_manager.alloc(batch_size)
infer_state.decode_mem_index = alloc_mem
@@ -662,15 +665,15 @@ def llama_model_forward(
raise NotImplementedError("not implement gradient_checkpointing and training options ")
if past_key_values_length == 0:
- position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
position_ids.view(-1).shape[0], -1
)
- position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
position_ids.view(-1).shape[0], -1
)
else:
- position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(batch_size, -1)
- position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(batch_size, -1)
+ infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(batch_size, -1)
+ infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(batch_size, -1)
# decoder layers
all_hidden_states = () if output_hidden_states else None
@@ -685,7 +688,6 @@ def llama_model_forward(
layer_outputs = decoder_layer(
hidden_states,
- rotary_emb=(position_cos, position_sin),
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
@@ -713,6 +715,7 @@ def llama_model_forward(
infer_state.is_context_stage = False
infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
infer_state.seq_len += 1
+ infer_state.max_len_in_batch += 1
next_cache = next_decoder_cache if use_cache else None
if not return_dict:
diff --git a/colossalai/inference/quant/smoothquant/models/parallel_linear.py b/colossalai/inference/quant/smoothquant/models/parallel_linear.py
new file mode 100644
index 000000000000..962b687a1d05
--- /dev/null
+++ b/colossalai/inference/quant/smoothquant/models/parallel_linear.py
@@ -0,0 +1,264 @@
+from typing import List, Union
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from torch.distributed import ProcessGroup
+
+from colossalai.lazy import LazyInitContext
+from colossalai.shardformer.layer import ParallelModule
+
+from .linear import W8A8B8O8Linear, W8A8BFP32O32LinearSiLU, W8A8BFP32OFP32Linear
+
+
+def split_row_copy(smooth_linear, para_linear, tp_size=1, tp_rank=0, split_num=1):
+ qweights = smooth_linear.weight.split(smooth_linear.out_features // split_num, dim=0)
+ if smooth_linear.bias is not None:
+ bias = smooth_linear.bias.split(smooth_linear.out_features // split_num, dim=0)
+
+ smooth_split_out_features = para_linear.out_features // split_num
+
+ for i in range(split_num):
+ para_linear.weight[i * smooth_split_out_features : (i + 1) * smooth_split_out_features, :] = qweights[i][
+ tp_rank * smooth_split_out_features : (tp_rank + 1) * smooth_split_out_features, :
+ ]
+
+ if para_linear.bias is not None:
+ para_linear.bias[:, i * smooth_split_out_features : (i + 1) * smooth_split_out_features] = bias[i][
+ :, tp_rank * smooth_split_out_features : (tp_rank + 1) * smooth_split_out_features
+ ]
+
+
+def split_column_copy(smooth_linear, para_linear, tp_rank=0, split_num=1):
+ qweights = smooth_linear.weight.split(smooth_linear.in_features // split_num, dim=-1)
+
+ smooth_split_in_features = para_linear.in_features // split_num
+
+ for i in range(split_num):
+ para_linear.weight[:, i * smooth_split_in_features : (i + 1) * smooth_split_in_features] = qweights[i][
+ :, tp_rank * smooth_split_in_features : (tp_rank + 1) * smooth_split_in_features
+ ]
+
+ if smooth_linear.bias is not None:
+ para_linear.bias.copy_(smooth_linear.bias)
+
+
+class RowW8A8B8O8Linear(W8A8B8O8Linear, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ out_features = module.out_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if out_features < tp_size:
+ return module
+
+ if out_features % tp_size != 0:
+ raise ValueError(
+ f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = RowW8A8B8O8Linear(module.in_features, module.out_features // tp_size)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = module.a.clone().detach()
+ linear_1d.b = module.b.clone().detach()
+ split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ return linear_1d
+
+
+class ColW8A8B8O8Linear(W8A8B8O8Linear, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ in_features = module.in_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if in_features < tp_size:
+ return module
+
+ if in_features % tp_size != 0:
+ raise ValueError(
+ f"The size of in_features:{in_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = ColW8A8B8O8Linear(module.in_features // tp_size, module.out_features)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = torch.tensor(module.a)
+ linear_1d.b = torch.tensor(module.b)
+
+ split_column_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ if linear_1d.bias is not None:
+ linear_1d.bias = linear_1d.bias // tp_size
+
+ return linear_1d
+
+ @torch.no_grad()
+ def forward(self, x):
+ output = super().forward(x)
+ if self.tp_size > 1:
+ dist.all_reduce(output, op=dist.ReduceOp.SUM, group=self.process_group)
+ return output
+
+
+class RowW8A8BFP32O32LinearSiLU(W8A8BFP32O32LinearSiLU, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ out_features = module.out_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if out_features < tp_size:
+ return module
+
+ if out_features % tp_size != 0:
+ raise ValueError(
+ f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = RowW8A8BFP32O32LinearSiLU(module.in_features, module.out_features // tp_size)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = module.a.clone().detach()
+
+ split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ return linear_1d
+
+
+class RowW8A8BFP32OFP32Linear(W8A8BFP32OFP32Linear, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ out_features = module.out_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if out_features < tp_size:
+ return module
+
+ if out_features % tp_size != 0:
+ raise ValueError(
+ f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = RowW8A8BFP32OFP32Linear(module.in_features, module.out_features // tp_size)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = module.a.clone().detach()
+
+ split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ return linear_1d
+
+
+class ColW8A8BFP32OFP32Linear(W8A8BFP32OFP32Linear, ParallelModule):
+ def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
+ super().__init__(in_features, out_features, alpha, beta)
+ self.process_group = None
+ self.tp_size = 1
+ self.tp_rank = 0
+
+ @staticmethod
+ def from_native_module(
+ module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
+ ) -> ParallelModule:
+ LazyInitContext.materialize(module)
+ # get the attributes
+ in_features = module.in_features
+
+ # ensure only one process group is passed
+ if isinstance(process_group, (list, tuple)):
+ assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
+ process_group = process_group[0]
+
+ tp_size = dist.get_world_size(process_group)
+ tp_rank = dist.get_rank(process_group)
+
+ if in_features < tp_size:
+ return module
+
+ if in_features % tp_size != 0:
+ raise ValueError(
+ f"The size of in_features:{in_features} is not integer multiples of tensor parallel size: {tp_size}!"
+ )
+ linear_1d = ColW8A8BFP32OFP32Linear(module.in_features // tp_size, module.out_features)
+ linear_1d.tp_size = tp_size
+ linear_1d.tp_rank = tp_rank
+ linear_1d.process_group = process_group
+ linear_1d.a = module.a.clone().detach()
+
+ split_column_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
+ if linear_1d.bias is not None:
+ linear_1d.bias = linear_1d.bias / tp_size
+
+ return linear_1d
+
+ @torch.no_grad()
+ def forward(self, x):
+ output = super().forward(x)
+ if self.tp_size > 1:
+ dist.all_reduce(output, op=dist.ReduceOp.SUM, group=self.process_group)
+ return output
diff --git a/colossalai/inference/tensor_parallel/batch_infer_state.py b/colossalai/inference/tensor_parallel/batch_infer_state.py
deleted file mode 100644
index 33e79ec04bcb..000000000000
--- a/colossalai/inference/tensor_parallel/batch_infer_state.py
+++ /dev/null
@@ -1,58 +0,0 @@
-# might want to consider combine with InferenceConfig in colossalai/ppinference/inference_config.py later
-from dataclasses import dataclass
-
-import torch
-
-from .kvcache_manager import MemoryManager
-
-
-# adapted from: lightllm/server/router/model_infer/infer_batch.py
-@dataclass
-class BatchInferState:
- r"""
- Information to be passed and used for a batch of inputs during
- a single model forward
- """
- batch_size: int
- max_len_in_batch: int
-
- cache_manager: MemoryManager = None
-
- block_loc: torch.Tensor = None
- start_loc: torch.Tensor = None
- seq_len: torch.Tensor = None
- past_key_values_len: int = None
-
- is_context_stage: bool = False
- context_mem_index: torch.Tensor = None
- decode_is_contiguous: bool = None
- decode_mem_start: int = None
- decode_mem_end: int = None
- decode_mem_index: torch.Tensor = None
- decode_layer_id: int = None
-
- device: torch.device = torch.device("cuda")
-
- @property
- def total_token_num(self):
- # return self.batch_size * self.max_len_in_batch
- assert self.seq_len is not None and self.seq_len.size(0) > 0
- return int(torch.sum(self.seq_len))
-
- def set_cache_manager(self, manager: MemoryManager):
- self.cache_manager = manager
-
- # adapted from: https://github.com/ModelTC/lightllm/blob/28c1267cfca536b7b4f28e921e03de735b003039/lightllm/common/infer_utils.py#L1
- @staticmethod
- def init_block_loc(
- b_loc: torch.Tensor, seq_len: torch.Tensor, max_len_in_batch: int, alloc_mem_index: torch.Tensor
- ):
- """in-place update block loc mapping based on the sequence length of the inputs in current bath"""
- start_index = 0
- seq_len_numpy = seq_len.cpu().numpy()
- for i, cur_seq_len in enumerate(seq_len_numpy):
- b_loc[i, max_len_in_batch - cur_seq_len : max_len_in_batch] = alloc_mem_index[
- start_index : start_index + cur_seq_len
- ]
- start_index += cur_seq_len
- return
diff --git a/colossalai/initialize.py b/colossalai/initialize.py
index aac57d34a2c1..aaeaad3828f5 100644
--- a/colossalai/initialize.py
+++ b/colossalai/initialize.py
@@ -6,12 +6,12 @@
from pathlib import Path
from typing import Dict, Union
-import torch
import torch.distributed as dist
+from colossalai.accelerator import get_accelerator
from colossalai.context import Config
from colossalai.logging import get_dist_logger
-from colossalai.utils import set_device, set_seed
+from colossalai.utils import set_seed
def launch(
@@ -47,14 +47,18 @@ def launch(
if rank == 0:
warnings.warn("`config` is deprecated and will be removed soon.")
+ cur_accelerator = get_accelerator()
+
+ backend = cur_accelerator.communication_backend
+
# init default process group
init_method = f"tcp://[{host}]:{port}"
dist.init_process_group(rank=rank, world_size=world_size, backend=backend, init_method=init_method)
# set cuda device
- if torch.cuda.is_available():
- # if local rank is not given, calculate automatically
- set_device(local_rank)
+ # if local rank is not given, calculate automatically
+ if cur_accelerator.support_set_device:
+ cur_accelerator.set_device(local_rank)
set_seed(seed)
diff --git a/colossalai/kernel/__init__.py b/colossalai/kernel/__init__.py
index 8933fc0a3c2f..e69de29bb2d1 100644
--- a/colossalai/kernel/__init__.py
+++ b/colossalai/kernel/__init__.py
@@ -1,7 +0,0 @@
-from .cuda_native import FusedScaleMaskSoftmax, LayerNorm, MultiHeadAttention
-
-__all__ = [
- "LayerNorm",
- "FusedScaleMaskSoftmax",
- "MultiHeadAttention",
-]
diff --git a/colossalai/kernel/cuda_native/csrc/gptq/column_remap.cu b/colossalai/kernel/cuda_native/csrc/gptq/column_remap.cu
deleted file mode 100644
index 2b1b366b1c02..000000000000
--- a/colossalai/kernel/cuda_native/csrc/gptq/column_remap.cu
+++ /dev/null
@@ -1,63 +0,0 @@
-// Adapted from turboderp exllama: https://github.com/turboderp/exllama
-
-#include "column_remap.cuh"
-#include "util.cuh"
-
-const int SHUF_BLOCKSIZE_X = 256;
-const int SHUF_BLOCKSIZE_Y = 16;
-
-__global__ void column_remap_kernel
-(
- const half* __restrict__ x,
- half* __restrict__ x_new,
- const int x_width,
- const int x_height,
- const uint32_t* x_map
-)
-{
- int x_column = SHUF_BLOCKSIZE_X * blockIdx.x + threadIdx.x;
- int x_row = SHUF_BLOCKSIZE_Y * blockIdx.y;
- if (x_column >= x_width) return;
- //if (x_row >= x_height) return;
-
- int x_stride = x_width;
- int x_idx = x_row * x_stride + x_column;
-
- int x_row_end = min(x_row + SHUF_BLOCKSIZE_Y, x_height);
- int x_idx_end = x_row_end * x_stride + x_column;
-
- int s_column = x_map[x_column];
- int s_idx = x_row * x_stride + s_column;
-
- while (x_idx < x_idx_end)
- {
- x_new[x_idx] = x[s_idx];
- x_idx += x_stride;
- s_idx += x_stride;
- }
-}
-
-// Remap columns in x to correspond to sequential group index before matmul
-//
-// perform x -> seq_x such that seq_x @ seq_w == x @ w
-
-void column_remap_cuda
-(
- const half* x,
- half* x_new,
- const int x_height,
- const int x_width,
- const uint32_t* x_map
-)
-{
- dim3 threads(SHUF_BLOCKSIZE_X, 1, 1);
-
- dim3 blocks
- (
- (x_width + SHUF_BLOCKSIZE_X - 1) / SHUF_BLOCKSIZE_X,
- (x_height + SHUF_BLOCKSIZE_Y - 1) / SHUF_BLOCKSIZE_Y,
- 1
- );
-
- column_remap_kernel<<