From f6980752a18b6ba7a625463b346c15176e8ca802 Mon Sep 17 00:00:00 2001
From: gstdl <54521960+gstdl@users.noreply.github.com>
Date: Sat, 22 Oct 2022 20:04:57 +0700
Subject: [PATCH 1/7] add chapter0
---
chapters/id/chapter0/1.mdx | 110 +++++++++++++++++++++++++++++++++++++
1 file changed, 110 insertions(+)
create mode 100644 chapters/id/chapter0/1.mdx
diff --git a/chapters/id/chapter0/1.mdx b/chapters/id/chapter0/1.mdx
new file mode 100644
index 000000000..0f49326d9
--- /dev/null
+++ b/chapters/id/chapter0/1.mdx
@@ -0,0 +1,110 @@
+# Pendahuluan
+
+Selamat datang di kursus Hugging Face! Pada Bab ini, anda akan dibimbing untuk mempersiapkan _working environment_. Jika anda memulai kursus ini untuk pertama kali, anda sangat direkomendasikan untuk menyelesaikan [Bab 1](/course/chapter1) terlebih dahulu. Setelah menyelesaikan [Bab 1](/course/chapter1) anda bisa kembali ke page ini untuk mencoba eksplorasi kodenya secara independen.
+
+Semua modul yang digunakan dalam kursus ini tersedia dalam modul Python. Di kursus ini, anda juga akan dibimbing untuk mempersiapkan Python _environment_ dan menginstal modul-modul yang dibutuhkan.
+
+Ada 2 cara untuk jenis _working environment_ yang bisa anda gunakan, Colab notebook dan _virtual environment_ Python. Anda bebas memilih _working envrionment_, tapi untuk pemula, kami menyarankan untuk menggunakan Colab notebook.
+
+Sebagai catatan, kursus ini tidak mencakup instalasi untuk pengguna Windows. Jika anda menggunakan Windows, mohon menggunakan Colab notebook. Jika anda adalah pengguna Linux atau macOS, anda bebas memilih _working environment_ yang akan dijelaskan dibawah.
+
+Sebagian besar dari kursus ini akan mewajibkan anda untuk memiliki akun Hugging Face. Jika anda belum memiliki akun, silahkan mendaftar terlebih dahulu di tautan berikut [https://huggingface.co/join](https://huggingface.co/join).
+
+## Menggunakan Google Colab notebook
+
+Menggunakan Colab notebook sangatlah sederhana, cukup dengan membuat notebook baru anda sudah bisa mulai koding!
+
+Jika anda belum terbiasa menggunakan Colab, silahkan mengikuti [tutorial pengenalan Colab dari Google](https://colab.research.google.com/notebooks/intro.ipynb) (hanya tersedia dalam Bahasa Inggris). Saat menggunakan Colab, anda dapat mengakses hardware seperti GPU dan TPU yang dapat mengakselerasi proses pengolahan data. Hardware ini dapat anda gunakan secara gratis untuk proyek skala kecil.
+
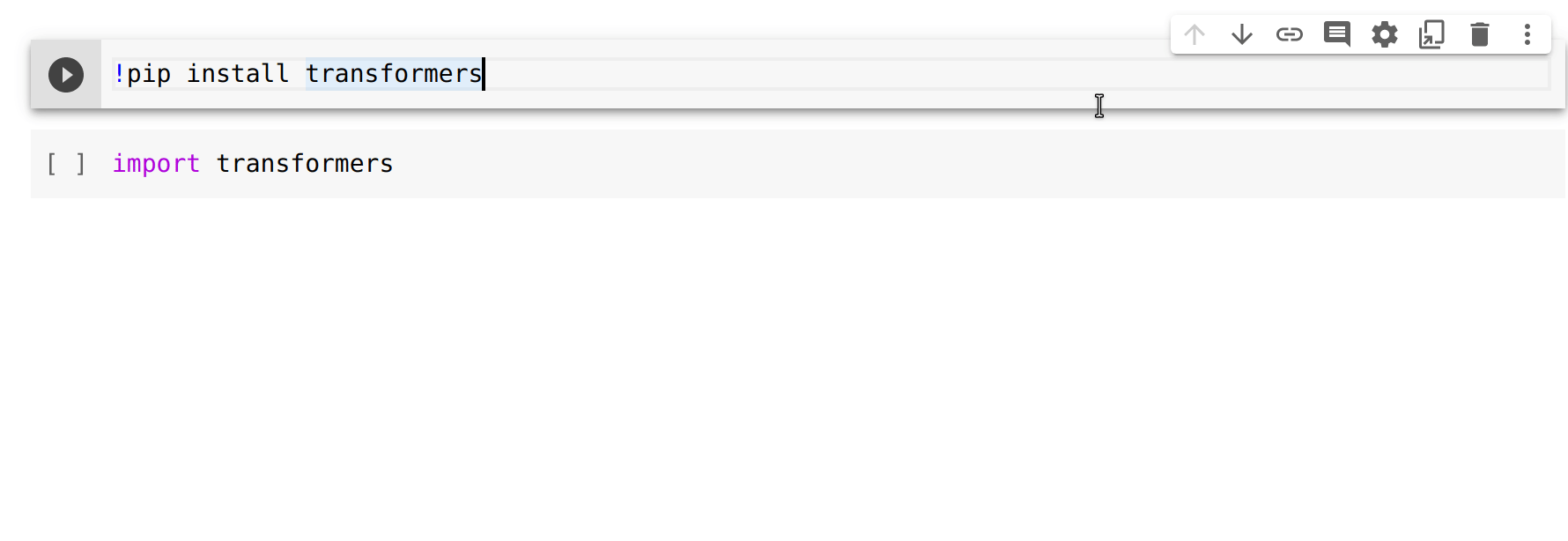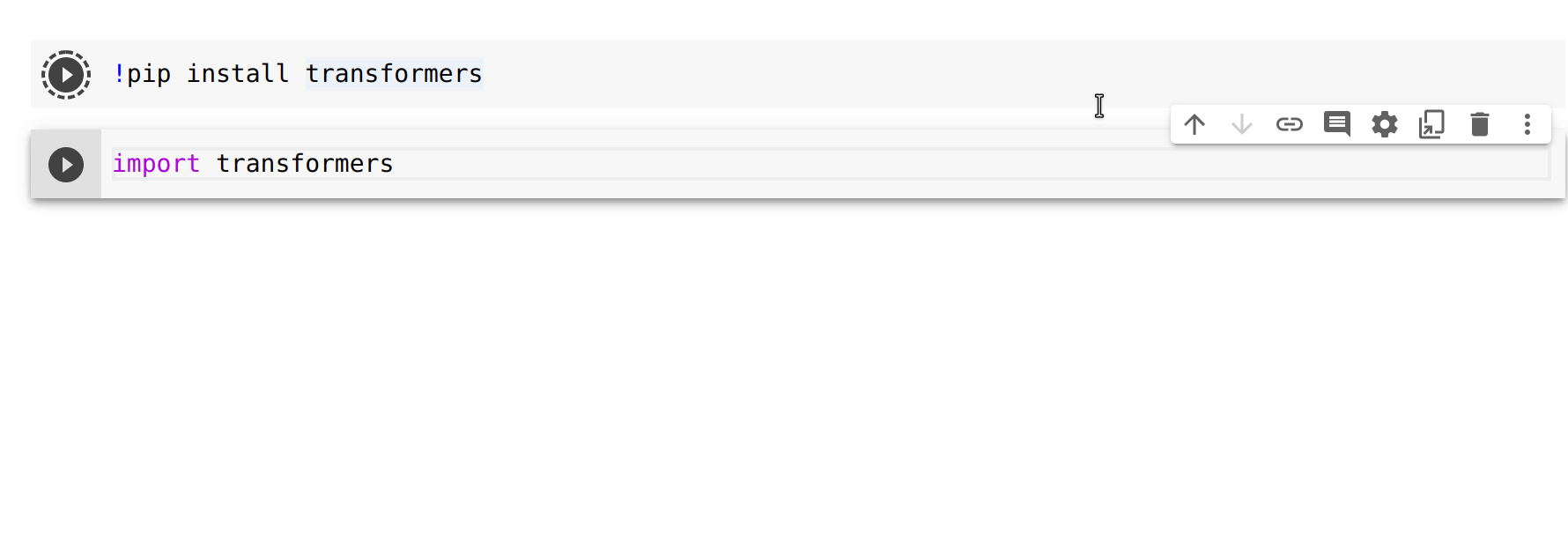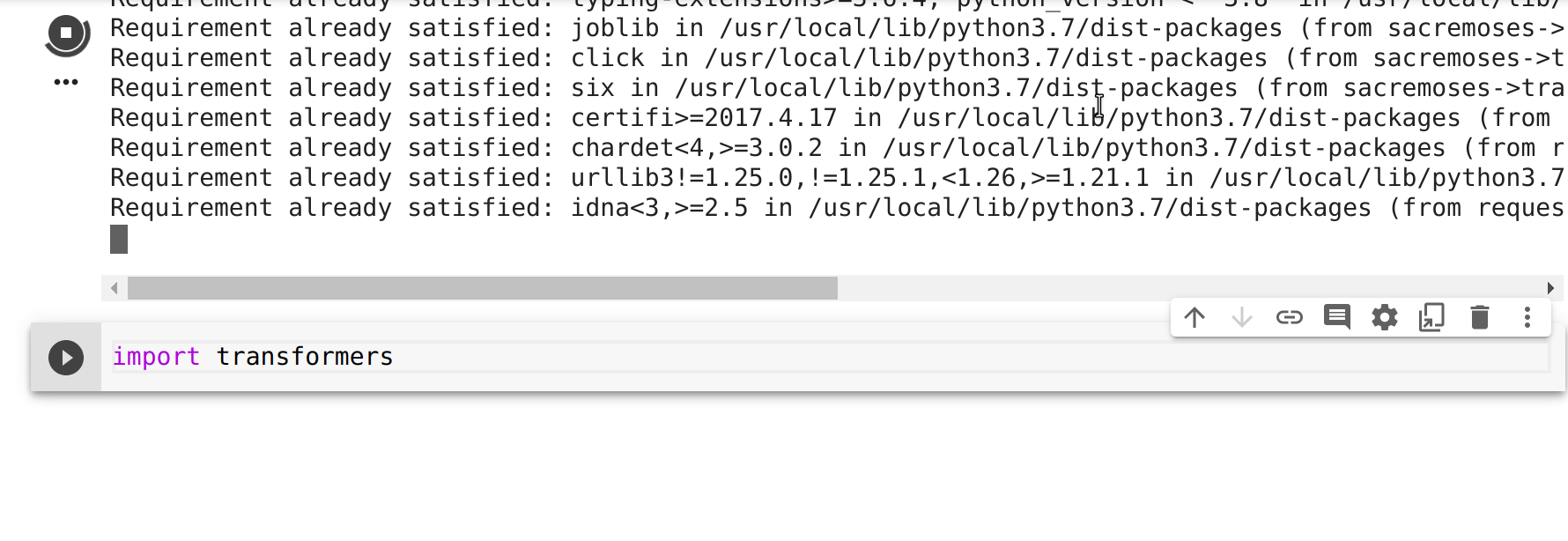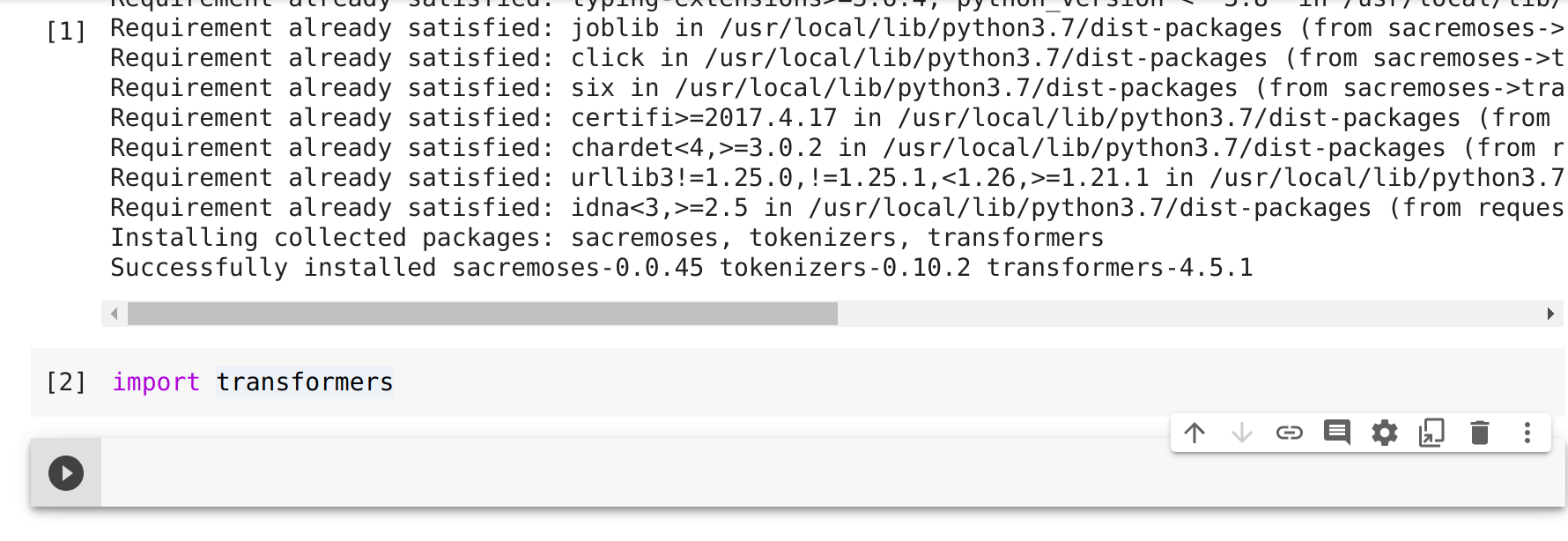
+Setelah terbiasa dengan Colab, buatlah notebook baru dengan setup sebagai berikut:
+
+
+
+
+
+
+

+

+