diff --git a/docs/source/en/_redirects.yml b/docs/source/en/_redirects.yml
index 0dd4d2bfb34b..b6575a6b02f2 100644
--- a/docs/source/en/_redirects.yml
+++ b/docs/source/en/_redirects.yml
@@ -1,3 +1,3 @@
# Optimizing inference
-perf_infer_gpu_many: perf_infer_gpu_one
\ No newline at end of file
+perf_infer_gpu_many: perf_infer_gpu_one
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 4e0ce88c10af..8516e7e1b5e3 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -60,7 +60,7 @@
- local: tasks/image_classification
title: Image classification
- local: tasks/semantic_segmentation
- title: Semantic segmentation
+ title: Image segmentation
- local: tasks/video_classification
title: Video classification
- local: tasks/object_detection
diff --git a/docs/source/en/tasks/semantic_segmentation.md b/docs/source/en/tasks/semantic_segmentation.md
index 2895a1977721..ce6fb70c8244 100644
--- a/docs/source/en/tasks/semantic_segmentation.md
+++ b/docs/source/en/tasks/semantic_segmentation.md
@@ -14,29 +14,17 @@ rendered properly in your Markdown viewer.
-->
-# Semantic segmentation
+# Image Segmentation
[[open-in-colab]]
-Semantic segmentation assigns a label or class to each individual pixel of an image. There are several types of segmentation, and in the case of semantic segmentation, no distinction is made between unique instances of the same object. Both objects are given the same label (for example, "car" instead of "car-1" and "car-2"). Common real-world applications of semantic segmentation include training self-driving cars to identify pedestrians and important traffic information, identifying cells and abnormalities in medical imagery, and monitoring environmental changes from satellite imagery.
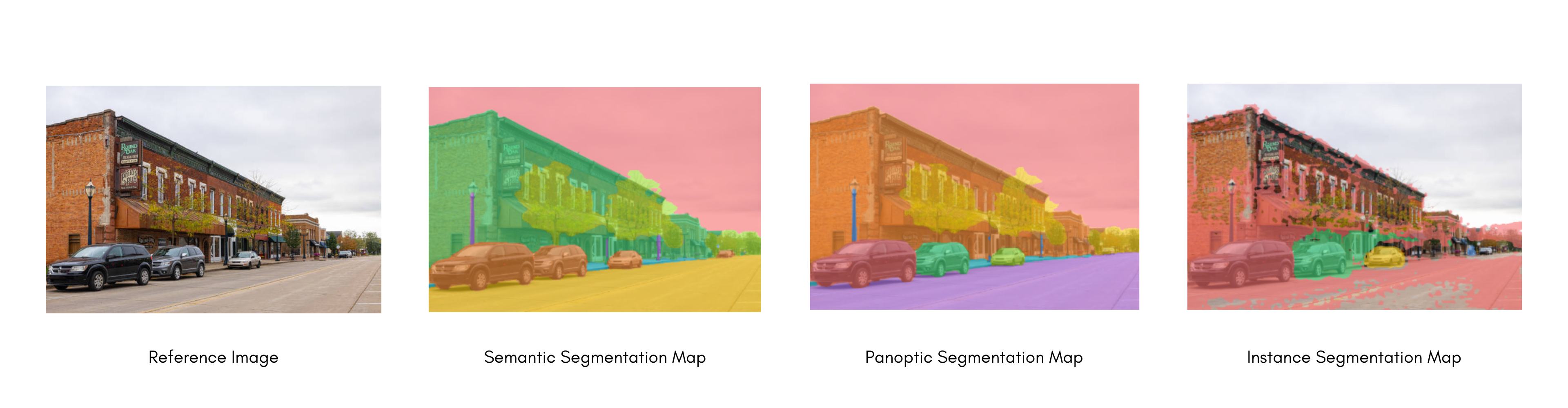
+Image segmentation models separate areas corresponding to different areas of interest in an image. These models work by assigning a label to each pixel. There are several types of segmentation: semantic segmentation, instance segmentation, and panoptic segmentation.
-This guide will show you how to:
-
-1. Finetune [SegFormer](https://huggingface.co/docs/transformers/main/en/model_doc/segformer#segformer) on the [SceneParse150](https://huggingface.co/datasets/scene_parse_150) dataset.
-2. Use your finetuned model for inference.
-
-
-The task illustrated in this tutorial is supported by the following model architectures:
-
-
-
-[BEiT](../model_doc/beit), [Data2VecVision](../model_doc/data2vec-vision), [DPT](../model_doc/dpt), [MobileNetV2](../model_doc/mobilenet_v2), [MobileViT](../model_doc/mobilevit), [MobileViTV2](../model_doc/mobilevitv2), [SegFormer](../model_doc/segformer), [UPerNet](../model_doc/upernet)
-
-
-
-
+In this guide, we will:
+1. [Take a look at different types of segmentation](#Types-of-Segmentation),
+2. [Have an end-to-end fine-tuning example for semantic segmentation](#Fine-tuning-a-Model-for-Segmentation).
Before you begin, make sure you have all the necessary libraries installed:
@@ -52,7 +40,178 @@ We encourage you to log in to your Hugging Face account so you can upload and sh
>>> notebook_login()
```
-## Load SceneParse150 dataset
+## Types of Segmentation
+
+Semantic segmentation assigns a label or class to every single pixel in an image. Let's take a look at a semantic segmentation model output. It will assign the same class to every instance of an object it comes across in an image, for example, all cats will be labeled as "cat" instead of "cat-1", "cat-2".
+We can use transformers' image segmentation pipeline to quickly infer a semantic segmentation model. Let's take a look at the example image.
+
+```python
+from transformers import pipeline
+from PIL import Image
+import requests
+
+url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/segmentation_input.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+image
+```
+
+
+

+
+

+
+

+
+
+