diff --git a/docs/source/en/model_doc/tvp.md b/docs/source/en/model_doc/tvp.md
index 1e733db6c8cb..22b400a06c73 100644
--- a/docs/source/en/model_doc/tvp.md
+++ b/docs/source/en/model_doc/tvp.md
@@ -23,9 +23,9 @@ The abstract from the paper is the following:
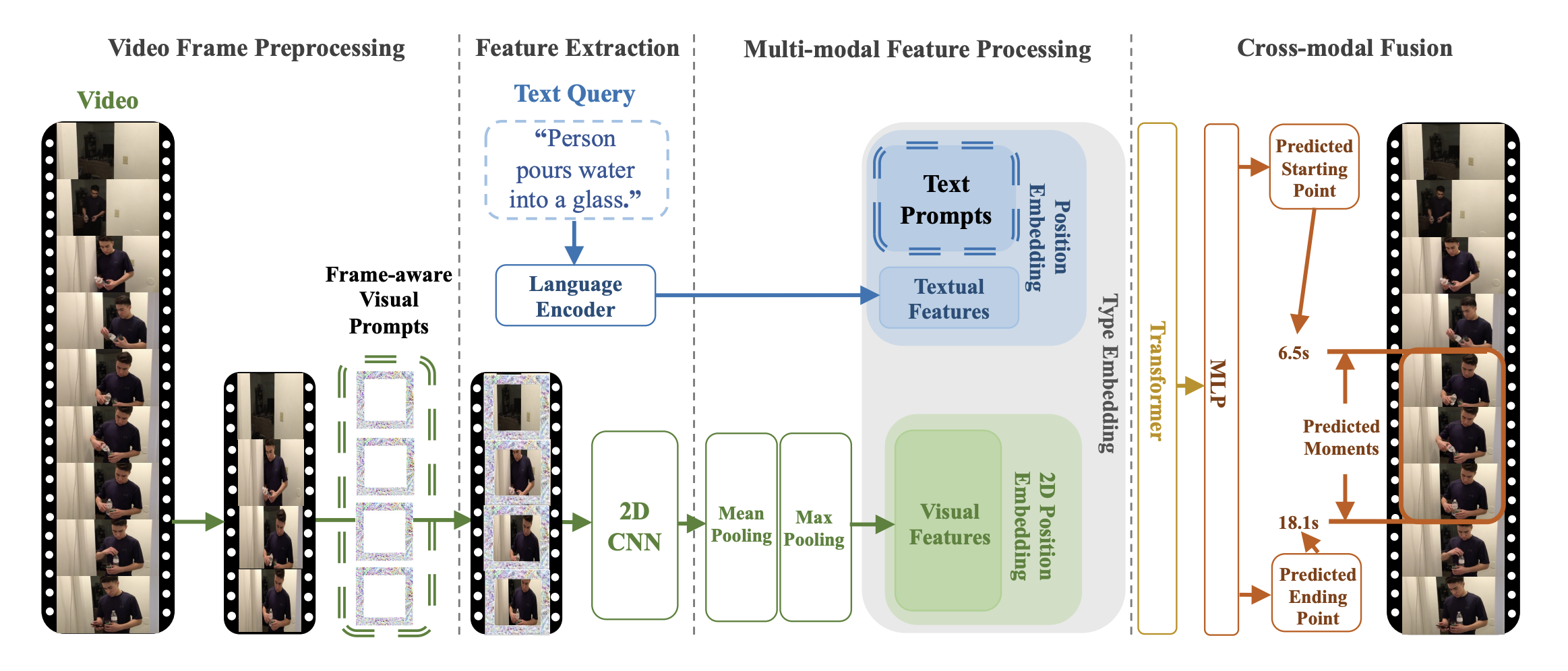
This research addresses temporal video grounding (TVG), which is the process of pinpointing the start and end times of specific events in a long video, as described by a text sentence. Text-visual prompting (TVP), is proposed to enhance TVG. TVP involves integrating specially designed patterns, known as 'prompts', into both the visual (image-based) and textual (word-based) input components of a TVG model. These prompts provide additional spatial-temporal context, improving the model's ability to accurately determine event timings in the video. The approach employs 2D visual inputs in place of 3D ones. Although 3D inputs offer more spatial-temporal detail, they are also more time-consuming to process. The use of 2D inputs with the prompting method aims to provide similar levels of context and accuracy more efficiently.
 +alt="drawing" width="600"/>
- TVP architecture. Taken from the original paper.
+ TVP architecture. Taken from the original paper.
This model was contributed by [Jiqing Feng](https://huggingface.co/Jiqing). The original code can be found [here](https://github.com/intel/TVP).
@@ -183,4 +183,4 @@ Tips:
## TvpForVideoGrounding
[[autodoc]] TvpForVideoGrounding
- - forward
\ No newline at end of file
+ - forward
+alt="drawing" width="600"/>
- TVP architecture. Taken from the original paper.
+ TVP architecture. Taken from the original paper.
This model was contributed by [Jiqing Feng](https://huggingface.co/Jiqing). The original code can be found [here](https://github.com/intel/TVP).
@@ -183,4 +183,4 @@ Tips:
## TvpForVideoGrounding
[[autodoc]] TvpForVideoGrounding
- - forward
\ No newline at end of file
+ - forward