lr_find suggestion ignores lr steps #14248
Description
🐛 Bug
lr_find computes suggestions using np.gradient() but only provides the array of losses, ignoring the lr at which each loss was computed. As such, np.gradient() assumes homogenous stepping size, which is not true when using exponential mode, which is the default mode.
This is visible here: https://github.com/Lightning-AI/lightning/blob/acd4805f1a284e513272d150de6f98f27a0489b3/src/pytorch_lightning/tuner/lr_finder.py#L201
Which is executed irrespective of the mode.
Possible fix of suggestion() in lr_finder.py (I'm not addressing the already present TODO):
losses = np.array(self.results["loss"][skip_begin:-skip_end])
losses = losses[np.isfinite(losses)]
lrs = np.array(self.results["lr"][skip_begin:-skip_end])
lrs = losses[np.isfinite(losses)]
if len(losses) < 2:
# computing np.gradient requires at least 2 points
log.error(
"Failed to compute suggestion for learning rate because there are not enough points. Increase the loop"
" iteration limits or the size of your dataset/dataloader."
)
self._optimal_idx = None
return None
# TODO: When computing the argmin here, and some losses are non-finite, the expected indices could be
# incorrectly shifted by an offset
# Kotchin's note: simulatneous attempt at addressing the TODO
min_grad = np.gradient(losses, lrs).argmin()
self._optimal_idx = np.arange(len(self.results["loss"]))[skip_begin:-skip_end][np.isfinite(losses)][min_grad]
return self.results["lr"][self._optimal_idx]
To Reproduce
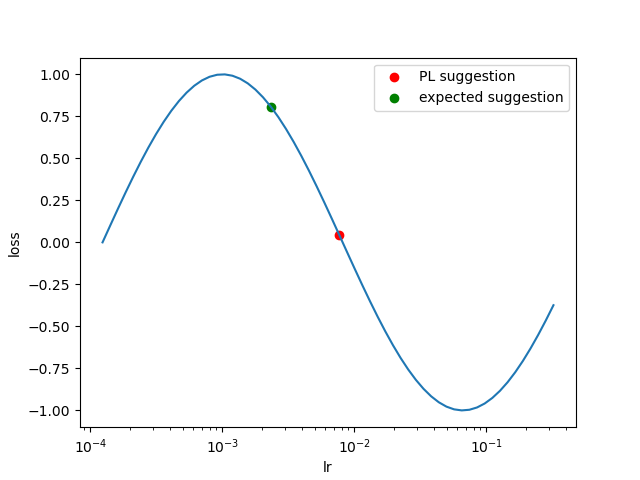
It's trivial, but here's a minimal code to highlight how this matters:
import matplotlib.pyplot as plt
import numpy as np
losses = np.sin(np.arange(0, 6, 0.1))
lrs = np.exp(np.arange(-9, -1, (-1 - -9)/len(losses)))
plt.plot(lrs, losses)
min_grad_pl = np.gradient(losses).argmin() # Current PL implementation
plt.scatter(lrs[min_grad_pl], losses[min_grad_pl], c='red', label='PL suggestion')
min_grad = np.gradient(losses, lrs).argmin() # Expected PL implementation
plt.scatter(lrs[min_grad], losses[min_grad], c='green', label='expected suggestion')
plt.xscale('log')
plt.legend()
plt.xlabel('lr')
plt.ylabel('loss')
plt.show()
Executing the code below will yield the follow illustration which should highlight the issue:
Expected behavior
Yield the correct lr suggestion, accounting for the non-homogeneous lr steps.
Environment
pytorch-lightning 1.7.1
python 3.10.4
Additional context
EDIT: added code suggestion placement detail.
EDIT2: Attempt at addressing the TODO in the suggestion() function.