- DQN
- Vanilla policy Gradient
- Deep Deterministic Policy Gradient
- Twin Delayed Deep Deterministic Policy Gradient
- Soft Actor Critic
- Proximal Policy Optimization - CLIP
Article on deeper Look into policy gradients
| Algorithm | Discrete Env: LunarLander-v2 | Continuous Env: Pendulum-v0 |
|---|---|---|
| DQN | 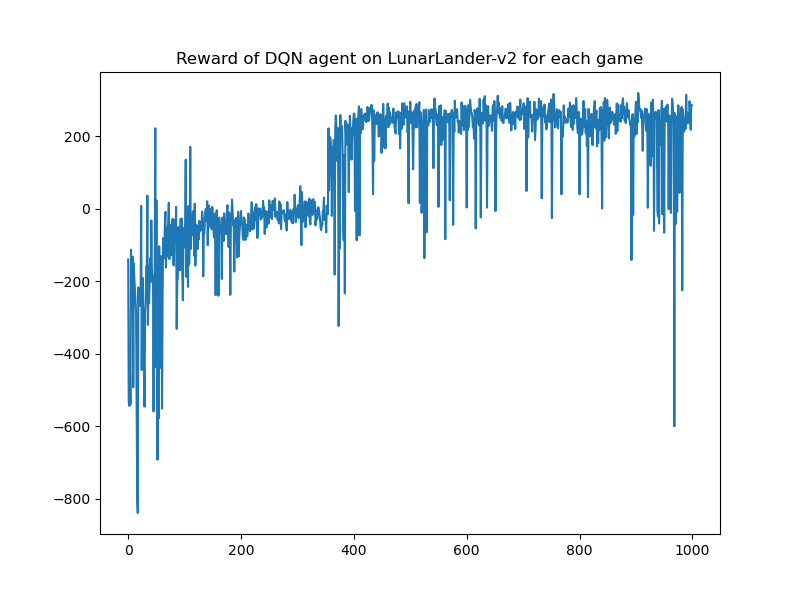 |
- |
| VPG | 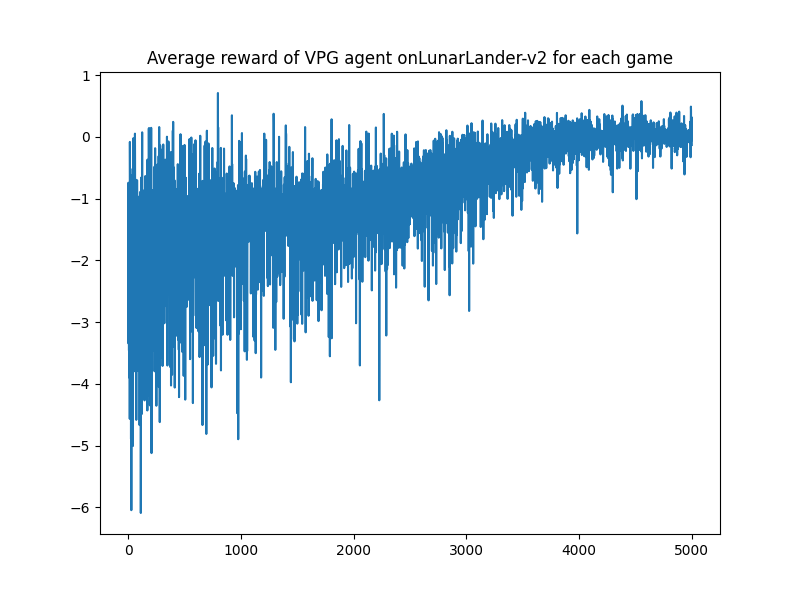 |
- |
| DDPG | - | 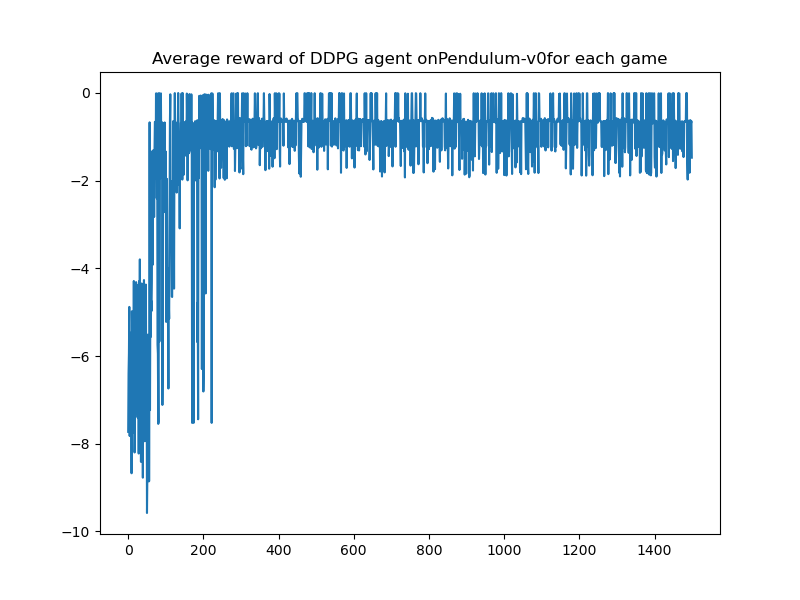 |
| TD3 | - | 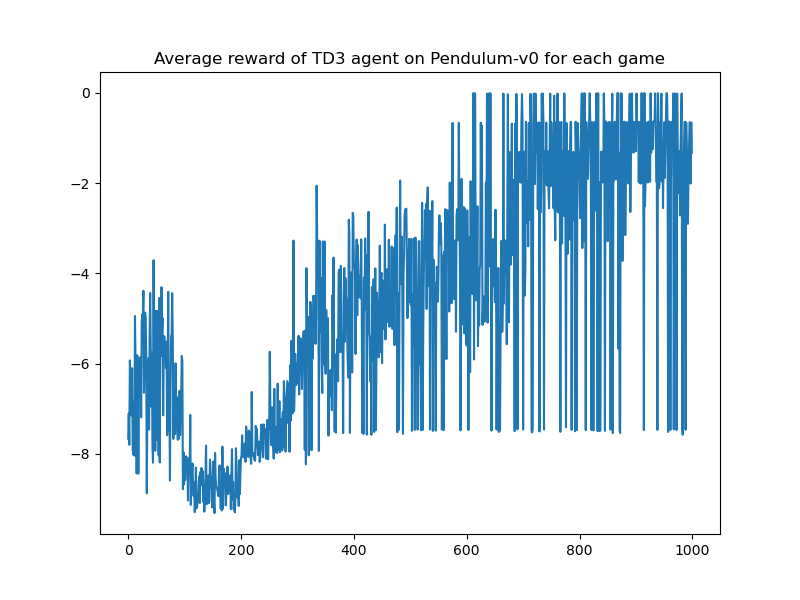 |
| SAC | - | 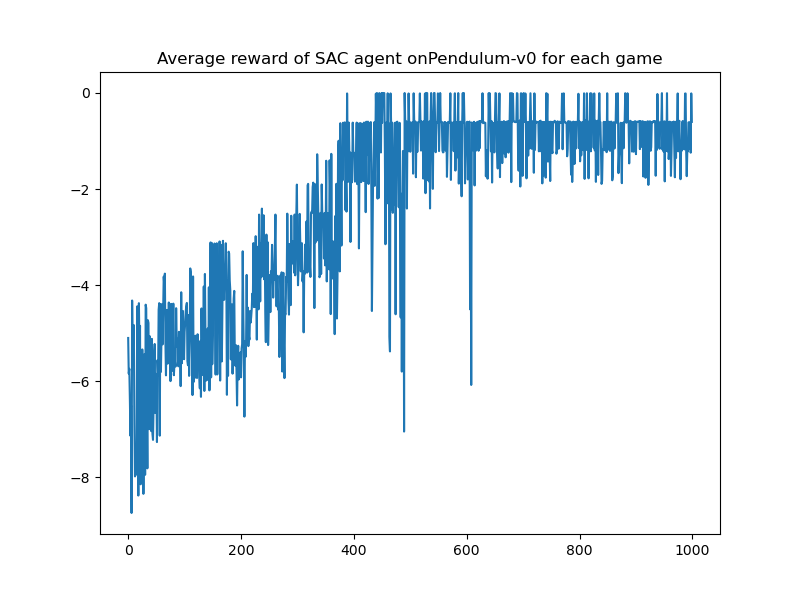 |
| PPO | - | 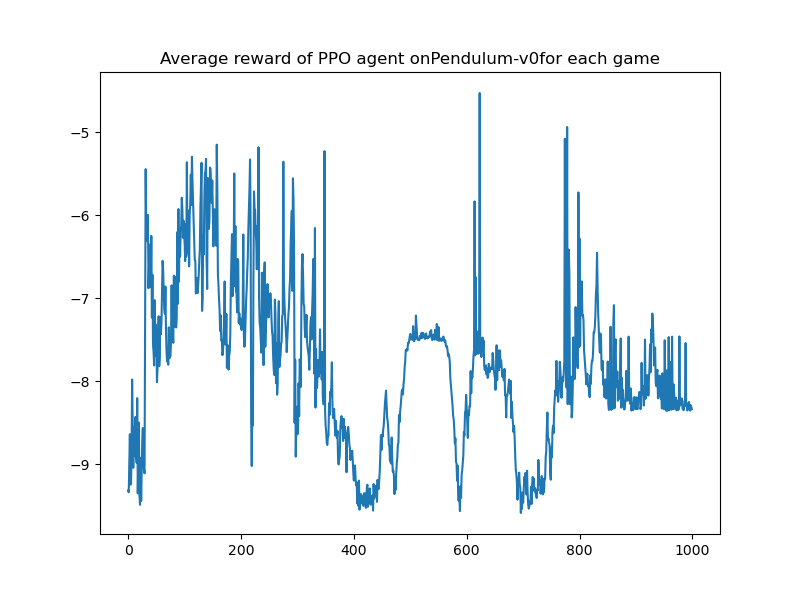 |
- RL course by David Silver
- Lecture slides for above course
- Spinning up by OpenAI
- More exhaustive RL guide by Deeny Britz
Prerequisites:
Setup:
-
Clone the repository:
git clone https://github.com/akashe/DeepReinforcementLearning.git cd DeepReinforcementLearning -
Set up Python environment:
# Option A: Using pyenv (recommended) pyenv install 3.8.10 pyenv local 3.8.10 # Option B: Using system Python 3.8+ # Make sure you have Python 3.8+ installed
-
Install system dependencies (for Box2D environments like LunarLander):
# macOS: brew install swig # Ubuntu/Debian: sudo apt-get install swig # Other systems: install swig through your package manager
-
Create and activate virtual environment:
python -m venv venv source venv/bin/activate # On Windows: venv\Scripts\activate
-
Install Python dependencies:
pip install -r requirements.txt
Just run the file/algorithm directly. There is no common structures between algorithms as I implemented them as I learnt them. Different algorithms are inspired from different sources.
Examples:
python ddpg.py # Run DDPG on Pendulum-v1
python DQN.py # Run DQN on LunarLander-v2
python td3.py # Run TD3 on Pendulum-v1
python SoftActorCritic.py # Run SAC on Pendulum-v1