{kind=link}
The code for the paper: Intra-Layer Recurrence in Transformers for Language Modeling
Anthony Nguyen, Wenjun Lin
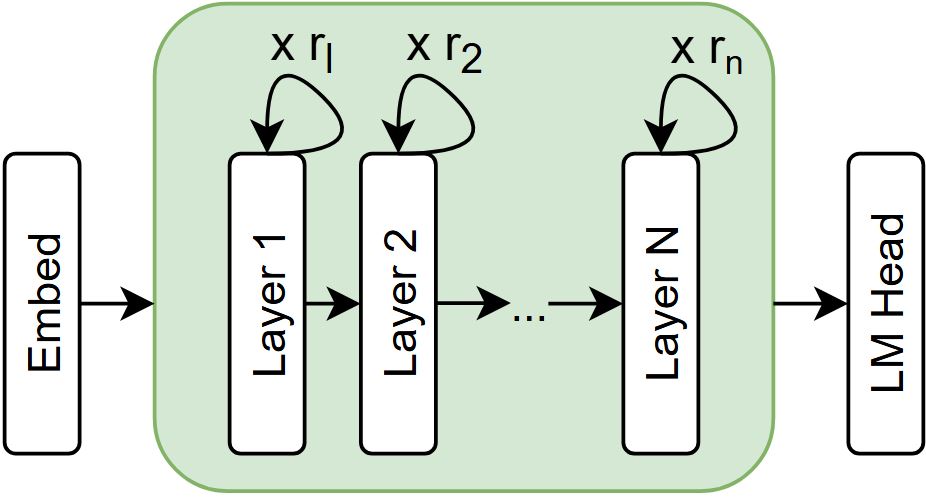
Transformer models have established new benchmarks in natural language processing; however, their increasing depth results in substantial growth in parameter counts. While existing recurrent transformer methods address this issue by reprocessing layers multiple times, they often apply recurrence indiscriminately across entire blocks of layers. In this work, we investigate Intra-Layer Recurrence (ILR), a more targeted approach that applies recurrence selectively to individual layers within a single forward pass. Our experiments show that allocating more iterations to earlier layers yields optimal results. These findings suggest that ILR offers a promising direction for optimizing recurrent structures in transformer architectures.
| Recurrence Strategy | Reuse Map | Model Size | NoPE | RoPE | Learned | ALiBi |
|---|---|---|---|---|---|---|
| Baseline (No recurrence) | – | Small | 16.57 | 15.56 | 14.98 | 14.38 |
| Block Recurrence (r = 2) | – | Small | 15.29 | 14.27 | 14.27 | 14.23 |
| ILR | [2, 1, 1, 1] | Small | 15.17 | 14.4 | 14.42 | 14.32 |
| ILR | [1, 2, 1, 1] | Small | 15.14 | 13.93 | 14.39 | 14.2 |
| ILR | [1, 1, 2, 1] | Small | 16.54 | 14.13 | 14.54 | 14.34 |
| ILR | [1, 1, 1, 2] | Small | 16.98 | 15.12 | 14.84 | 14.65 |
| ILR | [1, 1, 2, 4] | Small | 17.54 | 14.24 | 14.66 | 14.25 |
| ILR | [1, 2, 2, 3] | Small | 15.59 | 13.96 | 14.25 | 14.13 |
| ILR | [2, 2, 2, 2] | Small | 15.07 | 14.15 | 14.17 | 13.76 |
| ILR | [3, 2, 2, 1] | Small | 14.62 | 13.92 | 14.37 | 13.73 |
| ILR | [4, 2, 1, 1] | Small | 14.64 | 13.77 | 14.28 | 13.63 |
| Recurrence Strategy | Reuse Map | Model Size | NoPE | RoPE | Learned | ALiBi |
|---|---|---|---|---|---|---|
| Baseline (No recurrence) | – | Large | 18.09 | 16.77 | 17.64 | 17.16 |
| ILR | [1, 2, 1, ..., 1] | Large | 17.97 | 16.64 | 17.54 | 16.98 |
Perplexity results for different reuse maps in small and large-scale models (tested on sequence length of 1024). Lower is better (best in bold).
Pretokenized datasets are uploaded to this HF repository. Make sure to change tokenized_dataset_path in experiment configs to wherever these are stored.
Install the required dependencies:
pip install -r requirements.txtWe use Weights & Biases for logging. Before running any experiments, make sure to log in:
wandb loginExperiment configuration files are located in:
./experiment_setups/
To run an experiment:
python run_experiment.py --config ./experiment_setups/[CONFIG].jsonYou can also specify a device with the --device flag:
python run_experiment.py --config ./experiment_setups/example.json --device cuda:0Contains a modified version of the LLaMa architecture that supports Intra-Layer Recurrence (ILR).
from looped_llama_configuration import LoopedLlamaConfig
from modeling_llama import LoopedLlamaForCausalLM
config = LoopedLlamaConfig(
hidden_size=256,
num_hidden_layers=4,
num_attention_heads=4,
loop_map=[3, 2, 2, 1],
vocab_size=32000,
max_position_embeddings=1024,
tie_word_embeddings=True,
_attn_implementation="eager",
positional_encoding="nope",
use_cache=False
)
model = LoopedLlamaForCausalLM(config)loop_mapcorresponds to the reuse map defined in the paper.
-
We conducted preliminary experiments on GPT-2-based architectures (implementation in
modeling_gpt2.py) and further alternative positional encodings (CoPE, FIRE), but these were incomplete due to time and resource constraints and were not included in the paper. -
Due to architectural changes, the default
generate()method from HF Transformers is not supported and has been overwritten with a naive implementation without KV-caching and only a temperature option for non-greedy sampling.
@article{Nguyen2025Intra,
author = {Nguyen, Anthony and Lin, Wenjun},
journal = {Proceedings of the Canadian Conference on Artificial Intelligence},
year = {2025},
month = {may 19},
note = {https://caiac.pubpub.org/pub/reqqqozg},
publisher = {Canadian Artificial Intelligence Association (CAIAC)},
title = {Intra-{Layer} {Recurrence} in {Transformers} for {Language} {Modeling}},
}