[SPARK-12552][Core]Correctly count the driver resource when recovering from failure for Master #10506
Conversation
|
Test build #48410 has finished for PR 10506 at commit
|
|
Jenkins, retest this please. |
|
Test build #48413 has finished for PR 10506 at commit
|
|
Can you add a unit test? You might have to mock the |
|
Sure, will do. |
|
Jenkins, retest this please. |
|
Test build #48463 has finished for PR 10506 at commit
|
|
@andrewor14 , would you please review this patch again, it is pending here a long time and I think it is actually a bug here. Thanks a lot. |
|
Test build #52223 has finished for PR 10506 at commit
|
|
Test build #52225 has finished for PR 10506 at commit
|
|
Thank you for your comment for PR #12054. I think changing app state from WAITING to RUNNING in function completeRecovery. Suppose that some app is WAITING before master toggle, then all apps and all workers get known of master changed. But if last signal (WorkerSchedulerStateResponse or MasterChangeAcknowledged) is from some worker, then function completeRecovery is revoked, which means the app I mentioned above is in RUNNING state. If the cluster doesn't have enough resource for all apps, maybe that app will be in a wrong state for a while. |
|
Is anyone still working on this and if not, can you close the PR? |
|
Hi @kayousterhout , I guess the issue still exists, but unfortunately there's no one reviewing this patch. I could rebase the code if someone could review it. |
|
OK fine to leave this open then (I don't have the time or expertise to review this unfortunately) |
|
Ping @zsxwing , hopes you're the right person to review this very old PR, the issue still exists in the latest master, can you please take a review, thanks a lot. |
|
Test build #73740 has finished for PR 10506 at commit
|
|
Test build #73742 has finished for PR 10506 at commit
|
|
I also don't feel like I know enough to review this, but if you're confident about the fix, i think you can go ahead. The change looks reasonable on its face. |
|
Thanks @srowen , I think the fix is OK, at least should be no worse than previous code. |
|
Could you rebase this? @jerryshao |
|
Sure, I will bring this to update. |
Change-Id: Iee06c055b42757611731f2e0b9419d6adf68d665
|
Test build #77627 has finished for PR 10506 at commit
|
| driver.worker = Some(worker) | ||
| driver.state = DriverState.RUNNING | ||
| worker.drivers(driverId) = driver | ||
| worker.addDriver(driver) |
There was a problem hiding this comment.
One major question(though I haven't tested this) -- Won't we call schedule() after we completed recovery? I think we will handle the resource change correctly there.
There was a problem hiding this comment.
From my understanding, schedule() will only handle waiting drivers, but here is trying to calculate the exiting drivers, so I don't think schedule() will save the issue here. Let me try to test on latest master and back to you the result.
| apps.filter(_.state == ApplicationState.UNKNOWN).foreach(finishApplication) | ||
|
|
||
| // Update the state of recovered apps to RUNNING | ||
| apps.filter(_.state == ApplicationState.WAITING).foreach(_.state = ApplicationState.RUNNING) |
There was a problem hiding this comment.
This should also been done later in schedule().
|
I think this problem shouldn't have happen in general case, could you give more specific description on your integrated cluster? |
|
@jiangxb1987 , to reproduce this issue, you can:
This is mainly because when Master recover Driver, Master don't count the resources (core/memory) used by Driver, so this part of resources are free, which will be used to allocate a new executor, when the application is finished, this over-occupied resource by new executor will make the worker resources to be negative. Besides, in the current Master, only when new executor is allocated, then application state will be changed to "RUNNING", recovered application will never have the chance to change the state from "WAITING" to "RUNNING" because there's no new executor allocated. Can you please take a try, this issue do exist and be reported in JIRA and mail list several times. |
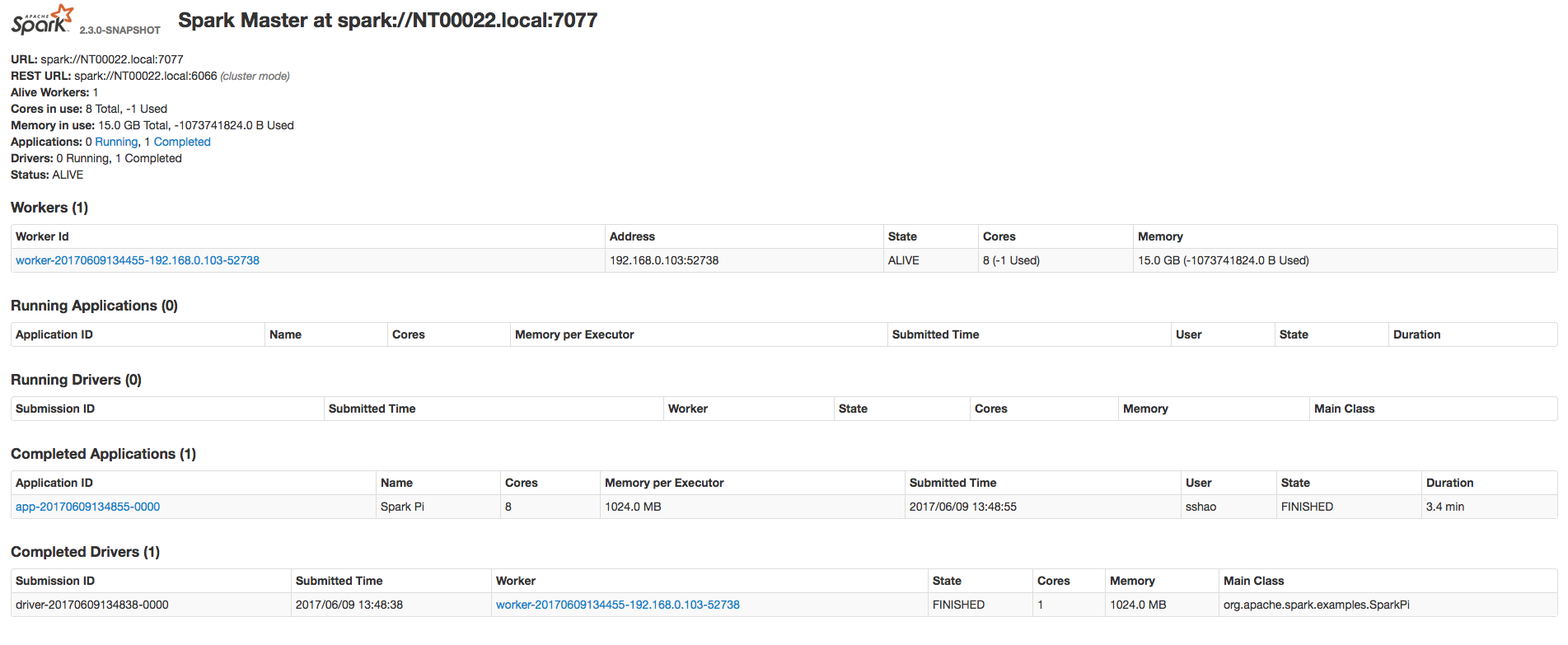
|
@jerryshao Thank you for your effort, I'll try this tomorrow! |
|
I think the fix is right and the test case also looks good, we'd better merge this after add some new test cases over the application running state issue. @cloud-fan Could please have a look too? |
|
BTW, @jerryshao It would be great if we can add test framework to verify the states and statistics on the condition of Driver/Executor Lost/Join/Relaunch, is there any hope that you would invest some time on that? |
@jiangxb1987 can you explain more about what you want? |
|
Currently we don't cover the Driver/Executor Lost/Relaunch cases in We don't need to do these in current PR, but it would be great if we can do as a follow up of this PR. |
| fakeWorkerInfo.coresFree should be(0) | ||
| fakeWorkerInfo.coresUsed should be(16) | ||
| // State of application should be RUNNING | ||
| fakeAppInfo.state should be(ApplicationState.RUNNING) |
There was a problem hiding this comment.
shall we also test these before the recovery? To show that we do change something when recovering
There was a problem hiding this comment.
Done, thanks for review.
|
LGTM |
Change-Id: I8eb01af5dc47cf57fcba459670704f481c3f8ac3
| master.self.send( | ||
| WorkerSchedulerStateResponse(fakeWorkerInfo.id, fakeExecutors, Seq(fakeDriverInfo.id))) | ||
|
|
||
| eventually(timeout(1 second), interval(10 milliseconds)) { |
There was a problem hiding this comment.
hmmm will this be flaky?
There was a problem hiding this comment.
Because RPC send is asynchronous, if we check the app state immediately after send we will possibly get "UNKNOWN" state instead of "WAITING".
|
|
||
| // If driver's resource is also counted, free cores should 0 | ||
| fakeWorkerInfo.coresFree should be(0) | ||
| fakeWorkerInfo.coresUsed should be(16) |
There was a problem hiding this comment.
we can also test these 2 before recovering
Change-Id: Ibe18dc34d629aca0bf2c1f405b8500ded9ce5b04
|
Test build #77976 has finished for PR 10506 at commit
|
|
Test build #77985 has finished for PR 10506 at commit
|
|
Jenkins, retest this please. |
|
Test build #77990 has finished for PR 10506 at commit
|
…ng from failure for Master Currently in Standalone HA mode, the resource usage of driver is not correctly counted in Master when recovering from failure, this will lead to some unexpected behaviors like negative value in UI. So here fix this to also count the driver's resource usage. Also changing the recovered app's state to `RUNNING` when fully recovered. Previously it will always be WAITING even fully recovered. andrewor14 please help to review, thanks a lot. Author: jerryshao <[email protected]> Closes #10506 from jerryshao/SPARK-12552. (cherry picked from commit 9eb0952) Signed-off-by: Wenchen Fan <[email protected]>
|
thanks, merging to master/2.2! The fix is only 2 lines so should be safe to backport |
…ng from failure for Master Currently in Standalone HA mode, the resource usage of driver is not correctly counted in Master when recovering from failure, this will lead to some unexpected behaviors like negative value in UI. So here fix this to also count the driver's resource usage. Also changing the recovered app's state to `RUNNING` when fully recovered. Previously it will always be WAITING even fully recovered. andrewor14 please help to review, thanks a lot. Author: jerryshao <[email protected]> Closes apache#10506 from jerryshao/SPARK-12552.
Currently in Standalone HA mode, the resource usage of driver is not correctly counted in Master when recovering from failure, this will lead to some unexpected behaviors like negative value in UI.
So here fix this to also count the driver's resource usage.
Also changing the recovered app's state to
RUNNINGwhen fully recovered. Previously it will always be WAITING even fully recovered.@andrewor14 please help to review, thanks a lot.