[SPARK-16217][SQL] Support SELECT INTO statement #14191
There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -1376,4 +1376,62 @@ class SparkSqlAstBuilder(conf: SQLConf) extends AstBuilder { | |
| reader, writer, | ||
| schemaLess) | ||
| } | ||
|
|
||
| /** | ||
| * Reuse CTAS, convert select into to CTAS, | ||
| * returning [[CreateHiveTableAsSelectLogicalPlan]]. | ||
| * The SELECT INTO statement selects data from one table | ||
| * and inserts it into a new table.It is commonly used to | ||
| * create a backup copy for table or selected records. | ||
| * | ||
| * Expected format: | ||
| * {{{ | ||
| * SELECT column_name(s) | ||
| * INTO new_table | ||
| * FROM old_table | ||
| * ... | ||
| * }}} | ||
| */ | ||
| override protected def withSelectInto( | ||
|
There was a problem hiding this comment. The code below is duplicate. Why are we not using the existing CTAS code path? There was a problem hiding this comment. @hvanhovell Reusing CTAS code path means we need to convert IntoClauseContext to CreateTableContext (or construct a new CreateTableContext),it might be difficult to archive. Maybe there is another way? |
||
| ctx: IntoClauseContext, | ||
| query: LogicalPlan): LogicalPlan = withOrigin(ctx) { | ||
| // Storage format | ||
| val defaultStorage: CatalogStorageFormat = { | ||
| val defaultStorageType = conf.getConfString("hive.default.fileformat", "textfile") | ||
| val defaultHiveSerde = HiveSerDe.sourceToSerDe(defaultStorageType, conf) | ||
| CatalogStorageFormat( | ||
| locationUri = None, | ||
| inputFormat = defaultHiveSerde.flatMap(_.inputFormat) | ||
| .orElse(Some("org.apache.hadoop.mapred.TextInputFormat")), | ||
| outputFormat = defaultHiveSerde.flatMap(_.outputFormat) | ||
| .orElse(Some("org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat")), | ||
| // Note: Keep this unspecified because we use the presence of the serde to decide | ||
| // whether to convert a table created by CTAS to a datasource table. | ||
| serde = None, | ||
| compressed = false, | ||
| serdeProperties = Map()) | ||
| } | ||
| // TODO support the sql text - have a proper location for this! | ||
| val tableDesc = CatalogTable( | ||
| identifier = visitTableIdentifier(ctx.tableIdentifier), | ||
| tableType = CatalogTableType.MANAGED, | ||
| storage = defaultStorage, | ||
| schema = Nil | ||
| ) | ||
|
|
||
| // Table shouldn't exist | ||
| if (conf.convertCTAS) { | ||
| CreateTableUsingAsSelect( | ||
| tableIdent = tableDesc.identifier, | ||
| provider = conf.defaultDataSourceName, | ||
| partitionColumns = Array(), | ||
| bucketSpec = None, | ||
| mode = SaveMode.ErrorIfExists, | ||
| options = Map.empty[String, String], | ||
| query | ||
| ) | ||
| } else { | ||
| CreateHiveTableAsSelectLogicalPlan(tableDesc, query, false) | ||
| } | ||
| } | ||
| } | ||
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
It is easier to just put this in the
querySpecificationrule. Make sure you given the tableIdentifier a proper nameThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Could you also check what kind of a plan the following query produces:
We might run into a weird syntax error here. If we do then we need to move the
INTOkeyword from thenonReservedrule to theidentifierrule.Uh oh!
There was an error while loading. Please reload this page.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
@hvanhovell

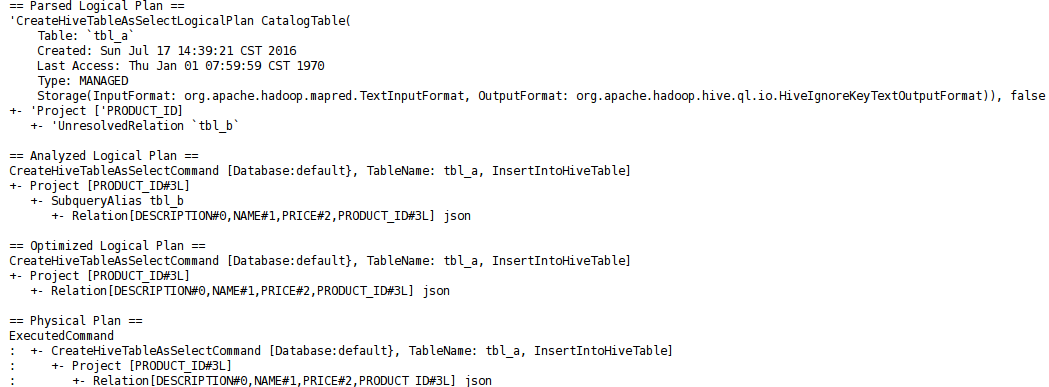
For example, the json data registed as table tbl_b is:
The Logical Plan of sql "SELECT PRODUCT_ID INTO tbl_a FROM tbl_b" is:
The results match the expectations