[SPARK-20393][WEBU UI][1.6] Strengthen Spark to prevent XSS vulnerabilities #19528
Conversation
…6 branch from the merge of SPARK-20393
 dongjoon-hyun
left a comment
dongjoon-hyun
left a comment
There was a problem hiding this comment.
Hi, @ambauma .
Thank you for contributing.
- SPARK-20393 should be backported branch-2.0 first.
- PR titles should be the same with the original one except the version numbers.
[SPARK-20393][WEBU UI][2.0] Strengthen Spark to prevent XSS vulnerabilities
[SPARK-20393][WEBU UI][1.6] Strengthen Spark to prevent XSS vulnerabilities
|
Understood. Working on porting to 2.0... |
|
I don't think there are any more 1.x releases coming, and doubt there are more 2.0.x releases. Do you really need this in Spark or is it something you can apply to your own release branch? |
|
I have a release in my fork for my immediate needs. However, Spark 1.6 is still included in Hortonworks and is default in Cloudera. This patch addresses CVE-2017-7678. Some companies in strict regulatory environments may fail audits and be forced to remove Spark 1.6 if it is not patched. Rather than keeping security patches in forks, I think it makes sense to merge them back into the official branch for branches that are still in active use. That way if I get hit by a bus and CVE-2018-XXXX comes out, CVE-2017-7678 will already be covered and the work will not need to be duplicated. |
|
(Spark 1.x is legacy in Cloudera, but, it has its own 1.x branch anyway) |
|
I just posted the 2.0 pull request. #19538 |
|
Test build #3955 has finished for PR 19528 at commit
|
|
Working on duplicating PySpark failures... |
|
Able to duplicate. Working theory is that this is related to numpy 1.12.1. Here is my conda env: ca-certificates 2017.08.26 h1d4fec5_0 |
…n LogisticRegressionModel ## What changes were proposed in this pull request? Fixed TypeError with python3 and numpy 1.12.1. Numpy's `reshape` no longer takes floats as arguments as of 1.12. Also, python3 uses float division for `/`, we should be using `//` to ensure that `_dataWithBiasSize` doesn't get set to a float. ## How was this patch tested? Existing tests run using python3 and numpy 1.12. Author: Bago Amirbekian <[email protected]> Closes apache#18081 from MrBago/BF-py3floatbug.
|
Believed fixed. Hard to say for sure without knowing the precise python and numpy versions the build is using. |
|
|
||
| package org.apache.spark.ui.jobs | ||
|
|
||
| import javax.servlet.http.HttpServletRequest |
There was a problem hiding this comment.
Hm, I'm not sure if this back-port is correct. This file's change doesn't look like it does anything and I don't see this change in the original: https://github.com/apache/spark/pull/17686/files
| @@ -0,0 +1,180 @@ | |||
| /* | |||
There was a problem hiding this comment.
Likewise this isn't part of the backport is it? https://github.com/apache/spark/pull/17686/files
There was a problem hiding this comment.
I'm not sure what I did to make this whole file look new, but I've copied the 1.6 current and reapplied stripXSS locally. Waiting for my build to pass to commit again.
| self._weightsMatrix = None | ||
| else: | ||
| self._dataWithBiasSize = self._coeff.size / (self._numClasses - 1) | ||
| self._dataWithBiasSize = self._coeff.size // (self._numClasses - 1) |
There was a problem hiding this comment.
I had to apply this to get past a python unit test failure. My assumption is that the NewSparkPullRequestBuilder is on a different version of numpy than when the Spark 1.6 branch was last built. The current python unit test failure looks like it has to do with a novel version of SciPy.
There was a problem hiding this comment.
This is already fixed in the 2.0 branch, btw. Just was never applied to 1.6. [SPARK-20862]
|
Test build #3958 has finished for PR 19528 at commit
|
|
|
||
| import scala.collection.mutable.{HashMap, ListBuffer} | ||
| import scala.xml._ | ||
| import scala.collection.JavaConverters._ |
|
Jenkins, retest this please |
|
Test build #82990 has finished for PR 19528 at commit
|
|
I'm unable to duplicate the PySpark failures locally. I assume I need a specific version of SciPy to duplicate the error. Is there a way I could get what versions the build server is running? Something like: |
|
@shaneknapp - could you help check - what version of SciPy Jenkins is running with? thanks! |
|
python2.7: 0.17.0 |
|
ok to test |
|
Jenkins test this please |
|
Test build #86410 has started for PR 19528 at commit |
|
retest this please |
|
Test build #4149 has finished for PR 19528 at commit
|
|
retest this please |
|
Jenkins test this please |
|
Test build #91690 has started for PR 19528 at commit |
|
retest this please |
|
Test build #93074 has started for PR 19528 at commit |
|
retest this please |
|
Test build #93094 has finished for PR 19528 at commit
|
|
Can one of the admins verify this patch? |
What changes were proposed in this pull request?
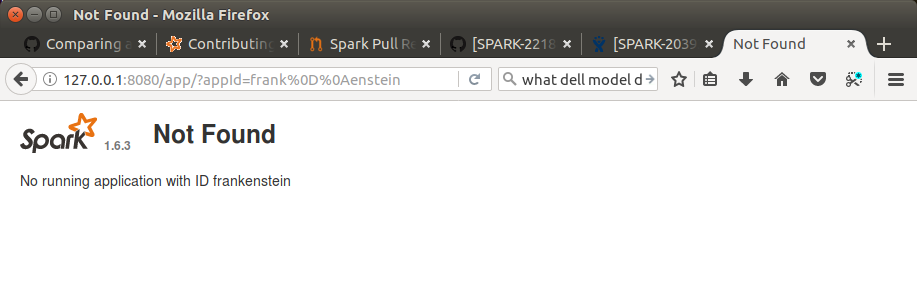
This is the fix for the master branch applied to the 1.6 branch. My (unnamed) company will be using Spark 1.6 probably for another year. We have been blocked from having Spark 1.6 on our workstations until CVE-2017-7678 is patched, which SPARK-20393 does. I realize there will not be an official Spark 1.6.4 release, but it still seems wise to keep the code there patched for those who are stuck on that version. Otherwise I imagine several forks duplicating 1.6 compliance and security fixes.
How was this patch tested?
The patch came with unit tests. The test build passed. Manual testing on one of the effected screens showed the newline character removed. Screen display was the same regardless (html ignores newline characters).
Please review http://spark.apache.org/contributing.html before opening a pull request.
The patch itself is from previous pull requests associated to SPARK-20939. My original "work" was actions on what to apply to branch 1.6. and I license the work to the project under the project’s open source license.