[SPARK-17091][SQL] Add rule to convert IN predicate to equivalent Parquet filter #21603
Conversation
| case sources.Not(pred) => | ||
| createFilter(schema, pred).map(FilterApi.not) | ||
|
|
||
| case sources.In(name, values) if canMakeFilterOn(name) && values.length < 20 => |
There was a problem hiding this comment.
The threshold is 20. Too many values may be OOM, for example:
spark.range(10000000).coalesce(1).write.option("parquet.block.size", 1048576).parquet("/tmp/spark/parquet/SPARK-17091")
val df = spark.read.parquet("/tmp/spark/parquet/SPARK-17091/")
df.where(s"id in(${Range(1, 10000).mkString(",")})").countException in thread "SIGINT handler" 18/06/21 13:00:54 WARN TaskSetManager: Lost task 7.0 in stage 1.0 (TID 8, localhost, executor driver): java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOfRange(Arrays.java:3664)
at java.lang.String.<init>(String.java:207)
at java.lang.StringBuilder.toString(StringBuilder.java:407)
at org.apache.parquet.filter2.predicate.Operators$BinaryLogicalFilterPredicate.<init>(Operators.java:263)
at org.apache.parquet.filter2.predicate.Operators$Or.<init>(Operators.java:316)
at org.apache.parquet.filter2.predicate.FilterApi.or(FilterApi.java:261)
at org.apache.spark.sql.execution.datasources.parquet.ParquetFilters$$anonfun$createFilter$15.apply(ParquetFilters.scala:276)
at org.apache.spark.sql.execution.datasources.parquet.ParquetFilters$$anonfun$createFilter$15.apply(ParquetFilters.scala:276)
...
There was a problem hiding this comment.
what about making this threshold configurable?
There was a problem hiding this comment.
make it configurable. Use spark.sql.parquet.pushdown.inFilterThreshold. By default, it should be around 10. Please also check the perf.
cc @jiangxb1987
There was a problem hiding this comment.
It seems that the push-down performance is better when threshold is less than 300:
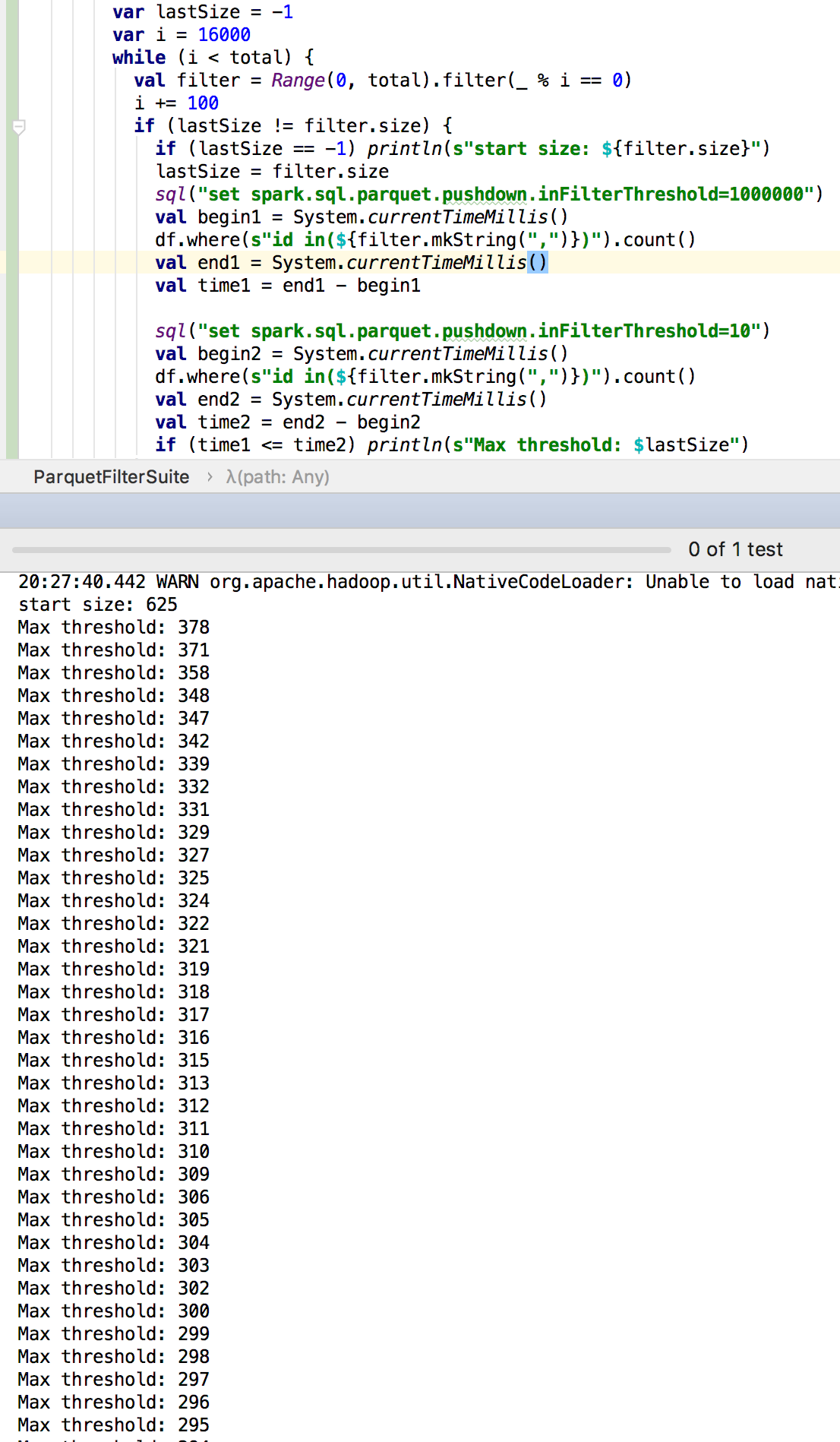
The code:
withSQLConf(SQLConf.PARQUET_FILTER_PUSHDOWN_ENABLED.key -> "true") {
import testImplicits._
withTempPath { path =>
val total = 10000000
(0 to total).toDF().coalesce(1)
.write.option("parquet.block.size", 512)
.parquet(path.getAbsolutePath)
val df = spark.read.parquet(path.getAbsolutePath)
// scalastyle:off println
var lastSize = -1
var i = 16000
while (i < total) {
val filter = Range(0, total).filter(_ % i == 0)
i += 100
if (lastSize != filter.size) {
if (lastSize == -1) println(s"start size: ${filter.size}")
lastSize = filter.size
sql("set spark.sql.parquet.pushdown.inFilterThreshold=1000000")
val begin1 = System.currentTimeMillis()
df.where(s"id in(${filter.mkString(",")})").count()
val end1 = System.currentTimeMillis()
val time1 = end1 - begin1
sql("set spark.sql.parquet.pushdown.inFilterThreshold=10")
val begin2 = System.currentTimeMillis()
df.where(s"id in(${filter.mkString(",")})").count()
val end2 = System.currentTimeMillis()
val time2 = end2 - begin2
if (time1 <= time2) println(s"Max threshold: $lastSize")
}
}
}
}There was a problem hiding this comment.
Thanks for doing this benchmark, this shall be useful, while I still have some questions:
- For small table (with columns <= 1000000), is the performance of InFilters still better than InSet?
- Can you also forge different filters? Currently your filters are distributed evenly, which don't always happen on real workload. We shall at least benchmark with different filter ratio (#rows filtered / #total rows)
There was a problem hiding this comment.
It mainly depends on how many row groups can skip. for small table (assuming only one row group). There is no obvious difference.
There was a problem hiding this comment.
I have prepared a test case that you can verify it:
test("Benchmark") {
def benchmark(func: () => Unit): Long = {
val start = System.currentTimeMillis()
func()
val end = System.currentTimeMillis()
end - start
}
// scalastyle:off
withSQLConf(SQLConf.PARQUET_FILTER_PUSHDOWN_ENABLED.key -> "true") {
withTempPath { path =>
Seq(1000000, 10000000).foreach { count =>
Seq(1048576, 10485760, 104857600).foreach { blockSize =>
spark.range(count).toDF().selectExpr("id", "cast(id as string) as d1",
"cast(id as double) as d2", "cast(id as float) as d3", "cast(id as int) as d4",
"cast(id as decimal(38)) as d5")
.coalesce(1).write.mode("overwrite")
.option("parquet.block.size", blockSize).parquet(path.getAbsolutePath)
val df = spark.read.parquet(path.getAbsolutePath)
println(s"path: ${path.getAbsolutePath}")
Seq(1000, 100, 10, 1).foreach { ratio =>
println(s"##########[ count: $count, blockSize: $blockSize, ratio: $ratio ]#########")
var i = 1
while (i < 300) {
val filter = Range(0, i).map(r => scala.util.Random.nextInt(count / ratio))
i += 4
sql("set spark.sql.parquet.pushdown.inFilterThreshold=1")
val vanillaTime = benchmark(() => df.where(s"id in(${filter.mkString(",")})").count())
sql("set spark.sql.parquet.pushdown.inFilterThreshold=1000")
val pushDownTime = benchmark(() => df.where(s"id in(${filter.mkString(",")})").count())
if (pushDownTime > vanillaTime) {
println(s"vanilla is better, threshold: ${filter.size}, $pushDownTime, $vanillaTime")
} else {
println(s"push down is better, threshold: ${filter.size}, $pushDownTime, $vanillaTime")
}
}
}
}
}
}
}
}|
Test build #92156 has finished for PR 21603 at commit
|
|
Jenkins, retest this please. |
| case sources.In(name, values) if canMakeFilterOn(name) && values.length < 20 => | ||
| values.flatMap { v => | ||
| makeEq.lift(nameToType(name)).map(_(name, v)) | ||
| }.reduceLeftOption(FilterApi.or) |
There was a problem hiding this comment.
what about null handling? Do we get the same result as before? Anyway, can we add a test for it?
|
Test build #92161 has finished for PR 21603 at commit
|
|
cc @gatorsmile, @viirya, @jiangxb1987 and @a10y too |
|
Test build #92198 has finished for PR 21603 at commit
|
|
retest this please. |
|
|
||
| import testImplicits._ | ||
| withTempPath { path => | ||
| (0 to 1024).toDF("a").coalesce(1) |
| "This configuration only has an effect when 'spark.sql.parquet.filterPushdown' is enabled.") | ||
| .internal() | ||
| .intConf | ||
| .checkValue(threshold => threshold > 0 && threshold <= 300, |
There was a problem hiding this comment.
why are we enforcing that the threshold <= 300 despite this might be a reasonable value, I think that the user should be able to set the value he/she wants. If the value the user sets is a bad one, its his/her problem to set a proper value. We can probably mention that from the experiments 300 seems to be a limit threshold in the description eventually, in order to give an hint to the user.
There was a problem hiding this comment.
I also think to set a maximum value 300 is a bit weird.
| * Some utility function to convert Spark data source filters to Parquet filters. | ||
| */ | ||
| private[parquet] class ParquetFilters(pushDownDate: Boolean) { | ||
| private[parquet] class ParquetFilters(pushDownDate: Boolean, inFilterThreshold: Int) { |
There was a problem hiding this comment.
nit: not a big deal, but since now SQLConf are available also on executor side, can we get its value inside the class rather than outside? If we add more configurations this constructor might explode...
| val PARQUET_FILTER_PUSHDOWN_INFILTERTHRESHOLD = | ||
| buildConf("spark.sql.parquet.pushdown.inFilterThreshold") | ||
| .doc("The maximum number of values to filter push-down optimization for IN predicate. " + | ||
| "Large threshold will not provide much better performance. " + |
There was a problem hiding this comment.
Large threshold won't necessarily provide much better performance.
|
Test build #92203 has finished for PR 21603 at commit
|
|
Test build #92210 has finished for PR 21603 at commit
|
| buildConf("spark.sql.parquet.pushdown.inFilterThreshold") | ||
| .doc("The maximum number of values to filter push-down optimization for IN predicate. " + | ||
| "Large threshold won't necessarily provide much better performance. " + | ||
| "The experiment argued that 300 is the limit threshold. " + |
There was a problem hiding this comment.
This also depends on the data types, right?
There was a problem hiding this comment.
You are right.
| Type | limit threshold |
|---|---|
| string | 370 |
| int | 210 |
| long | 285 |
| double | 270 |
| float | 220 |
| decimal | Will not provide better performance |
There was a problem hiding this comment.
An interesting finding. Thanks for the update. Maybe you do not need to mention this limit threshold in the doc?
How about post your finding in the PR description?
There was a problem hiding this comment.
See the comment #21603 (comment)
|
Test build #92280 has finished for PR 21603 at commit
|
|
Jenkins, retest this please. |
|
Test build #92340 has finished for PR 21603 at commit
|
|
Benchmark result: |
# Conflicts: # sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala # sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFileFormat.scala # sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFilters.scala # sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFilterSuite.scala
|
Test build #92605 has finished for PR 21603 at commit
|
|
@wangyum, mind resolving the conflicts please? I think it's quite close. |
# Conflicts: # sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFileFormat.scala
| Native ORC Vectorized 6840 / 8073 2.3 434.9 1.1X | ||
| Native ORC Vectorized (Pushdown) 1041 / 1075 15.1 66.2 7.4X | ||
| Parquet Vectorized 7967 / 8175 2.0 506.5 1.0X | ||
| Parquet Vectorized (Pushdown) 8155 / 8434 1.9 518.5 1.0X |
There was a problem hiding this comment.
I think this benchmark numbers are more meaningful if we show IN predicate is pushdown or not (or threshold).
|
Test build #92666 has finished for PR 21603 at commit
|
|
retest this please. |
|
Test build #92676 has finished for PR 21603 at commit
|
|
retest this please. |
|
Test build #92684 has finished for PR 21603 at commit
|
|
retest this please. |
|
Test build #92702 has finished for PR 21603 at commit
|
| "This configuration only has an effect when 'spark.sql.parquet.filterPushdown' is enabled.") | ||
| .internal() | ||
| .intConf | ||
| .checkValue(threshold => threshold > 0, "The threshold must be greater than 0.") |
There was a problem hiding this comment.
Shell we allow, for example, -1 here to disable this?
There was a problem hiding this comment.
case sources.In(name, values) if canMakeFilterOn(name) && shouldConvertInPredicate(name)
&& values.distinct.length <= pushDownInFilterThreshold =>How about 0. values.distinct.length will not be less than 0.
| parquetFilters.createFilter(parquetSchema, sources.In("a", Array(10, 10))) | ||
| } | ||
|
|
||
| assertResult(Some(or( |
There was a problem hiding this comment.
I think you can remove this test because it looks basically a duplicate of the below.
| .coalesce(1).write.option("parquet.block.size", 512) | ||
| .parquet(path.getAbsolutePath) | ||
| val df = spark.read.parquet(path.getAbsolutePath) | ||
| Seq(true, false).foreach { pushEnabled => |
There was a problem hiding this comment.
@wangyum, does this really test the Parquet itself push down fine? I think you should stripSparkFilter and check if they are actually filtered out when spark.sql.parquet.filterPushdown is enabled.
There was a problem hiding this comment.
Updated to:
val actual = stripSparkFilter(df.where(filter)).collect().length
if (pushEnabled && count <= conf.parquetFilterPushDownInFilterThreshold) {
assert(actual > 1 && actual < data.length)
} else {
assert(actual === data.length)
}|
LGTM otherwise. |
| def canMakeFilterOn(name: String): Boolean = nameToType.contains(name) && !name.contains(".") | ||
|
|
||
| // All DataTypes that support `makeEq` can provide better performance. | ||
| def shouldConvertInPredicate(name: String): Boolean = nameToType(name) match { |
There was a problem hiding this comment.
@HyukjinKwon How about remove this?
Timestamp type and Decimal type will be support soon.
There was a problem hiding this comment.
It depends on which PR will be merged first. The corresponding PRs should update this.
There was a problem hiding this comment.
Also need to update the benchmark suite.
| // converted (`ParquetFilters.createFilter` returns an `Option`). That's why a `flatMap` | ||
| // is used here. | ||
| .flatMap(new ParquetFilters(pushDownDate, pushDownStringStartWith) | ||
| .flatMap(new ParquetFilters(pushDownDate, pushDownStringStartWith, |
There was a problem hiding this comment.
let us create val parquetFilters = new ParquetFilters(pushDownDate, pushDownStringStartWith, pushDownInFilterThreshold )
|
Test build #92995 has finished for PR 21603 at commit
|
| assert(df.where(filter).count() === count) | ||
| val actual = stripSparkFilter(df.where(filter)).collect().length | ||
| if (pushEnabled && count <= conf.parquetFilterPushDownInFilterThreshold) { | ||
| assert(actual > 1 && actual < data.length) |
There was a problem hiding this comment.
ah okay this tests block level filtering. lgtm
|
Merged to master |
|
I see this benchmarking is done for parquet filters. Did we have similar kind of benchmarking for ORC format too ? |
|
Ask questions to mailing list. ORC is completely orthogonal with this Parquet PR. |
What changes were proposed in this pull request?
The original pr is: #18424
Add a new optimizer rule to convert an IN predicate to an equivalent Parquet filter and add
spark.sql.parquet.pushdown.inFilterThresholdto control limit thresholds. Different data types have different limit thresholds, this is a copy of data for reference:How was this patch tested?
unit tests and manual tests