[SPARK-23375][SQL][FOLLOWUP][TEST] Test Sort metrics while Sort is missing #23258
Conversation
|
cc: @mgaido91 |
There was a problem hiding this comment.
assert(df.queryExecution.executedPlan.find(_.isInstanceOf[SortExec]).isDefined)?
There was a problem hiding this comment.
OK, I think this is more readable. fixed.
There was a problem hiding this comment.
We need to use range here? How about just writing Seq(1, 3, 2, ...).toDF("id")?
There was a problem hiding this comment.
Either is fine to me as we now add assert to make sure Sort node exist.
There was a problem hiding this comment.
Using Seq instead of Range, we makes things simpler and more readable. I'll change to use Seq.
|
Test build #99856 has finished for PR 23258 at commit
|
|
Test build #99852 has finished for PR 23258 at commit
|
|
retest this please. |
|
Test build #99864 has finished for PR 23258 at commit
|
There was a problem hiding this comment.
Thanks for pinging me @maropu. What is the point about checking that LocalTableScan contains no metrics?
I checked the original PR which introduced this UT by @sameeragarwal who can maybe help us stating the goal of the test here (unless someone else can answer me, because I have not understood it). It doesn't seem even related to the Sort operator to me. Maybe I am missing something.
There was a problem hiding this comment.
@mgaido91 This case tries to check Sort (nodeId=0) metrics, rather than LocalTableScan. The second parameter (2) of testSparkPlanMetrics(df, 2, Map.empty) means expectedNumOfJobs rather than nodeId. The third parameter expectedMetrics will pass nodeId together with corresponding expected metrics. Because metrics of Sort node (including sortTime, peakMemory, spillSize) may change during each execution, unlike metrics like numOutputRows, we have no way to check these values.
There was a problem hiding this comment.
can we check the metrics of SortExec here?
There was a problem hiding this comment.
@cloud-fan This case tries to check metrics of SortExec, however these metrics (sortTime, peakMemory, spillSize) change each time the query is executed, they are not fixed. So far what I did is to check whether SortExec exists. Do you mean we should further check whether these metrics names exist? Though we can't know their values beforehand.
There was a problem hiding this comment.
can we just check something like sortTime > 0?
There was a problem hiding this comment.
+1 for @cloud-fan suggestion. I mean, if we cannot check their exact value, we should at least check that they exist/have reasonable values. Otherwise this UT is useless.
There was a problem hiding this comment.
This makes sense! Let me try.
There was a problem hiding this comment.
@seancxmao what do you think about updating this?
There was a problem hiding this comment.
@srowen Thanks for reminding me. I'll update this later this week. So busy these days...
0f514fd to
4ee2c8d
Compare
|
Test build #100431 has finished for PR 23258 at commit
|
|
Test build #100430 has finished for PR 23258 at commit
|
|
retest this please. |
|
Test build #100432 has finished for PR 23258 at commit
|
|
retest this please. |
|
Test build #100436 has finished for PR 23258 at commit
|
| } | ||
|
|
||
| private def stringToDuration(str: String): (Float, String) = { | ||
| val matcher = Pattern.compile("([0-9]+(\\.[0-9]+)?) (ms|s|m|h)").matcher(str) |
There was a problem hiding this comment.
we can compile the pattern only once here and in the other cases
There was a problem hiding this comment.
@seancxmao can you address this comment? Thanks!
There was a problem hiding this comment.
Fixed with a new commit. I also extracted Pattern.compile("([0-9]+(\\.[0-9]+)?) (ms|s|m|h)").
| assert(operatorName == "Sort") | ||
| // Check metrics values | ||
| val sortTimeStr = sortMetrics._2.get("sort time total (min, med, max)").get.toString | ||
| timingMetricStats(sortTimeStr).foreach { case (sortTime, _) => assert(sortTime >= 0) } |
There was a problem hiding this comment.
I think we can just check that the sum is (strictly) greater than 0. Checking that everything is >= 0. This can also simplify the whole code and avoid to add too many methods.
There was a problem hiding this comment.
According to SortExec, sort time may be 0 because it is converted from nano-seconds to milli-seconds.
I tried to run with "sortTime > 0", sometimes it failed.

There was a problem hiding this comment.
I see, but here you are checking also the min IIUC. Can the sum be 0 too?
There was a problem hiding this comment.
Yes, I'm checking all 4 stats, including sum, min, med and max. And sum could also be 0. I ran the same query with spark-shell locally. below's the screenshot.
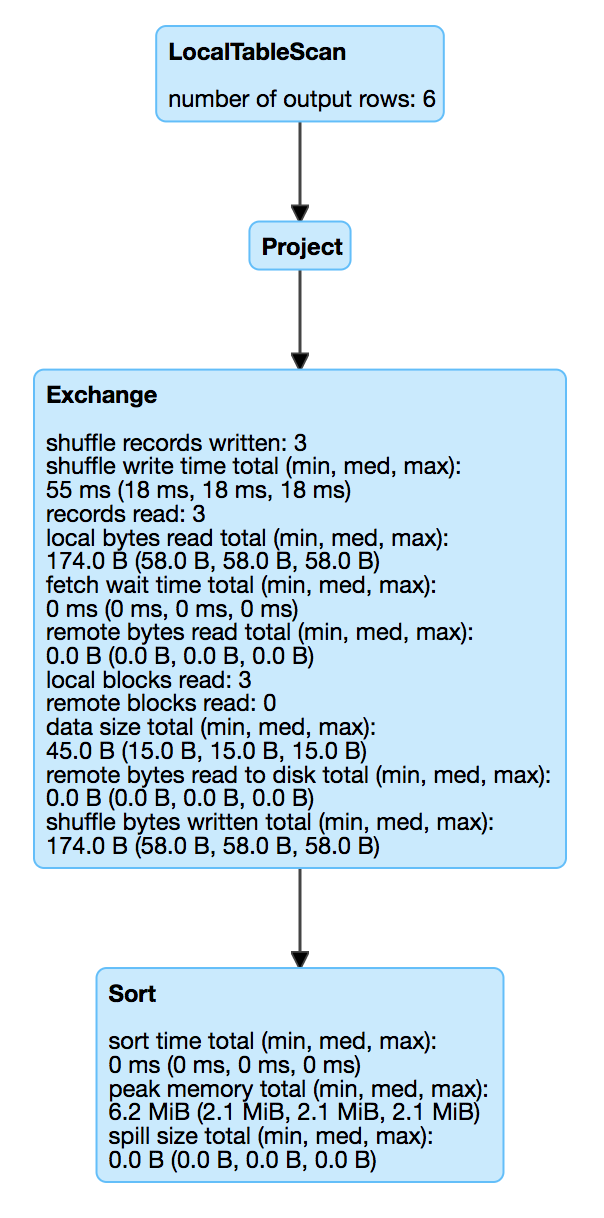
There was a problem hiding this comment.
nit: assert(timingMetricStats(sortTimeStr).forall { case (sortTime, _) => sortTime >= 0 })?
There was a problem hiding this comment.
Yes, it's better.
There was a problem hiding this comment.
Fixed with a new commit.
There was a problem hiding this comment.
I see, can we add a comment with the reason why it can be 0?
There was a problem hiding this comment.
@mgaido91 I have added a comment to explain the reason with a new commit.
|
retest this please. |
|
Test build #100445 has finished for PR 23258 at commit
|
| // so Project here is not collapsed into LocalTableScan. | ||
| val df = Seq(1, 3, 2).toDF("id").sort('id) | ||
| val metrics = getSparkPlanMetrics(df, 2, Set(0)) | ||
| val sortMetrics = metrics.get.get(0).get |
There was a problem hiding this comment.
Probably, it might be better to check assert(metrics.isDefined) for safeguard.
There was a problem hiding this comment.
Yes, I'll fix it.
There was a problem hiding this comment.
Fixed with a new commit.
| */ | ||
| protected def timingMetricStats(metricStr: String): Seq[(Float, String)] = { | ||
| metricStats(metricStr).map(stringToDuration) | ||
| } |
There was a problem hiding this comment.
We need to put these helper functions here? That's because these functions are only used for test("Sort metrics") now ...
There was a problem hiding this comment.
Yes, currently these functions are only used for test("Sort metrics"). What SQLMetricsSuite has been checking are almost all integer number metrics (e.g. "number of output rows", "records read", ...). However we should also check non-integer metrics, such as timing metric and size metric. These metrics are in the same format of "total (min, med, max)". These help functions could be used to check all these metrics. Please see the screenshot I posted above to see more timing or size metric examples (shuffle write, shuffle read, ...).
There was a problem hiding this comment.
I think we can actually remove all them for now. I think we can just check that the metrics are defined, since we are not really checking their values (the only one for which we are ensuring something is the peak memory...). I'd propose defining a testSparkPlanMetricsPattern which is basically the same as testSparkPlanMetrics but instead of providing a value for each metric, we pass a pattern. What do you think?
There was a problem hiding this comment.
It's a great idea to add a method similar to testSparkPlanMetrics. Let me try. I'd like to slightly change the method name to testSparkPlanMetricsWithPredicates, since we are actually passing in predicates.
There was a problem hiding this comment.
As for checking metrics, checking ">= 0" is better than just checking whether it is defined. because size or timing SQLMetric could be initialized by non-0 values, e.g. -1.
There was a problem hiding this comment.
In a new commit, I have added SQLMetricsTestUtils#testSparkPlanMetricsWithPredicates. In such a way, we simply need to provide a test spec in test("Sort metrics") to make the test case declarative rather than procedural.
To simplify timing and size metric testing, I added 2 common predicates, timingMetricAllStatsShould and sizeMetricAllStatsShould. These could be used for other metrics as long as they are timing or size metrics.
And I also modified the original testSparkPlanMetrics to make it a special case of testSparkPlanMetricsWithPredicates, where each expected metric value is converted to an equality predicate. This eliminated duplicate code as testSparkPlanMetrics and testSparkPlanMetricsWithPredicates are almost the same.
|
Test build #100466 has finished for PR 23258 at commit
|
|
retest this please. |
|
Test build #100468 has finished for PR 23258 at commit
|
There was a problem hiding this comment.
@seancxmao I am quite against this idea of checking a predicate for sum, min, max, med...they can be different, and I'd argue that most likely we may be interested only in a specific one. I think the current approach with the new method is fine, but I think that we can use the regex in order to test that values are valid, rather than parsing the strings and then apply predicates. In this way we can also remove all the new added methods (we just need testSparkPlanMetricsWithPredicates).
| * Call `df.collect()` and verify if the collected metrics satisfy the specified predicates. | ||
| * @param df `DataFrame` to run | ||
| * @param expectedNumOfJobs number of jobs that will run | ||
| * @param expectedMetricsPredicates the expected metrics predicates. The format is |
There was a problem hiding this comment.
nit: go to 100 chars and the next line has a bad indentation
There was a problem hiding this comment.
Because usually metric values are numbers, so for metrics values, predicates could be more natural than regular expressions which are more suitable for text matching. For simple metric values, helper functions are not needed. However, timing and size metric values are a little complex:
- timing metric value example: "\n96.2 MB (32.1 MB, 32.1 MB, 32.1 MB)"
- size metric value example: "\n2.0 ms (1.0 ms, 1.0 ms, 1.0 ms)"
With helper functions, we extract stats (by timingMetricStats or sizeMetricStats method), then we can apply predicates to check any stats (all stats or any single one). timingMetricAllStatsShould and sizeMetricAllStatsShould are not required, they are something like syntax sugar to eliminate boilerplate code since timing and size metrics are frequently used. If we want to check any single value (e.g sum >=0), we can provide a predicate like below:
timingMetricStats(_)(0)._1 >= 0
BTW, may be timing and size metric values should be stored in a more structured way rather than pure text format (even with "\n" in values).
There was a problem hiding this comment.
Yes, indentation is not right. I have fixed it in the new commit.
There was a problem hiding this comment.
my point is: as of now, pattern matching is enough for what we need to check and we do not have a use case when we actually need to parse the exact values. Doing that, we can simplify this PR and reduce considerably the size of this change. So I think we should go this way. If in the future we will need something like you proposed here because we want to check the actual values, then we can introduce all the methods you are suggesting here. But as of know this can be skipped IMO.
There was a problem hiding this comment.
This does look like a load of additional code that I think duplicates some existing code in Utils? is it really necessary to make some basic assertions about metric values?
There was a problem hiding this comment.
@mgaido91 I agree. Thanks for your detailed and clear explanation. Checking metric values do make things unnecessarily complex.
@srowen As @mgaido91 said, currently it is not necessary to check metric values, pattern matching is enough, and we could eliminate these methods. As for code duplication, methods here are not duplicate with code in Utils. Utils provides a bunch of methods to do conversion between string and bytes, bytes there are of type Long. However bytes in metric values are of type Float, e.g. 96.2 MB.
There was a problem hiding this comment.
Hi, I have switched to pattern matching and also removed unnecessary helper methods in the new commit.
|
Test build #100495 has finished for PR 23258 at commit
|
|
Test build #100505 has finished for PR 23258 at commit
|
|
Test build #100525 has finished for PR 23258 at commit
|
|
retest this please. |
|
Test build #100528 has finished for PR 23258 at commit
|
| // Because of SPARK-25267, ConvertToLocalRelation is disabled in the test cases of sql/core, | ||
| // so Project here is not collapsed into LocalTableScan. | ||
| val df = Seq(1, 3, 2).toDF("id").sort('id) | ||
| testSparkPlanMetrics(df, 2, Map( |
There was a problem hiding this comment.
I think we can get back to the previous idea of having another method for testing a predicate. And use the patters there to validate it. I am not a fan of introducing an enum for this.
There was a problem hiding this comment.
Because expectedMetrics could provide several different types of information, including values, compiled pattern objects, pattern strings, or even predicate functions in future, we need to provide a method for each type. I'm OK to add new methods for different types rather than to use a single method with different flags, both has pros and cons. Just want to know more your idea.
There was a problem hiding this comment.
Let me clarify. I'd introduce a testSparkPlanMetricsWithPredicates as you did before (you can take it from your previous commit). And here in the predicate we can use the patterns you introduced for checking them, so something like:
val timingMetricPattern =
Pattern.compile(s"\\n$duration \\($duration, $duration, $duration\\)")
val sizeMetricPattern = Pattern.compile(s"\\n$bytes \\($bytes, $bytes, $bytes\\)")
def checkPattern(pattern: Pattern): (Any => Boolean) = {
(in: Any) => pattern.matcher(in.toString).matches()
}
testSparkPlanMetricsWithPredicates(df, 2, Map(
0L -> (("Sort", Map(
"sort time total (min, med, max)" -> checkPattern(sizeMetricPattern),
"peak memory total (min, med, max)" -> checkPattern(timingMetricPattern),
"spill size total (min, med, max)" -> checkPattern(sizeMetricPattern))))))
There was a problem hiding this comment.
Got it. Thanks for your explanation and example.
There was a problem hiding this comment.
I have changed to use testSparkPlanMetricsWithPredicates and checkPattern together.
| protected val timingMetricPattern = | ||
| Pattern.compile(s"\\n$duration \\($duration, $duration, $duration\\)") | ||
|
|
||
| /** Generate a function to check the specified pattern. |
|
|
||
| /** Generate a function to check the specified pattern. | ||
| * | ||
| * @param pattern a pattern |
There was a problem hiding this comment.
not very useful, we can remove it
There was a problem hiding this comment.
removed checkPattern method.
| for (metricName <- expectedMetricsMap.keySet) { | ||
| assert(expectedMetricsMap(metricName).toString === actualMetricsMap(metricName)) | ||
| } | ||
| } |
There was a problem hiding this comment.
we can update this in order to avoid code duplication and reuse testSparkPlanMetrics.
There was a problem hiding this comment.
I have updated testSparkPlanMetrics to invoke testSparkPlanMetricsWithPredicates to avoid code duplication.
| * @param df `DataFrame` to run | ||
| * @param expectedNumOfJobs number of jobs that will run | ||
| * @param expectedMetricsPredicates the expected metrics predicates. The format is | ||
| * `nodeId -> (operatorName, metric name -> metric value predicate)`. |
There was a problem hiding this comment.
Fixed indentation.
|
|
||
| protected def statusStore: SQLAppStatusStore = spark.sharedState.statusStore | ||
|
|
||
| protected val bytes = "([0-9]+(\\.[0-9]+)?) (EiB|PiB|TiB|GiB|MiB|KiB|B)" |
There was a problem hiding this comment.
nit: private? and maybe close to where it is used?
There was a problem hiding this comment.
I have inlined this in an initializer as @srowen suggested.
|
|
||
| protected val bytes = "([0-9]+(\\.[0-9]+)?) (EiB|PiB|TiB|GiB|MiB|KiB|B)" | ||
|
|
||
| protected val duration = "([0-9]+(\\.[0-9]+)?) (ms|s|m|h)" |
There was a problem hiding this comment.
I have inlined this in an initializer as @srowen suggested.
|
|
||
| protected val duration = "([0-9]+(\\.[0-9]+)?) (ms|s|m|h)" | ||
|
|
||
| // "\n96.2 MiB (32.1 MiB, 32.1 MiB, 32.1 MiB)" |
There was a problem hiding this comment.
Shall we say something more here? A line which explains what this is and then eg. and your example is fine IMHO.
There was a problem hiding this comment.
I have added more comments.
| protected val duration = "([0-9]+(\\.[0-9]+)?) (ms|s|m|h)" | ||
|
|
||
| // "\n96.2 MiB (32.1 MiB, 32.1 MiB, 32.1 MiB)" | ||
| protected val sizeMetricPattern = Pattern.compile(s"\\n$bytes \\($bytes, $bytes, $bytes\\)") |
There was a problem hiding this comment.
Add .r to the end of these strings to make them a scala.util.matching.Regex automatically. That's more idiomatic for Scala. No need to import and use Java's Pattern.
|
|
||
| protected val bytes = "([0-9]+(\\.[0-9]+)?) (EiB|PiB|TiB|GiB|MiB|KiB|B)" | ||
|
|
||
| protected val duration = "([0-9]+(\\.[0-9]+)?) (ms|s|m|h)" |
There was a problem hiding this comment.
private? or you can inline this in an initializer below:
protected val sizeMetricPattern = {
val bytes = ...
"s\\n$bytes...".r
}
| getSparkPlanMetrics(df, expectedNumOfJobs, expectedMetricsPredicates.keySet) | ||
| optActualMetrics.foreach { actualMetrics => | ||
| assert(expectedMetricsPredicates.keySet === actualMetrics.keySet) | ||
| for (nodeId <- expectedMetricsPredicates.keySet) { |
There was a problem hiding this comment.
It might be a little cleaner to iterate over (key, value) pairs here and below rather than iterate over keys then get values:
for ((nodeId, (expectedNodeName, expectedMetricsPredicatesMap) <- expectedMetricsPredicates) {
| * @param pattern a pattern | ||
| * @return a function to check the specified pattern | ||
| */ | ||
| protected def checkPattern(pattern: Pattern): (Any => Boolean) = { |
There was a problem hiding this comment.
Is this method really needed? the only place it's used is the very specific method for testing metrics, and that always provides a regex. Just provide a map to regexes that you check against, rather than whole predicates?
Or, consider not compiling regexes above and keeping them as string patterns. Then, the predicate you pass is just something like sizeMetricPattern.matches(_). It means compiling the regex on every check, but for this test context, that's no big deal.
That would help limit the complexity of all this
There was a problem hiding this comment.
I'd like to take the 2nd option.
|
Test build #100557 has finished for PR 23258 at commit
|
| assert(expectedNodeName === actualNodeName) | ||
| for (metricName <- expectedMetricsMap.keySet) { | ||
| assert(expectedMetricsMap(metricName).toString === actualMetricsMap(metricName)) | ||
| for (metricName <- expectedMetricsPredicatesMap.keySet) { |
There was a problem hiding this comment.
You can use a similar iteration over the map here that avoid the keySet and get
There was a problem hiding this comment.
Changed in the new commit.
| import org.apache.spark.sql.catalyst.expressions.aggregate.{Final, Partial} | ||
| import org.apache.spark.sql.catalyst.plans.logical.LocalRelation | ||
| import org.apache.spark.sql.execution.{FilterExec, RangeExec, SparkPlan, WholeStageCodegenExec} | ||
| import org.apache.spark.sql.execution.{FilterExec, RangeExec, SortExec, SparkPlan, WholeStageCodegenExec} |
There was a problem hiding this comment.
Removed in the new commit.
|
Test build #100566 has finished for PR 23258 at commit
|
|
LGTM, thanks for your work on this @seancxmao! |
|
Many thanks to your advices and time, really really helpful. This code could be used for #23224 (in progress), |
|
Test build #100574 has finished for PR 23258 at commit
|
|
Merged to master |
…ssing ## What changes were proposed in this pull request? apache#20560/[SPARK-23375](https://issues.apache.org/jira/browse/SPARK-23375) introduced an optimizer rule to eliminate redundant Sort. For a test case named "Sort metrics" in `SQLMetricsSuite`, because range is already sorted, sort is removed by the `RemoveRedundantSorts`, which makes this test case meaningless. This PR modifies the query for testing Sort metrics and checks Sort exists in the plan. ## How was this patch tested? Modify the existing test case. Closes apache#23258 from seancxmao/sort-metrics. Authored-by: seancxmao <[email protected]> Signed-off-by: Sean Owen <[email protected]>
What changes were proposed in this pull request?
#20560/SPARK-23375 introduced an optimizer rule to eliminate redundant Sort. For a test case named "Sort metrics" in
SQLMetricsSuite, because range is already sorted, sort is removed by theRemoveRedundantSorts, which makes this test case meaningless.This PR modifies the query for testing Sort metrics and checks Sort exists in the plan.
How was this patch tested?
Modify the existing test case.