[SPARK-38578][SQL] AdaptiveSparkPlanExec should ensure user-specified ordering #35924
Conversation
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/AQEUtils.scala
Outdated
Show resolved
Hide resolved
65121f8 to
821e694
Compare
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/AQEUtils.scala
Outdated
Show resolved
Hide resolved
There was a problem hiding this comment.
do we need to override outputPartitioning as well?
There was a problem hiding this comment.
I think we can, but there is no requirements about outputPartitioning
There was a problem hiding this comment.
Seems we can remove this now?
There was a problem hiding this comment.
OptimizeSkewedJoin still use this. I considered unify them, but seems OptimizeSkewedJoin does not affect the required output ordering.
sql/core/src/test/scala/org/apache/spark/sql/execution/adaptive/AdaptiveQueryExecSuite.scala
Outdated
Show resolved
Hide resolved
There was a problem hiding this comment.
We should refine the test name if we don't really test table insertion.
There was a problem hiding this comment.
yeah, refined it
There was a problem hiding this comment.
| // User-specified repartition is only effective when it's the root node, or under | |
| // User-specified sort is only effective when it's the root node, or under |
|
The failed test is irrelevant |
|
Can we rerun the tests? |
dfa553c to
602c33c
Compare
|
rebased since that flaky test has been fixed |
|
After a second thought, what will happen if we just do a one-line fix |
it does not. FileFormatWriter just checks the |
|
closed, in favor of #34568 |
What changes were proposed in this pull request?
requiredOrderingoutputOrderinginAdaptiveSparkPlanExecWhy are the changes needed?
AdaptiveSparkPlanExecshould ensure the output ordering is therequiredOrdering, so we leverage theEnsureRequirementsto add sort if need.FileFormatWriter will check and add an implicit sort for dynamic partition columns or bucket columns according to the input physical plan. The check became always failure since AQE AdaptiveSparkPlanExec has no outputOrdering.
That casues a redundant sort if user has specified a sort which satisfies the required ordering (dynamic partition and bucket columns).
Does this PR introduce any user-facing change?
no, improve performance
How was this patch tested?
add test
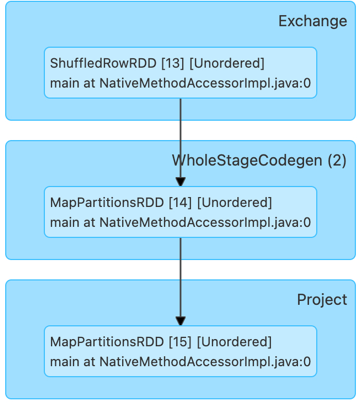
Before:
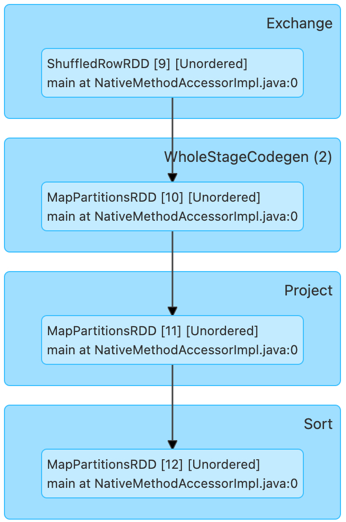
After: