[SPARK-41713][SQL] Make CTAS hold a nested execution for data writing #39220
Conversation
5d05abc to
66ceabc
Compare
| val options = table.storage.properties | ||
| V1WritesUtils.getSortOrder(outputColumns, partitionColumns, table.bucketSpec, options) | ||
| } | ||
| extends LeafRunnableCommand { |
There was a problem hiding this comment.
this is the key change. now ctas is not a v1 write command.
|
cc @cloud-fan |
sql/core/src/main/scala/org/apache/spark/sql/execution/command/createDataSourceTables.scala
Show resolved
Hide resolved
| import org.apache.spark.util.Utils | ||
|
|
||
| trait CreateHiveTableAsSelectBase extends V1WriteCommand with V1WritesHiveUtils { | ||
| trait CreateHiveTableAsSelectBase extends LeafRunnableCommand { |
There was a problem hiding this comment.
do we still need OptimizedCreateHiveTableAsSelectCommand? The nested InsertIntoHadoopFsRelationCommand should be optimized instead.
There was a problem hiding this comment.
good question, but if we do not have a OptimizedCreateHiveTableAsSelectCommand, how can we get InsertIntoHadoopFsRelationCommand ..
The pipeline is: CreateHiveTableAsSelectCommand -> OptimizedCreateHiveTableAsSelectCommand -> InsertIntoHadoopFsRelationCommand
There was a problem hiding this comment.
The new pipeline can be CreateHiveTableAsSelectCommand -> hive insertion command -> InsertIntoHadoopFsRelationCommand
There was a problem hiding this comment.
how to deal with config spark.sql.hive.convertMetastoreCtas ? we do not know if the hive insertion is from ctas.
There was a problem hiding this comment.
or, just deprecated this config
There was a problem hiding this comment.
remove OptimizedCreateHiveTableAsSelectCommand is out of the scope of this pr, how about doing this in a separated pr ?
| assert(planInfo.children.size == 1) | ||
| assert(planInfo.children.head.nodeName == | ||
| "Execute CreateDataSourceTableAsSelectCommand") | ||
| "Execute InsertIntoHadoopFsRelationCommand") |
There was a problem hiding this comment.
shall we check 2 items? One is CreateDataSourceTableAsSelectCommand and the other is InsertIntoHadoopFsRelationCommand
| assert(commands(4)._1 == "command") | ||
| assert(commands(4)._2.isInstanceOf[CreateDataSourceTableAsSelectCommand]) | ||
| assert(commands(4)._2.asInstanceOf[CreateDataSourceTableAsSelectCommand] | ||
| assert(commands.length == 6) |
There was a problem hiding this comment.
shall we add a comment to explain it?
| "InsertIntoHiveTable", | ||
| "Limit", | ||
| "src") | ||
| "== Physical Plan ==") |
There was a problem hiding this comment.
shall we at least check something?
sql/core/src/main/scala/org/apache/spark/sql/execution/command/createDataSourceTables.scala
Show resolved
Hide resolved
|
|
||
| override def fileFormatProvider: Boolean = { | ||
| table.provider.forall { provider => | ||
| classOf[FileFormat].isAssignableFrom(DataSource.providingClass(provider, conf)) |
There was a problem hiding this comment.
shall we revert the change in DataSource.scala as well?
|
@cloud-fan addressed all comments |
| } | ||
| extends LeafRunnableCommand { | ||
| assert(query.resolved) | ||
| override def innerChildren: Seq[LogicalPlan] = query :: Nil |
There was a problem hiding this comment.
can we put the EXPLAIN result of a CTAS in the PR description as an example?
|
thanks, merging to master! |
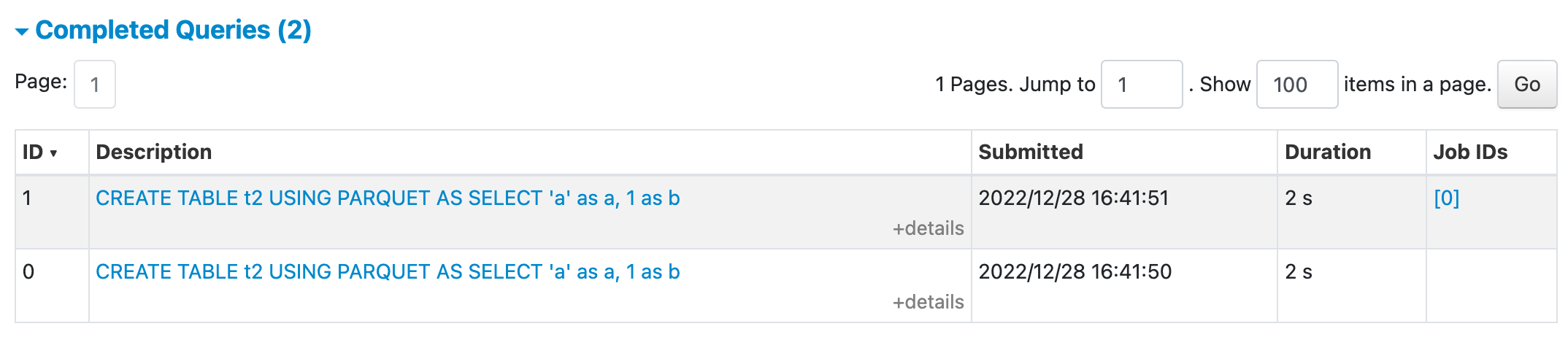
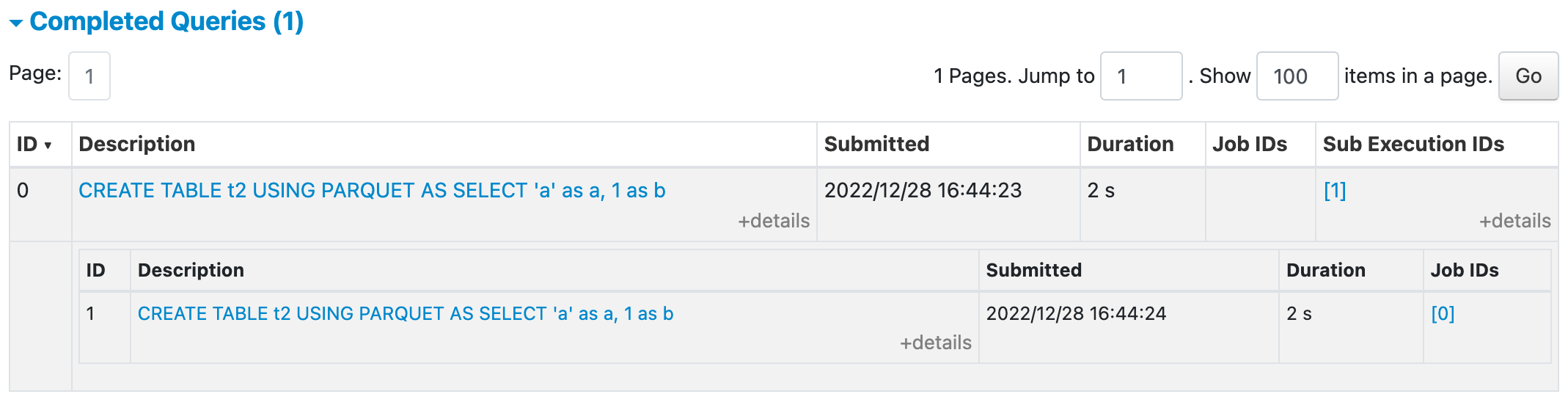
### What changes were proposed in this pull request? This PR proposes to group all sub-executions together in SQL UI if they belong to the same root execution. This feature is controlled by conf `spark.ui.sql.groupSubExecutionEnabled` and the default value is set to `true` We can have some follow-up improvements after this PR: 1. Add links to SQL page and Job page to indicate the root execution ID. 2. Better handling for the root execution missing case (e.g. eviction due to retaining limit). In this PR, the sub-executions will be displayed ungrouped. ### Why are the changes needed? better user experience. In PR #39220, the CTAS query will trigger a sub-execution to perform the data insertion. But the current UI will display the two executions separately which may confuse the users. In addition, this change should also help the structured streaming cases ### Does this PR introduce _any_ user-facing change? Yes, the screenshot of the UI change is shown below SQL Query: ``` CREATE TABLE t USING PARQUET AS SELECT 'a' as a, 1 as b ``` UI before this PR <img width="1074" alt="Screen Shot 2022-12-28 at 4 42 08 PM" src="https://user-images.githubusercontent.com/67896261/209889679-83909bc9-0e15-4ff1-9aeb-3118e4bab524.png"> UI after this PR with sub executions collapsed <img width="1072" alt="Screen Shot 2022-12-28 at 4 44 32 PM" src="https://user-images.githubusercontent.com/67896261/209889688-973a4ec9-a5dc-4a8b-8618-c0800733fffa.png"> UI after this PR with sub execution expanded <img width="1069" alt="Screen Shot 2022-12-28 at 4 44 41 PM" src="https://user-images.githubusercontent.com/67896261/209889718-0e24be12-23d6-4f81-a508-15eac62ec231.png"> ### How was this patch tested? UT Closes #39268 from linhongliu-db/SPARK-41752. Authored-by: Linhong Liu <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
{kind=link}
{kind=link}
{kind=link}
…rom `DataSource` ### What changes were proposed in this pull request? `resolvePartitionColumns` was introduced by SPARK-37287 (#37099) and become unused after SPARK-41713 (#39220), so this pr remove it from `DataSource`. ### Why are the changes needed? Clean up unused code. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass GitHub Actions. ### Was this patch authored or co-authored using generative AI tooling? No Closes #43779 from LuciferYang/SPARK-45902. Lead-authored-by: yangjie01 <[email protected]> Co-authored-by: YangJie <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]>
What changes were proposed in this pull request?
This pr aims to make ctas use a nested execution instead of running data writing cmmand.
So, we can clean up ctas itself to remove the unnecessary v1write information. Now, the v1writes only have two implementation:
InsertIntoHadoopFsRelationCommandandInsertIntoHiveTableWhy are the changes needed?
Make v1writes code clear.
Does this PR introduce any user-facing change?
no
How was this patch tested?
improve existed test