[BUG]: Several bugs in examples/language/gpt/titans #2493
Description
🐛 Describe the bug
Several small bug in the examples provided in directory language/gpt/titans:
- the default option of argument '--use_dummy_dataset' in function main of file train_gpt.py should be set to False, and 'store_false', otherwise even if I set the environment variable DATA, and run the train_gpt.py without the option '--use_dummy_dataset', the training will use dummy data.
- Please add the py file webtext, otherwise the train_gpt.py will complain that 'WebtextDataset cannot be imported from dataset.webtext'.
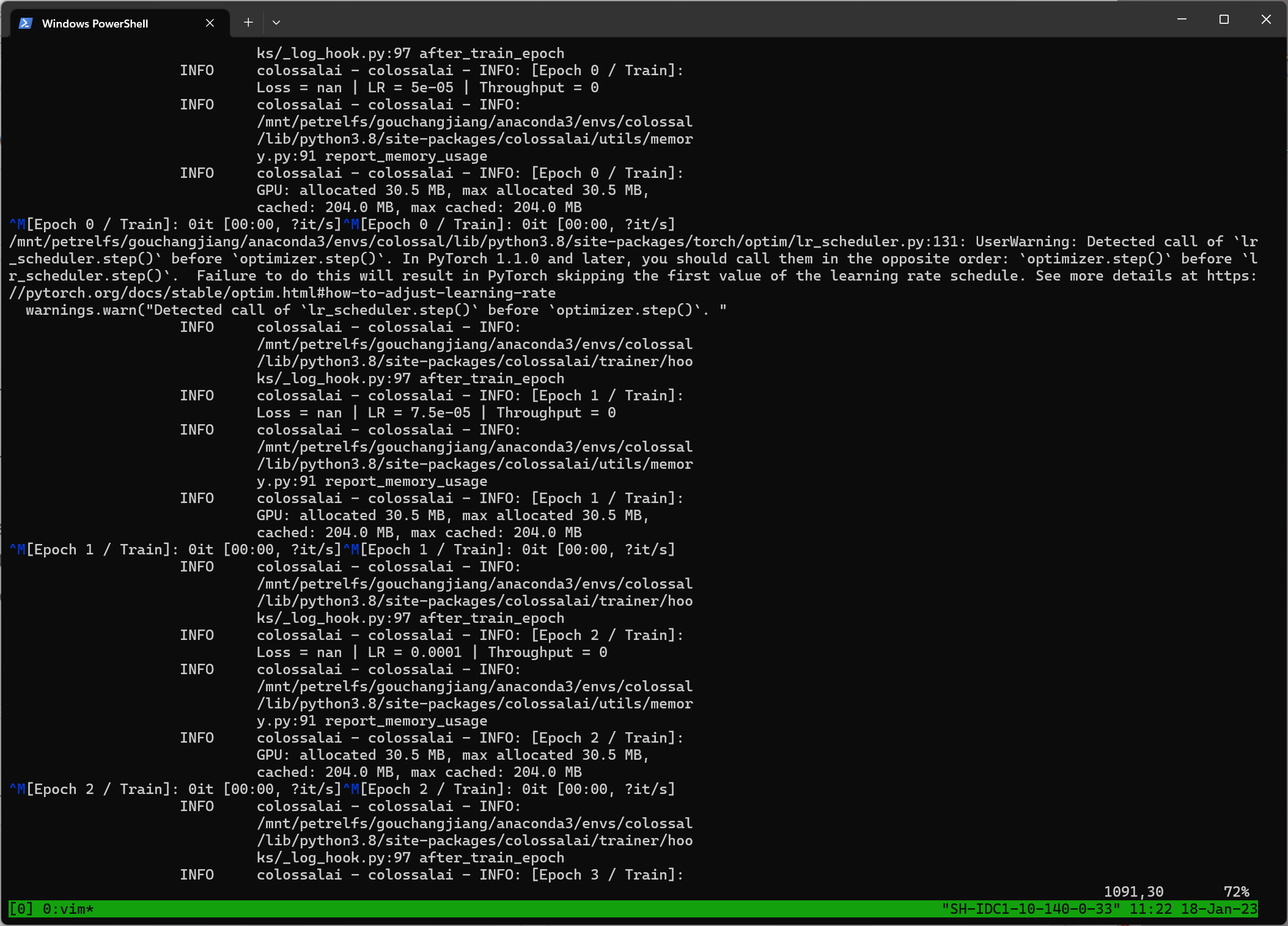
- The throughput is 0, Loss is nan from epoch 1 to epoch 8, then it stalls. The total epoch is 10. I am using the config 'gpt2_small_zero3_pp1d.py'. Nothing modified. 4 Nodes equipped with 8 A100 each are provided. ColossalAI is launched with Slurm. PyTorch is 1.12.1 and CUDA is of version 11.3. Two screeshot of out are provided:

Environment
PyTorch is 1.12.1 and CUDA is of version 11.3. Colossal-AI is built from source without CUDA pre-compiled kernel.