Add tgs speed metrics
#25858
Add tgs speed metrics
#25858
Conversation
src/transformers/trainer.py
Outdated
There was a problem hiding this comment.
Is there a better way we can perhaps do this by checking if max_steps is none and its streaming dataloader for instance? I worry about speed slowdowns if users for instance have a large dataset across the dataloaders.
I'd prefer this as perhaps an opt-in via TrainingArguments, noting how it will iterate over the dataloader to get these.
src/transformers/trainer.py
Outdated
There was a problem hiding this comment.
| tks = batch["input_ids"].size(0) * batch["input_ids"].size(1) | |
| tokens = batch["input_ids"].size(0) * batch["input_ids"].size(1) |
Full words please :)
|
The docs for this PR live here. All of your documentation changes will be reflected on that endpoint. |
src/transformers/trainer.py
Outdated
There was a problem hiding this comment.
We are calculating max_steps on line 1614. Why can't we use that to avoid iterating through the entire dataloader?
There was a problem hiding this comment.
max_steps doesnot contains the num of tokens infomation, so we call num_tokens on line 1617 .
yes, the iteration will slow down the whole training ,especally big datasets. Currently i am trying moving the approximation of tokens per second into each training step so as to avoild duplicated dataloading process. maybe that will solve the common concerns.
There was a problem hiding this comment.
If that's not possible (which I don't think it is without some effort) I'd rather see this as an opt-in. Because the other issue with this is users can use the Trainer to train any dataset, not just text (though that's the most common). So again, I'd rather see this as an opt-in specifying more in TrainingArguments.
There was a problem hiding this comment.
yeah.i got u:-) an opt-in maybe the most direct way for user to choose open tgs or not. will do that.
|
@muellerzr @pacman100 PTAL, thx |
There was a problem hiding this comment.
Thanks! We're getting much, much closer. I've added a naming nit, cc @amyeroberts if you have some ideas on other naming conventions, and how this looks to you :) Let's avoid acronyms/shorthand as much as possible.
There was a problem hiding this comment.
Thanks for the work adding this @CokeDong!
Overall code looks good - as @muellerzr suggests we should rename some of the variables, and slightly rework the logic to make the code clearer.
src/transformers/trainer.py
Outdated
There was a problem hiding this comment.
args.tgs_metrics shouldn't be None - it should be either True or False
| num_tokens=None if args.tgs_metrics is None else num_train_tokens / args.world_size, | |
| num_tokens=None if not args.tgs_metrics else num_train_tokens / args.world_size, |
src/transformers/trainer.py
Outdated
There was a problem hiding this comment.
If we set this to None here, then we don't need the conditional logic on L2016
src/transformers/trainer.py
Outdated
There was a problem hiding this comment.
Let's make this a bit clearer
| * self.num_tokens(train_dataloader, True) | |
| * self.num_tokens(train_dataloader, max_steps=True) |
src/transformers/trainer.py
Outdated
There was a problem hiding this comment.
| * self.num_tokens(train_dataloader, True) | |
| * self.num_tokens(train_dataloader, max_steps=True) |
|
https://app.circleci.com/jobs/github/huggingface/transformers/913233 |
|
@CokeDong please rebase with the main branch of transformers, this should ensure it passes :) |
renaming Co-authored-by: Zach Mueller <[email protected]>
renaming Co-authored-by: Zach Mueller <[email protected]>
match nameing patterns Co-authored-by: amyeroberts <[email protected]>
Co-authored-by: amyeroberts <[email protected]>
nice Co-authored-by: amyeroberts <[email protected]>
b2e1d81 to
3c97d2d
Compare
|
BTW @CokeDong, you don't have to do force-pushes if you're worried about the commit-bloat post-merge, in |
Got that |
* Add tgs metrics * bugfix and black formatting * workaround for tokens counting * formating and bugfix * Fix * Add opt-in for tgs metrics * make style and fix error * Fix doc * fix docbuild * hf-doc-build * fix * test * Update src/transformers/training_args.py renaming Co-authored-by: Zach Mueller <[email protected]> * Update src/transformers/training_args.py renaming Co-authored-by: Zach Mueller <[email protected]> * Fix some symbol * test * Update src/transformers/trainer_utils.py match nameing patterns Co-authored-by: amyeroberts <[email protected]> * Update src/transformers/training_args.py Co-authored-by: amyeroberts <[email protected]> * Update src/transformers/trainer.py nice Co-authored-by: amyeroberts <[email protected]> * Fix reviews * Fix * Fix black --------- Co-authored-by: Zach Mueller <[email protected]> Co-authored-by: amyeroberts <[email protected]>
|
thanks for this great feature!
|


hi, |
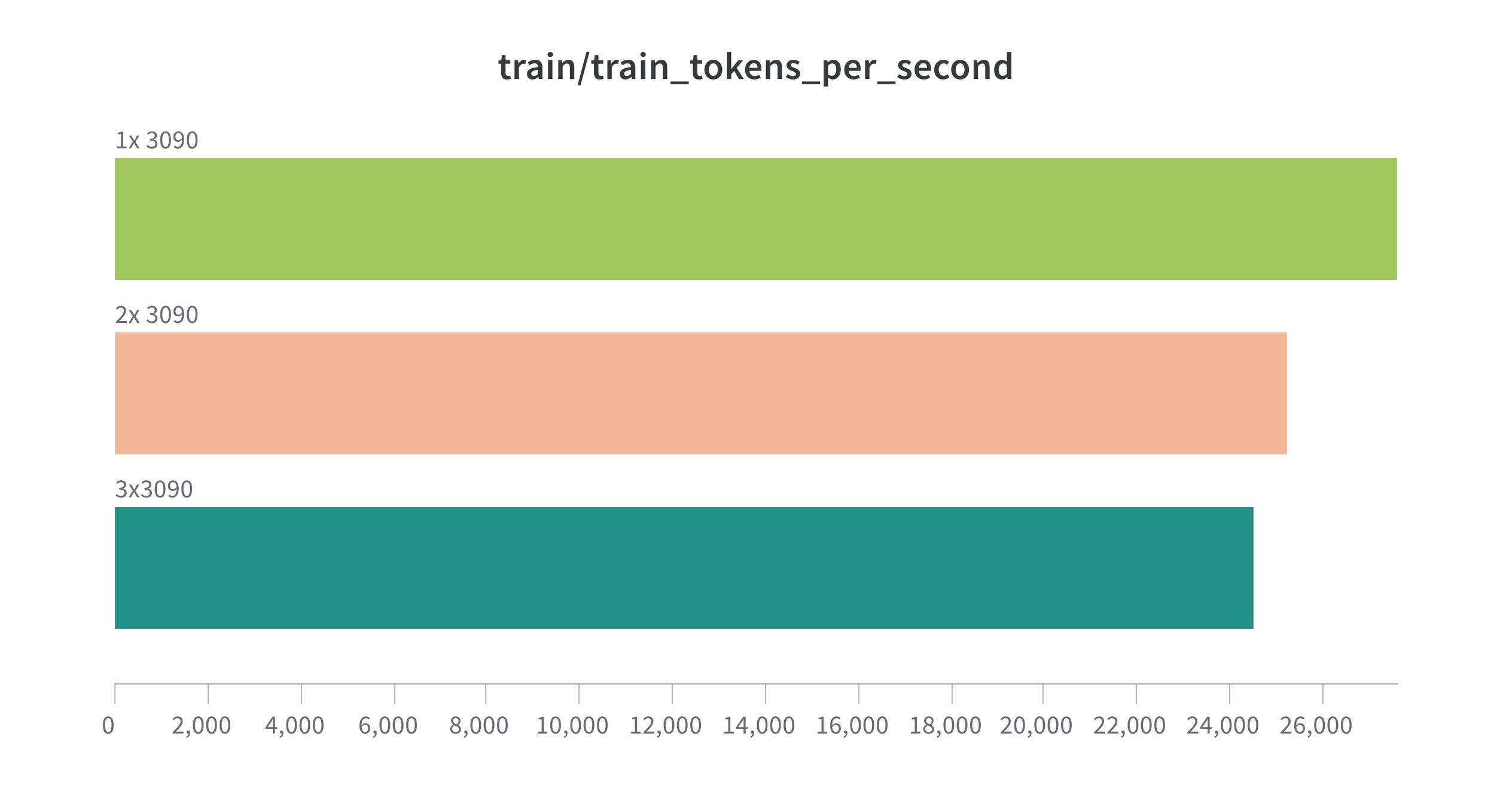
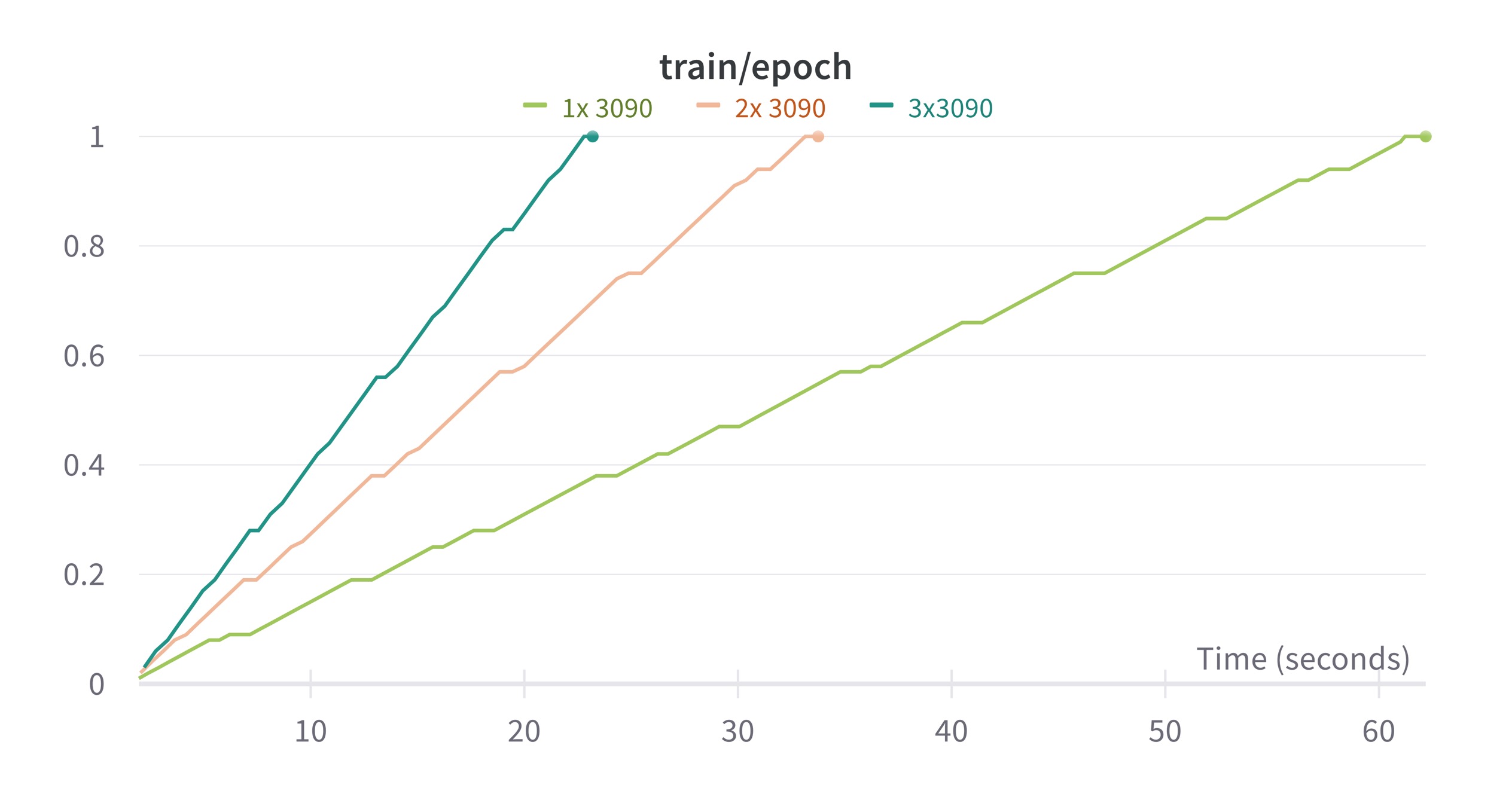
now it makes sense, thank you! |
add tgs metrics for
trainer. the motivation is that: currentspeed_metricsonly considertrain_samples_per_second. but the length of each example is not the same(especaillycutting_offincrease). this pr introducetgsmetrics, which taketokensinto considerations.