contribute_data
For this hackathon, we are adding datasets in two parts:
- suggesting a dataset
- making suggested datasets available via the Hugging Face Datasets Hub.
It is not required to be involved in both parts of this for each dataset. For example, you can suggest a dataset and not add it, or you could make available a dataset you didn't initially suggest.
The first way in which you can get involved in the hackathon is by suggesting datasets that you think would make a good candidate for inclusion in the Hugging Face Hub.
To do this, the overall steps are:
- Check that the dataset isn't already in the Hub
- Check that the dataset isn't already being tracked as part of this hackathon
- Decide whether the dataset is suitable for sharing.
- Create an issue for the dataset
The primary focus of the Hugging Face hub is machine learning datasets. This means that data should have some existing or potential relevance to machine learning.
There are a few different categories of data that would be particularly useful for sharing:
-
Annotated datasets. These datasets will have some labels that can be used to evaluate or train machine learning models. For example, a dataset consisting of newspaper articles with a label for the sentiment. These don't necessarily need to have been made explicitly for the purpose of training machine learning models. For example, datasets annotated through crowdsourcing tasks may be usefully adapted for machine learning.
-
Larger text datasets could be used for training large language models.
-
Large image collections that could be used for pre-training computer vision models
Not all potential datasets will fall into one of these categories neatly. If you have a dataset that doesn't fit one of these boxes but it could still be of interest, feel free to suggest it.
For this hackathon, we are using GitHub issues to propose new datasets. To open an issue, you will need a GitHub account if you don't already have an account, please singup first.
You can check the project board for an overview of datasets that are already submitted as part of the hackathon.
To suggest a dataset for inclusion in the hackathon, use the add dataset issue template. This issue template includes a basic form that captures some important information about the dataset.
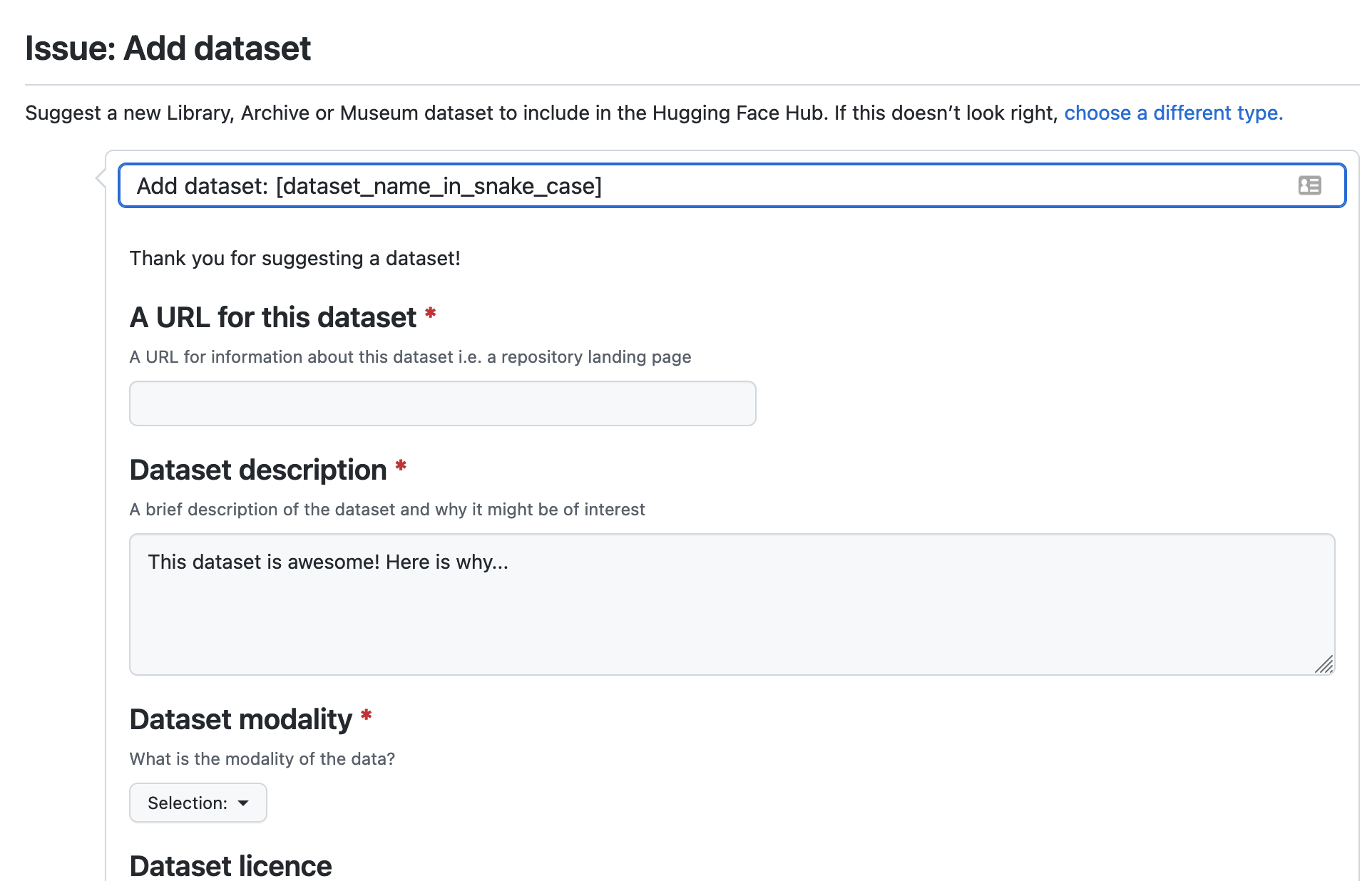
When you submit a candidate dataset through this issue template, it will be assigned the tag candidate-dataset..
We are tracking progress in adding new datasets via a project board
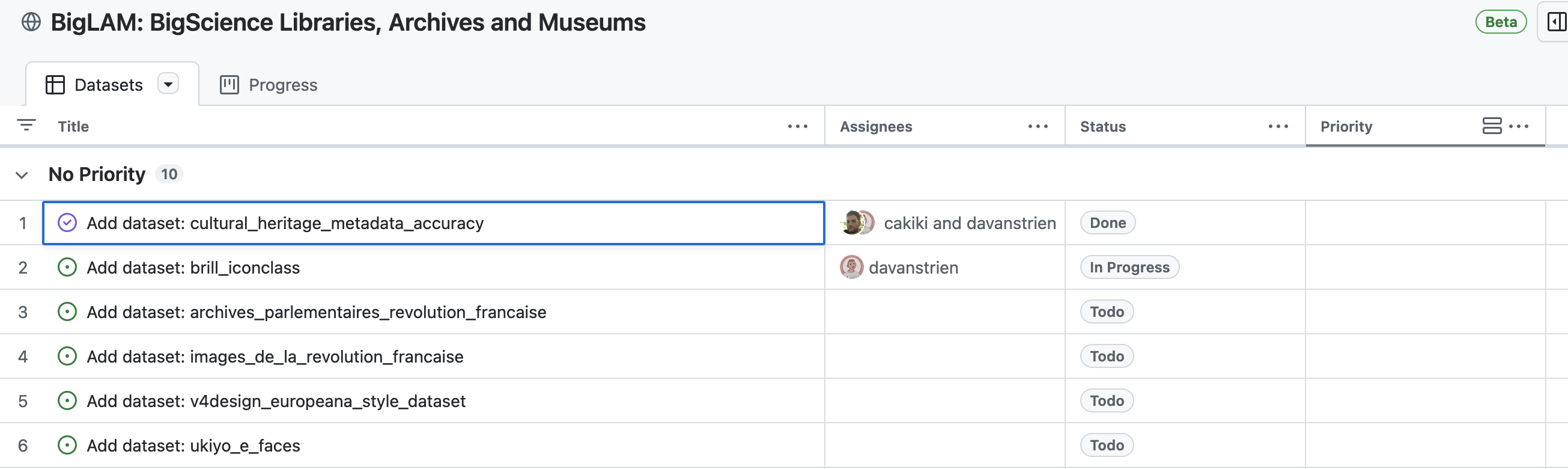
Before we move your suggest dataset to this project board one of the organizers will check if this dataset is suitable for sharing and clarify any issues. Once this is done it will be moved to the project board.
If you need some inspiration on where to look for suitable datasets, you can check out this discussion thread which points to some possible places you might discover potential datasets for inclusion.
You can also contribute to making data available via the Hugging Face Hub. The overall steps for doing this are:
- "claim" the dataset from the project board
- make the data available via the Hub. The two main ways of doing this are:
- directly sharing the files via the Hub
- writing a dataset script
- documenting the dataset
- requesting a review of your dataset
The following sections discuss these steps in more detail.
To add datasets to the LAM org, you will need to become a member:
- Make sure you have an account for Hugging Face. If you don't, you will need to join
- Request to join the biglam organization. We'll use this as the initial place to collect datasets.
- Decide on which dataset you want to work on from the project board
- If there isn't yet an issue for a dataset you want to add, you should first create an issue for it (see steps above). This is so we can track datasets that are in progress more easily and avoid multiple people working on the same datasets.
- Assign yourself to this dataset. This lets other people know you are working on this dataset. You can do this by commenting
#self-assignin the issue for that dataset.
There are a few different ways of making datasets available via the Hugging Face Hub. The best approach will depend on the dataset you are adding.
The datasets library has support for many file types out of the box. If your dataset is one of these formats, the easiest way to share this data is to upload the files directly. The supported formats include CSV, JSON, JSON lines, text lines, and Parquet.
You can find further guidance on sharing data in this way in the datasets documentation
The steps for this process:
- Make sure you have joined the biglam organization on the Hugging Face Hub
- Create a repository for the dataset under the biglam organization choosing a name that describes the dataset clearly (usually this will come from the original issue).
- Upload the files:
- For smaller files, it is often possible to directly upload via the browser interface
- For larger files, it is recommended to clone the repository and then use
git-lfsto upload the files. - You should consider compressing files before upload, particularly if they are very large. For example
*json.gzrather than.json - If you have many files you may also want to compress them inside a Zip directory. Zip has the advantage that it supports random access so it's possible for the datasets library to directly stream from zipped archives.
- Once you have uploaded your dataset to the hub, it's a good idea to test that everything loads correctly
The steps for doing this are covered more fully in the docs
You can find a video walking through the steps above:

There are some situations where you may not want to share files directly inside the Hugging Face Hub. These include:
- When data is not in a standard format and needs some processing to prepare it
- When you want to provide different 'configurations' for loading your data, for example, allows loading only a subset of the data.
- When the data is already available in a different repository, and you want to use that as the source for loading data.
Writing a dataset script is outlined in the datasets library documentation. For the datasets for this hackathon, we will create a repository under the hackathon organization and upload our scripts there.
The steps for doing this are as follows:
- Make sure you have joined the biglam organization on the Hugging Face Hub
- Create a repository for the dataset under the biglam organization choosing a name that describes the dataset clearly (usually this will come from the original issue).
- Create your data loading script. It is usually easier to develop this on a local machine so you can test the script as you work on it. You should make sure you name the dataset script the same name as the repository you created. This is so that the datasets library will correctly load data from this repository. For example, if you have a repository
biglam/metadata_quality, you should name the dataset loading scriptmetadata_quality.py - Upload your dataset script to the repository you just created:
- You can directly upload the script via the browser interface
- You can also clone the repository and then use
git push
- Once you have uploaded your dataset to the hub, it's a good idea to test that everything loads correctly
The steps for doing this are covered more fully in the docs: Create a dataset loading script
It can also be helpful to look at other scripts to understand better how to structure your dataset script. Some examples are listed below:
Example data loading scripts
- CSV https://github.com/huggingface/datasets/blob/master/datasets/amazon_polarity/amazon_polarity.py
- Text: https://github.com/huggingface/datasets/blob/master/datasets/conll2003/conll2003.py
- XML: https://github.com/huggingface/datasets/blob/master/datasets/bnl_newspapers/bnl_newspapers.py
- Image: https://huggingface.co/datasets/cats_vs_dogs/blob/main/cats_vs_dogs.py
It can be beneficial to make large datasets streamable. This allows someone to work with the data even if it is too large to fit onto their machine. For some datasets, it is pretty easy to make them streamable, but for others, it can be a bit more tricky. If you get stuck with this, feel free to ask for help in the issue tracking the dataset you are working on.
It is important to document your dataset as part of making it available via the hub. This documentation makes it easier for others to understand what the dataset includes, how it was created, and its strengths and weaknesses. We suggest at a minimum adding the following information to the documentation for a dataset:
- the source of the dataset
- a description of the tasks it could be (potentially) used for
- any important biases or limitations
Please see the contributing documentation page for more discussion of how to create documentation for your dataset.
Once you have made the dataset you are working on available via the Hub and added some documentation you should ask for a review. You can do this by commenting #ready-for-review on your issue. This will flag that you are ready for someone to take a look at your work. It is helpful if you provide a link to your dataset in a comment and also give a brief explanation of any particular choices you made in how you added the dataset.
Once your dataset has been reviewed and tested, it's a good idea to let other people know it's available. One way of doing this is on Twitter. We'll keep an eye out for the #BigLAM hashtag for any datasets shared on Twitter 😀