contribute_documentation
A goal of this hackathon is to add more data to the Hub. However, we also want to ensure we have done an excellent job documenting this data. This documentation can be developed as part of making a dataset available via Hub but is also something you can do independently of adding data to the Hub.
Documentation and metadata are essential (as anyone working in a GLAM institution will know). There is a growing recognition that datasets being used for training machine learning purposes should be documented. This documentation should communicate the strengths and weaknesses.
Dataset cards are one way we can document our datasets more effectively.
Dataset cards offer a framework for this documentation. This guidance on writing dataset cards is a valuable starting point. Instead of repeating this guidance, the below highlights a few things which may be particularly relevant for documenting Library, Archive, and Museum datasets.
The user of a dataset may be able to find some information about a dataset without any additional context beyond having the data itself. For example, it’s possible to count the number of rows in a CSV file or calculate the relative frequencies of different labels in a dataset.
However, it can be difficult for someone to work out other information without external background knowledge. For example, if a dataset has been generated by sampling a larger dataset, it might not be immediately apparent what the sampling approach was from the annotated dataset alone. Adding contextual information about how a dataset was created can support the responsible use of data for machine learning purposes.
There is often information known to the Library, Archive, and Museum staff involved in creating a dataset that might not be obvious to end users of that dataset. This information includes:
- Criteria for digitizing material for collection
- Annotation guideless for annotated data
- Limitations to the source collection, for example, if your institution doesn’t collect certain types of material (especially if this might not be obvious to an external user)
- (Systematic) gaps in metadata associated with a collection
Some of this knowledge may already be available via existing documentation. Publications associated with a dataset may also give additional context to its construction. However, there may be other knowledge about a dataset and its structure that only you and your colleagues are familiar with. Documenting this is a super valuable contribution to a Dataset cards.
Alongside Dataset cards, the Hub also supports other forms of metadata that can be useful for people to understand a dataset better. This metadata includes the supported tasks, the language, and the source of any annotations for the dataset. You will often add this information when creating a Dataset card, but you may wish to improve on the metadata you or others have created later on. The HuggingFace Dataset Tagger application is a useful tool for generating these tags.
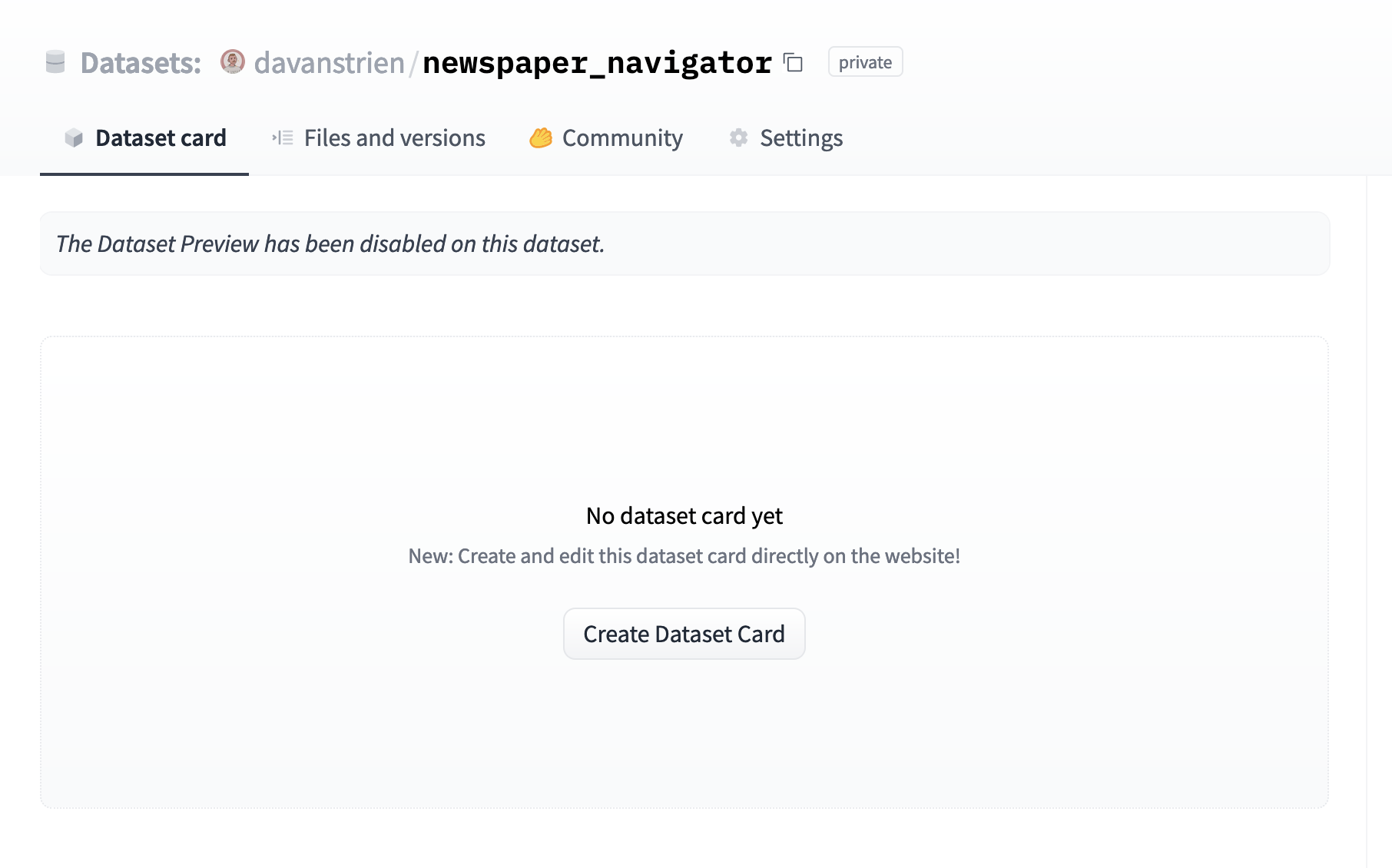
You may work on documentation as part of the process of uploading datasets to the Hub, or it may be something you work on independently. For a dataset, without a Dataset Card, you will see the option to create one.
Dataset (and model) repostiroie on Hugging Face Hub has a community tab that allows you to open pull requests (or start discussions).

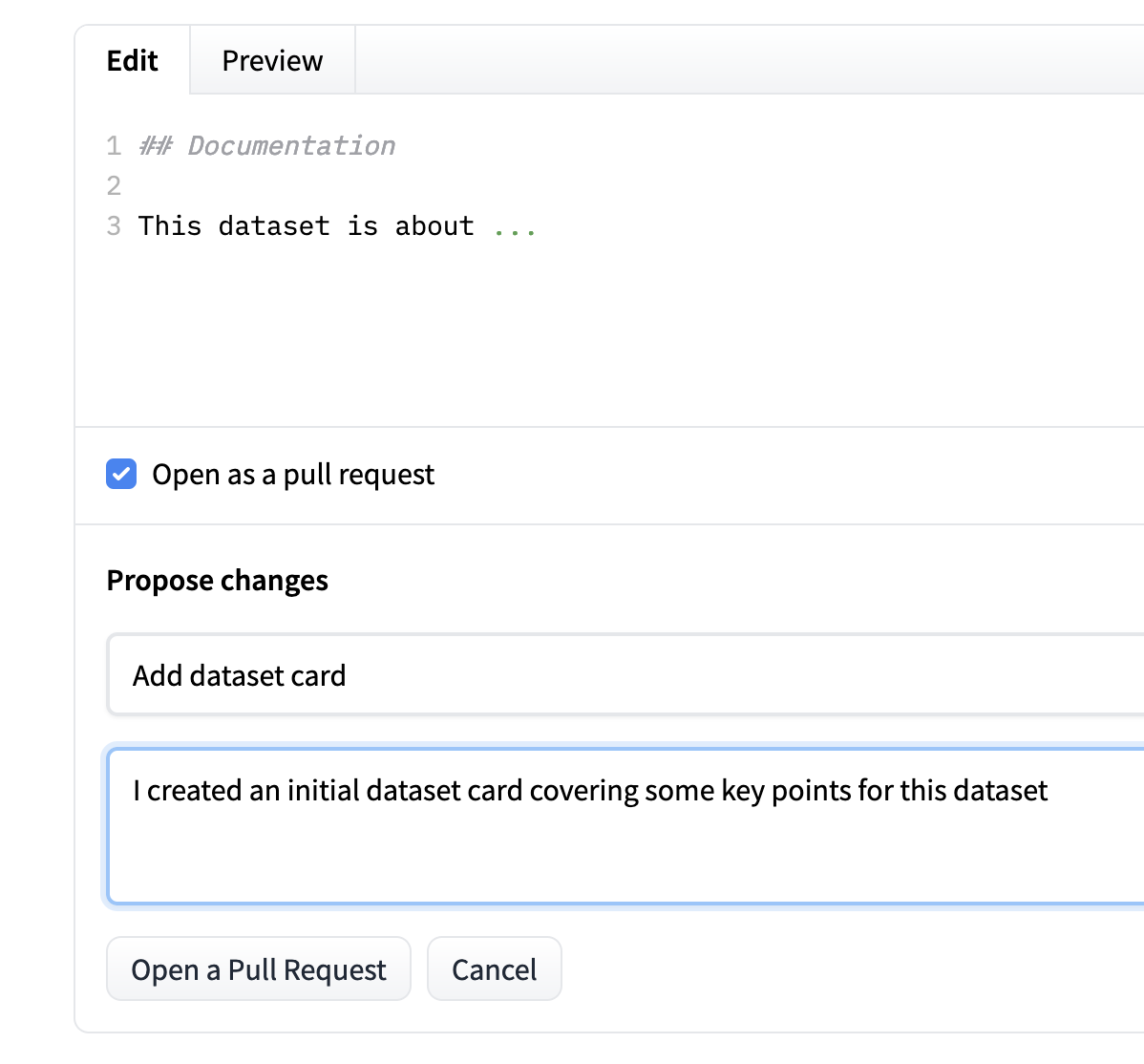
If you want to make a suggested addition or change to some of the documentation for a dataset it's suggested to use a pull request to propose this change.