[pull] master from apache:master #15
Merged
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
… coverage ### What changes were proposed in this pull request? This PR aims to add explicit Yunikorn queue submission test coverage instead of implicit assignment by admission controller. ### Why are the changes needed? - To provide a proper test coverage. - To prevent the side effect of YuniKorn admission controller which overrides all Spark's scheduler settings by default (if we do not edit the rule explicitly). This breaks Apache Spark's default scheduler K8s IT test coverage. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manually run the CI and check the YuniKorn queue UI. ``` $ build/sbt -Psparkr -Pkubernetes -Pkubernetes-integration-tests -Dspark.kubernetes.test.deployMode=docker-desktop "kubernetes-integration-tests/test" -Dtest.exclude.tags=minikube,local,decom -Dtest.default.exclude.tags= ``` <img width="1197" alt="Screen Shot 2022-09-14 at 2 07 38 AM" src="https://user-images.githubusercontent.com/9700541/190112005-5863bdd3-2e43-4ec7-b34b-a286d1a7c95e.png"> Closes #37877 from dongjoon-hyun/SPARK-40423. Authored-by: Dongjoon Hyun <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]>
{kind=link}
### What changes were proposed in this pull request? The main change of this pr as follows: - Upgrade `org.scalatestplus:selenium` from `org.scalatestplus:selenium-3-141:3.2.10.0` to `org.scalatestplus:selenium-4-2:3.2.13.0` and upgrade selenium-java from `3.141.59` to `4.2.2`, `htmlunit-driver` from `2.62.0` to `3.62.0` - okio upgrade from `1.14.0` to `1.15.0` due to both selenium-java and kubernetes-client depends on okio 1.15.0 and maven's nearby choice has also changed from 1.14.0 to 1.15.0 ### Why are the changes needed? Use the same version as other `org.scalatestplus` series dependencies, the release notes as follows: - https://github.com/scalatest/scalatestplus-selenium/releases/tag/release-3.2.11.0-for-selenium-4.1 - https://github.com/scalatest/scalatestplus-selenium/releases/tag/release-3.2.12.0-for-selenium-4.1 - https://github.com/scalatest/scalatestplus-selenium/releases/tag/release-3.2.12.1-for-selenium-4.1 - https://github.com/scalatest/scalatestplus-selenium/releases/tag/release-3.2.13.0-for-selenium-4.2 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass GitHub Actions - Manual test: - ChromeUISeleniumSuite ``` build/sbt -Dguava.version=31.1-jre -Dspark.test.webdriver.chrome.driver=/path/to/chromedriver -Dtest.default.exclude.tags="" -Phive -Phive-thriftserver "core/testOnly org.apache.spark.ui.ChromeUISeleniumSuite" ``` ``` [info] ChromeUISeleniumSuite: Starting ChromeDriver 105.0.5195.52 (412c95e518836d8a7d97250d62b29c2ae6a26a85-refs/branch-heads/5195{#853}) on port 53917 Only local connections are allowed. Please see https://chromedriver.chromium.org/security-considerations for suggestions on keeping ChromeDriver safe. ChromeDriver was started successfully. [info] - SPARK-31534: text for tooltip should be escaped (4 seconds, 447 milliseconds) [info] - SPARK-31882: Link URL for Stage DAGs should not depend on paged table. (841 milliseconds) [info] - SPARK-31886: Color barrier execution mode RDD correctly (297 milliseconds) [info] - Search text for paged tables should not be saved (1 second, 676 milliseconds) [info] Run completed in 11 seconds, 819 milliseconds. [info] Total number of tests run: 4 [info] Suites: completed 1, aborted 0 [info] Tests: succeeded 4, failed 0, canceled 0, ignored 0, pending 0 [info] All tests passed. [success] Total time: 25 s, completed 2022-9-14 20:12:28 ``` - ChromeUIHistoryServerSuite ``` build/sbt -Dguava.version=31.1-jre -Dspark.test.webdriver.chrome.driver=/path/to/chromedriver -Dtest.default.exclude.tags="" -Phive -Phive-thriftserver "core/testOnly org.apache.spark.deploy.history.ChromeUIHistoryServerSuite" ``` ``` [info] ChromeUIHistoryServerSuite: Starting ChromeDriver 105.0.5195.52 (412c95e518836d8a7d97250d62b29c2ae6a26a85-refs/branch-heads/5195{#853}) on port 58567 Only local connections are allowed. Please see https://chromedriver.chromium.org/security-considerations for suggestions on keeping ChromeDriver safe. ChromeDriver was started successfully. [info] - ajax rendered relative links are prefixed with uiRoot (spark.ui.proxyBase) (2 seconds, 416 milliseconds) [info] Run completed in 8 seconds, 936 milliseconds. [info] Total number of tests run: 1 [info] Suites: completed 1, aborted 0 [info] Tests: succeeded 1, failed 0, canceled 0, ignored 0, pending 0 [info] All tests passed. [success] Total time: 30 s, completed 2022-9-14 20:11:34 ``` Closes #37868 from LuciferYang/SPARK-40397. Authored-by: yangjie01 <[email protected]> Signed-off-by: Kousuke Saruta <[email protected]>
…antile in Rolling/RollingGroupby/Expanding/ExpandingGroupby ### What changes were proposed in this pull request? Implement quantile in Rolling/RollingGroupby/Expanding/ExpandingGroupby ### Why are the changes needed? Improve PS api coverage ```python >>> s = ps.Series([4, 3, 5, 2, 6]) >>> s.rolling(2).quantile(0.5) 0 NaN 1 3.0 2 3.0 3 2.0 4 2.0 dtype: float64 >>> s = ps.Series([2, 2, 3, 3, 3, 4, 4, 4, 4, 5, 5]) >>> s.groupby(s).rolling(3).quantile(0.5).sort_index() 2 0 NaN 1 NaN 3 2 NaN 3 NaN 4 3.0 4 5 NaN 6 NaN 7 4.0 8 4.0 5 9 NaN 10 NaN dtype: float64 >>> s = ps.Series([1, 2, 3, 4]) >>> s.expanding(2).quantile(0.5) 0 NaN 1 1.0 2 2.0 3 2.0 dtype: float64 >>> s = ps.Series([2, 2, 3, 3, 3, 4, 4, 4, 4, 5, 5]) >>> s.groupby(s).expanding(3).quantile(0.5).sort_index() 2 0 NaN 1 NaN 3 2 NaN 3 NaN 4 3.0 4 5 NaN 6 NaN 7 4.0 8 4.0 5 9 NaN 10 NaN dtype: float64 ``` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? CI passed Closes #37836 from Yikun/SPARK-40339. Authored-by: Yikun Jiang <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]>
### What changes were proposed in this pull request? In the PR, I propose to change the `SparkThrowable` interface: 1. Return a map of parameters names to their values from `getMessageParameters()` 2. Remove `getParameterNames()` because the names can be retrieved from `getMessageParameters()`. ### Why are the changes needed? To simplifies implementation and improve code maintenance. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? By running affected test suites: ``` $ build/sbt "core/testOnly *SparkThrowableSuite" $ build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite" ``` Closes #37871 from MaxGekk/getMessageParameters-map. Authored-by: Max Gekk <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]>
…port missing values and `min_periods` ### What changes were proposed in this pull request? refactor `spearman` correlation in `DataFrame.corr` to: 1. support missing values; 2. add parameter min_periods; 3. enable arrow execution since no longer depend on VectorUDT; 4. support lazy evaluation; ### Why are the changes needed? to make its behavior same as Pandas ### Does this PR introduce _any_ user-facing change? yes, API change, new parameter supported ### How was this patch tested? added UT Closes #37874 from zhengruifeng/ps_df_spearman. Authored-by: Ruifeng Zheng <[email protected]> Signed-off-by: Ruifeng Zheng <[email protected]>
…and Expanding.quantile into PySpark documentation ### What changes were proposed in this pull request? This PR adds `Rolling.quantile` and `Expanding.quantile` into documentation. ### Why are the changes needed? To show the documentation about the new features to end users. ### Does this PR introduce _any_ user-facing change? No to end users because the original PR is not released yet. ### How was this patch tested? CI in this PR should test it out. Closes #37890 from HyukjinKwon/followup-window. Authored-by: Hyukjin Kwon <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]>
…d column is in the output ### What changes were proposed in this pull request? Only set `KeyGroupedPartitioning` when the referenced column is in the output ### Why are the changes needed? bug fixing ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? new test Closes #37886 from huaxingao/keyGroupedPartitioning. Authored-by: huaxingao <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]>
### What changes were proposed in this pull request? In the PR, I propose to use error classes in the case of type check failure in the `CAST` expression. ### Why are the changes needed? Migration onto error classes unifies Spark SQL error messages, and improves search-ability of errors. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? By running the modified test suites: ``` $ build/sbt "test:testOnly *CastWithAnsiOnSuite" $ build/sbt "test:testOnly *DatasetSuite" $ build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite -- -z cast.sql" ``` Closes #37869 from MaxGekk/datatype-mismatch-in-cast. Authored-by: Max Gekk <[email protected]> Signed-off-by: Max Gekk <[email protected]>
… related doc ### What changes were proposed in this pull request? Fix wrong reference and content in PS windows related doc: - Add `pyspark.pandas.` for window function doc - Change `pandas_on_spark.DataFrame` to `pyspark.pandas.DataFrame` to make sure link generate correctly. - Fix `Returns` and `See Also` for `Rolling.count` - Add ewm doc for `Dataframe` and `series` ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? ``` cd ~/spark/python/docs make html ```  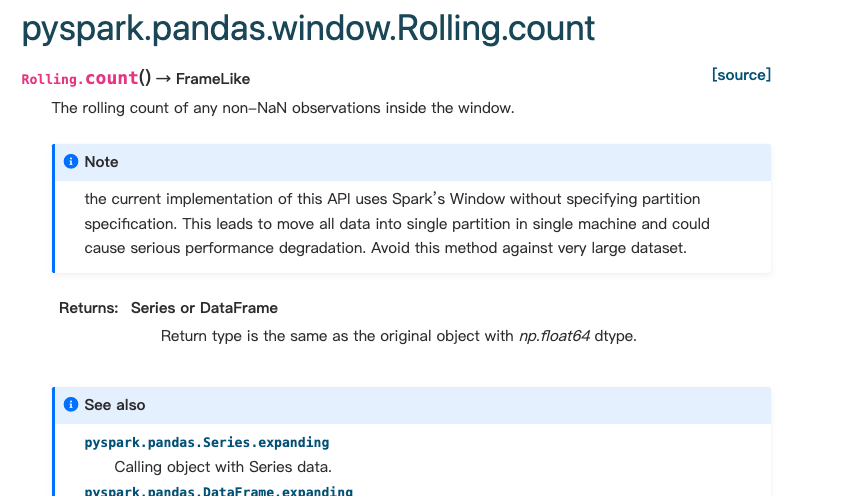  Closes #37895 from Yikun/add-doc. Authored-by: Yikun Jiang <[email protected]> Signed-off-by: Ruifeng Zheng <[email protected]>
{kind=link}
{kind=link}
{kind=link}
…ickled PySpark Row to JVM Row ### What changes were proposed in this pull request? This PR adds toJVMRow in PythonSQLUtils to convert pickled PySpark Row to JVM Row. Co-authored with HyukjinKwon . This is a breakdown PR of #37863. ### Why are the changes needed? This change will be leveraged in [SPARK-40434](https://issues.apache.org/jira/browse/SPARK-40434). ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? N/A. We will make sure test suites are constructed via E2E manner under [SPARK-40431](https://issues.apache.org/jira/browse/SPARK-40431). Closes #37891 from HeartSaVioR/SPARK-40433. Lead-authored-by: Jungtaek Lim <[email protected]> Co-authored-by: Hyukjin Kwon <[email protected]> Signed-off-by: Jungtaek Lim <[email protected]>
### What changes were proposed in this pull request? This PR used to improve the implementation of Spark `Decimal`. The improvement points are as follows: 1. Use `toJavaBigDecimal` instead of `toBigDecimal.bigDecimal` 2. Extract `longVal / POW_10(_scale)` as a new method `def actualLongVal: Long` 3. Remove `BIG_DEC_ZERO` and use `decimalVal.signum` to judge whether or not equals zero. 4. Use `<` instead of `compare`. 5. Correct some code style. ### Why are the changes needed? Improve the implementation of Spark Decimal ### Does this PR introduce _any_ user-facing change? 'No'. Just update the inner implementation. ### How was this patch tested? N/A Closes #37830 from beliefer/SPARK-40387. Authored-by: Jiaan Geng <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
wangyum
pushed a commit
that referenced
this pull request
Jan 9, 2023
Signed-off-by: Yuan Zhou <[email protected]> Signed-off-by: Yuan Zhou <[email protected]>
wangyum
pushed a commit
that referenced
this pull request
Apr 4, 2023
Signed-off-by: Yuan Zhou <[email protected]> Signed-off-by: Yuan Zhou <[email protected]>
pull bot
pushed a commit
that referenced
this pull request
Apr 22, 2023
…onnect ### What changes were proposed in this pull request? Implement Arrow-optimized Python UDFs in Spark Connect. Please see apache#39384 for motivation and performance improvements of Arrow-optimized Python UDFs. ### Why are the changes needed? Parity with vanilla PySpark. ### Does this PR introduce _any_ user-facing change? Yes. In Spark Connect Python Client, users can: 1. Set `useArrow` parameter True to enable Arrow optimization for a specific Python UDF. ```sh >>> df = spark.range(2) >>> df.select(udf(lambda x : x + 1, useArrow=True)('id')).show() +------------+ |<lambda>(id)| +------------+ | 1| | 2| +------------+ # ArrowEvalPython indicates Arrow optimization >>> df.select(udf(lambda x : x + 1, useArrow=True)('id')).explain() == Physical Plan == *(2) Project [pythonUDF0#18 AS <lambda>(id)#16] +- ArrowEvalPython [<lambda>(id#14L)#15], [pythonUDF0#18], 200 +- *(1) Range (0, 2, step=1, splits=1) ``` 2. Enable `spark.sql.execution.pythonUDF.arrow.enabled` Spark Conf to make all Python UDFs Arrow-optimized. ```sh >>> spark.conf.set("spark.sql.execution.pythonUDF.arrow.enabled", True) >>> df.select(udf(lambda x : x + 1)('id')).show() +------------+ |<lambda>(id)| +------------+ | 1| | 2| +------------+ # ArrowEvalPython indicates Arrow optimization >>> df.select(udf(lambda x : x + 1)('id')).explain() == Physical Plan == *(2) Project [pythonUDF0#30 AS <lambda>(id)#28] +- ArrowEvalPython [<lambda>(id#26L)#27], [pythonUDF0#30], 200 +- *(1) Range (0, 2, step=1, splits=1) ``` ### How was this patch tested? Parity unit tests. Closes apache#40725 from xinrong-meng/connect_arrow_py_udf. Authored-by: Xinrong Meng <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]>
pull bot
pushed a commit
that referenced
this pull request
Jul 3, 2025
…pressions in `buildAggExprList` ### What changes were proposed in this pull request? Trim aliases before matching Sort/Having/Filter expressions with semantically equal expression from the Aggregate below in `buildAggExprList` ### Why are the changes needed? For a query like: ``` SELECT course, year, GROUPING(course) FROM courseSales GROUP BY CUBE(course, year) ORDER BY GROUPING(course) ``` Plan after `ResolveReferences` and before `ResolveAggregateFunctions` looks like: ``` !Sort [cast((shiftright(tempresolvedcolumn(spark_grouping_id#18L, spark_grouping_id, false), 1) & 1) as tinyint) AS grouping(course)#22 ASC NULLS FIRST], true +- Aggregate [course#19, year#20, spark_grouping_id#18L], [course#19, year#20, cast((shiftright(spark_grouping_id#18L, 1) & 1) as tinyint) AS grouping(course)#21 AS grouping(course)#15] .... ``` Because aggregate list has `Alias(Alias(cast((shiftright(spark_grouping_id#18L, 1) & 1) as tinyint))` expression from `SortOrder` won't get matched as semantically equal and it will result in adding an unnecessary `Project`. By stripping inner aliases from aggregate list (that are going to get removed anyways in `CleanupAliases`) we can match `SortOrder` expression and resolve it as `grouping(course)#15` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests ### Was this patch authored or co-authored using generative AI tooling? No Closes apache#51339 from mihailotim-db/mihailotim-db/fix_inner_aliases_semi_structured. Authored-by: Mihailo Timotic <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
pull bot
pushed a commit
that referenced
this pull request
Aug 19, 2025
…onicalized expressions
### What changes were proposed in this pull request?
Make PullOutNonDeterministic use canonicalized expressions to dedup group and aggregate expressions. This affects pyspark udfs in particular. Example:
```
from pyspark.sql.functions import col, avg, udf
pythonUDF = udf(lambda x: x).asNondeterministic()
spark.range(10)\
.selectExpr("id", "id % 3 as value")\
.groupBy(pythonUDF(col("value")))\
.agg(avg("id"), pythonUDF(col("value")))\
.explain(extended=True)
```
Currently results in a plan like this:
```
Aggregate [_nondeterministic#15](#15), [_nondeterministic#15 AS dummyNondeterministicUDF(value)#12, avg(id#0L) AS avg(id)#13, dummyNondeterministicUDF(value#6L)#8 AS dummyNondeterministicUDF(value)#14](#15%20AS%20dummyNondeterministicUDF(value)#12,%20avg(id#0L)%20AS%20avg(id)#13,%20dummyNondeterministicUDF(value#6L)#8%20AS%20dummyNondeterministicUDF(value)#14)
+- Project [id#0L, value#6L, dummyNondeterministicUDF(value#6L)#7 AS _nondeterministic#15](#0L,%20value#6L,%20dummyNondeterministicUDF(value#6L)#7%20AS%20_nondeterministic#15)
+- Project [id#0L, (id#0L % cast(3 as bigint)) AS value#6L](#0L,%20(id#0L%20%%20cast(3%20as%20bigint))%20AS%20value#6L)
+- Range (0, 10, step=1, splits=Some(2))
```
and then it throws:
```
[[MISSING_AGGREGATION] The non-aggregating expression "value" is based on columns which are not participating in the GROUP BY clause. Add the columns or the expression to the GROUP BY, aggregate the expression, or use "any_value(value)" if you do not care which of the values within a group is returned. SQLSTATE: 42803
```
- how canonicalized fixes this:
- nondeterministic PythonUDF expressions always have distinct resultIds per udf
- The fix is to canonicalize the expressions when matching. Canonicalized means that we're setting the resultIds to -1, allowing us to dedup the PythonUDF expressions.
- for deterministic UDFs, this rule does not apply and "Post Analysis" batch extracts and deduplicates the expressions, as expected
### Why are the changes needed?
- the output of the query with the fix applied still makes sense - the nondeterministic UDF is invoked only once, in the project.
### Does this PR introduce _any_ user-facing change?
Yes, it's additive, it enables queries to run that previously threw errors.
### How was this patch tested?
- added unit test
### Was this patch authored or co-authored using generative AI tooling?
No
Closes apache#52061 from benrobby/adhoc-fix-pull-out-nondeterministic.
Authored-by: Ben Hurdelhey <[email protected]>
Signed-off-by: Wenchen Fan <[email protected]>
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
9 participants
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
See Commits and Changes for more details.
Created by pull[bot]
pull[bot]
Can you help keep this open source service alive? 💖 Please sponsor : )