Heterogenous Architectures
-
While the CPU is designed to excel at executing a sequence of operations, called a thread, as fast as possible, it can only execute a few tens of these threads in parallel.
-
GPUs however are designed to excel at executing thousands of them in parallel, amortizing the slower single-thread performance to achieve greater throughput.
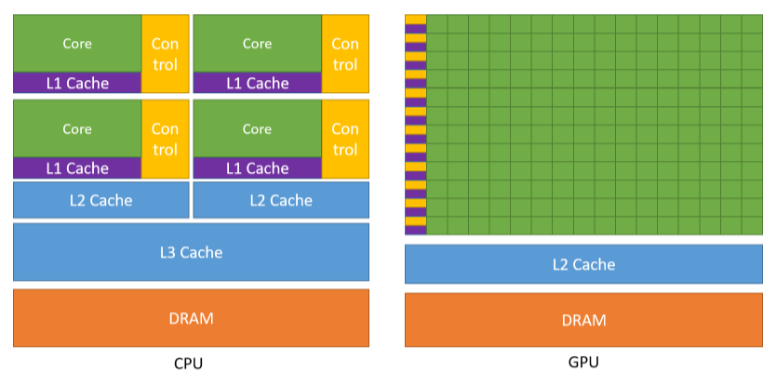
In HPC, its common practice to offload expensive computations to vectorized accelerators such as GPUs as a means for fine-grained parallelism. Machines that contain at least one accelerator, such as Sierra or Summit are considered to have heterogenous (CPU-GPU) architectures, in that they contain different types of computational units. Heterogeneous memory systems provide the potential benefit of significantly increasing system performance and reducing power consumption at the cost of complexity in their architectures.

- 'Graphics Processing Unit'
- Responsible for the computationally expensive task of generating and rendering images to the screen
- The initial idea of a GPU was to act as a secondary device to allow the CPU to offload this specialized rendering work. Because of this, GPUs had to be designed to perform many calculations very quickly in order to keep up with the stream of images needing to be displayed. For this reason, GPUs are designed to be highly parallel innately so that multiple parts of an image can be rendered at once, thus, reducing the total amount of time it took to render an image compared to the CPU. Today, GPU architectures enable GPUs to be utilized for a more generic workload than just rendering graphics. Offloading expensive computations such as machine learning, physics simulations, and linear algebra operations increase the performance of applications, as long as these computations are expensive enough to saturate all of the GPU cores.
GPUs are designed for processing massively parallel operations
- GPUs have more computational throughput and memory bandwith than CPUs
- computational throughput (measured in GFLOPS) implies many threads per core = more performance.
- Data processing transistors as opposed to data caching
CPUs are designed to reduce waiting for input time
- This means they are optimized for low latency
- memory caching transistors as opposed to data processing
In essence, a GPU does the same thing as CPU (e.g., add two numbers). However, GPUs have many more cores for processing expensive computations than the CPU, an should be used accordingly for parallel speed up.
One particular challenge that was mentioned in the previous section is optimizing data access patterns in CPU-GPU environments. This is because these devices store data quite differently, and the data structure layouts in GPU memory often lead to sub-optimal performance for programs designed with a CPU memory interface. In other words, application performance is highly sensitive to irregularity in memory access patterns.
NOTE: Kokkos solves this problem with execution spaces and memory spaces
In today’s high-performance computers, there is a wide range of diversity in system architectures that make it particularly challenging to exploit heterogenous machines fully for computational science. From this hardware diversity, numerous programming models have been built to target execution resources (e.g., the CPU/GPU) for specific machines. Consider the following standards for GPU programing models that are restricted to programming GPUs based upon the manufacturer of the GPU chip itself (e.g., NVIDIA, AMD, Intel, etc.). Additionally, these programming models are tied to their vendor-specific version of OpenMP5 for parallelism on the CPU.
| Standard GPU Programming Model | GPU Vendor | OpenMP Specification |
|---|---|---|
| CUDA | NVIDIA GPU Chips | NVIDIA's OpenMP5 |
| HIP | AMD GPU Chips | AMD's OpenMP5 |
| OpenCL or DPC++ | Intel GPU Chips | Intel's OpenMP5 |
Due to this lack of uniformity, its not quite clear how performance portable a program written for an AMD-based machine will be to another (e.g., an Intel-based machine). What is clear is that if you are use the standard programming model for a heterogenous NVIDIA-based machine and you want to run on an AMD-based machine, you will need to change to AMD's supported programming model. Changing programming models to run on different machines requires code to be rewritten per the specifications of the machine's respective programming model. Ultimately, this becomes a particular problem for large-scale HPC applications that on average consist of 300,000 - 600,000 lines of code. In other words, rewriting code is expensive.
Programming two execution targets (the CPU and the GPU) require a set of mechanisms for performance portability across the range of potential and final system designs. Kokkos is a shared memory programming model that emphasizes performance portability accross all modern HPC architectures. The Kokkos API allows developers to express parallelism that is able to compile and execute
- In Serial on the CPU
- In Parallel on the CPU
- In Parallel on the CPU and GPU
regardless of the manufacturer of either chip. Thus, this removes the need to refactor the source code itself, and enables HPC applications to run on theoretically any HPC machine.
Kokkos solves this by allowing the user to compile for parallelism on one or both execution targets
Heterogenous machines are rapidly increasing.
.png)

I performed this analysis by creating this simple Python script below.
import pandas as pd
# you can obtain whatever month/year you want from top500.org
df = pd.read_excel('TOP500data.xlsx', engine='openpyxl')
#store accelerator column data (it may be named differently) into pandas series
acc_series = df.Accelerator
#count homogenous machines vs heterogenous machines
cpuonly = acc_series.str.contains('None').sum()
if cpuonly>0:
print ("\n\nCPU Based Processors: ", cpuonly)
gpu_based = 500 - cpuonly #500 total machines in top500.org
print("\n\nGPU-Based Computers: ", gpu_based)